КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Направления развития суперскалярной архитектуры
|
|
|
|
Завершение выполнения команды
Работа с памятью
Для вычисления адреса памяти, как правило, требуется, по крайней мере, одно сложение. После вычисления адреса может понадобиться его преобразование в физический адрес, осуществляемое буфером трансляции адресов (TLB).
Проблемы конфликтов при доступе к разделяемому ресурсу - ячейкам памяти, по сути те же, что и при доступе к регистрам.
Завершающей фазой исполнения команды является фаза изменения состояния процессора в соответствии с выполненной командой. Назначение этой фазы - сохранение последовательной модели исполнения программы, при реальном параллельном выполнении отдельных команд и условном выполнении команд ветвления. Для изменения состояния процессора применяются два основных способа, причем оба основаны на использовании двух состояний: состояния, измененного в результате операции, и состояния, требуемого для восстановления.
При первом способе сохраняется состояние процессора в наборе контрольных точек или в буфере истории вычислений, которые, в случае необходимости, используются для восстановления состояния.
Второй способ предполагает рассмотрение логического (архитектурного) и физического состояния процессора. Физическое состояние изменяется немедленно по завершении очередной команды. Архитектурное состояние изменяется тогда, когда ясен результат условно выполненных команд. Для реализации этого способа используется переупорядочивающий буфер: результаты из буфера отправляются в файл архитектурных регистров и память.
В переупорядочивающем буфере для каждой команды содержится соответствующее ей значение счетчика команд и значения других регистров, которые необходимы для корректного обслуживания прерываний.
Основные компоненты суперскалярного микропроцессора: функциональные модули - выполнения операций с плавающей (FPU) и фиксированной (ALU) точкой, устройство загрузки/сохранения, файлы регистров, раздельная кэш-память команд и данных, а также вспомогательные модули, обеспечивающие динамическое планирование вычислительного процесса - устройство связи с кэш-памятью 2-го уровня, блок переупорядочивания команд и блок предварительной дешифрации.
Как уже отмечалось ранее, в суперскалярных процессорах предпринимается попытка в рамках модели последовательных программ реализовать параллельное исполнение команд этих программ. После извлечения последовательного потока команд между командами устанавливаются только действительно необходимые зависимости по данным. При этом сохраняется достаточно информации о порядке следования команд в исходной программе, чтобы сохранить их порядок при наступлении прерывания.
Типичный суперскалярный процессор выбирает команды и исследует их по мере выполнения. Исследование проводится с целью выявления и обработки команд перехода, идентификации типа команды для ее дальнейшего направления на соответствующий исполнительный блок или в буфер памяти. Выполняются также некоторые действия для смягчения зависимостей по данным, например переименование регистров. VLIW процессор возлагает на компилятор статическую реализацию тех функций, которые в суперскалярном процессоре выполняются динамически.
По крайней мере два обстоятельства ограничивают эффективность использования суперскалярных архитектур. Во-первых, есть ограничения на степень параллелизма на уровне команд, даже если применяется самая совершенная техника суперскалярных вычислений. Первое ограничение проистекает из условных переходов. Другое следует из того, что размер окна исполнения (число активных команд, могущих исполняться параллельно) ограничивает возможный присущий программе параллелизм, так как не рассматривается параллельное исполнение команд, находящихся на расстоянии, превышающем размер окна.
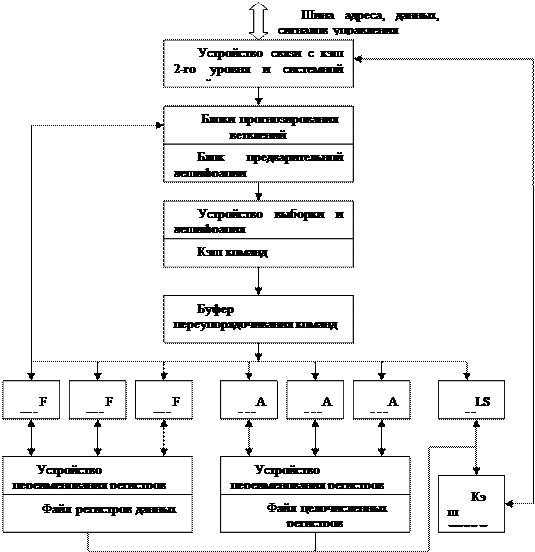 |
Структура суперскалярного микропроцессора
Во-вторых, сложность суперскалярного процессора возрастает как количество параллельно исполняемых команд и даже быстрее.
Вероятнее всего, что пределом распараллеливания при суперскалярной обработке является запуск одновременно на исполнение в каждом такте 7-8 команд.
Альтернатива суперскалярной обработке - длинное командное слово (VLIW). Использование этого метода предполагает задание в командном слове совокупности параллельно выполняемых команд. Подготовкой таких программ занимается компилятор.
Достоинства VLIW заключаются в следующем. Во-первых, компилятор может более эффектно исследовать зависимости между командами и выбирать параллельно исполняемые команды, чем это делает аппаратура суперскалярного процессора, ограниченная размером окна исполнения.
Во-вторых, VLIW процессор имеет более простое устройство управления и потенциально может иметь более высокую тактовую частоту.
Однако у VLIW процессоров есть серьезный фактор, снижающий их производительность. Это команды ветвления, зависящие от данных, значения которых становятся известны только в динамике вычислений. Окно исполнения VLIW-процессора, не может быть очень большим в виду отсутствия у компилятора информации о зависимостях, формируемых динамически, в процессе выполнения. Этот недостаток препятствует возможности переупорядочивания операций в VLIW процессоре. Например, статически не может быть гарантировано правильное выполнение операции загрузки в вызываемой функции параллельно с операцией запоминания в вызывающей функции (особенно, если вызываемая функция определена динамически). Кроме того, VLIW реализация требует большого размера памяти имен, многовходовых регистровых файлов, большого числа перекрестных связей. Возможен также останов, когда во время выполнения возникла ситуация, отличающаяся от состояния в момент генерации плана выполнения (например, во время выполнения произошло неудачное обращение в кэш).
Другим возможным подходом служит переход к мультипроцессорному исполнению, когда вводится несколько счетчиков команд. В этом случае речь идет о распараллеливающих компиляторах с языков высокого уровня.
Таким образом, суперскалярные микропроцессоры являются лидирующим продуктом микроэлектроники, и их производительность постоянно растет, но при использовании этих процессоров необходимо тщательно исследовать архитектурные приемы получения высокой производительности и проверять адекватность этих приемов проблемной области, для решения задач которой создается вычислительная система.
Дальнейшее повышение производительности микропроцессоров связывается в настоящее время со статическим и динамическим анализом кода с целью выявления резервов параллелизма уровня отдельных команд и программных сегментов с использованием информации, предоставляемой компилятором языка высокого уровня Исследования в данном направлении привели к разработке мультискалярной архитектуры процессоров, которые являются дальнейшим развитием суперскалярной архитектуры
В настоящее время работы в данном направлении находятся на стадии теоретического исследования и имитационного моделирования, однако, по видимому, уже в скором времени следует ожидать появления первых микропроцессоров, в полной мере использующих все преимущества, предоставляемые мультискалярной архитектурой. Поэтому основные моменты, связанные с данной архитектурой, будут рассмотрены ниже достаточно подробно.
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 291; Нарушение авторских прав?; Мы поможем в написании вашей работы!