КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Иерархическая структура памяти
|
|
|
|
Принцип совмещения операций академика С. А. Лебедева. Конвейер операций
Вернемся к схеме рабочего цикла (рис. 9.34) и рассмотрим совокупность этапов цикла для основных команд (основной вариант цикла). Если эти этапы выполняются последовательно во времени, то, суммируя обозначенные на рисунке продолжительности отдельных этапов, получаем время цикла
t посл = t 1 + t 2 + t 3 + t 4 + t 5
и производительность процессора, операций (команд)/с,
Pпосл = 1 / t посл = 1 / (t 1 + t 2 + t 3 + t 4 + t 5)
Во многих случаях последовательная процедура выполнения этапов цикла не обеспечивает требуемую производительность процессора.
Академик С. А. Лебедев в 1956 г. предложил повышать производительность, используя принцип совмещения во времени отдельных операций (этапов) рабочего цикла, и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операции в АЛУ и выборки из памяти следующей команды.
 Пусть рабочий цикл процессора состоит из k этапов, причем 1-й этап имеет продолжительность ti, тогда при последовательном выполнении этапов продолжительность процедуры
Пусть рабочий цикл процессора состоит из k этапов, причем 1-й этап имеет продолжительность ti, тогда при последовательном выполнении этапов продолжительность процедуры
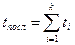 (*)
(*)
и общая производительность процессора, операций/с,
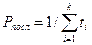 .
.
Скорость работы машины может быть увеличена, если для выполнения каждого этапа иметь отдельный аппаратурный блок и соединить эти блоки в обрабатывающую линию — конвейер операций (в данном случае конвейер команд) так, чтобы результат выполнения в данном блоке некоторого этапа передавался для реализации очередного этапа на следующий блок, и т. д. (рис. 9.35).
Синхронный конвейер операций. Если конвейер работает в принудительном темпе и для выполнения любого этапа выделено одно и то же время t T, (такт конвейера), то такой конвейер называется синхронным.
Разбиение процедуры на этапы и выбор длительности такта производятся согласно условиям
t T = max{ ti }, i = 1, …, k; (**)
ti + ti+ 1 > t T, i = 1, …, k. (***)
причем в силу цикличности рабочего процесса в последнем неравенстве принимаем tk+ 1 = t 1.
 Если для каких-либо смежных этапов второе условие не выполняется, то их следует объединить в один этап либо наиболее длинный этап разбить на несколько этапов. В последнем случае заново выбирается t T и вновь проверяется условие (**).
Если для каких-либо смежных этапов второе условие не выполняется, то их следует объединить в один этап либо наиболее длинный этап разбить на несколько этапов. В последнем случае заново выбирается t T и вновь проверяется условие (**).
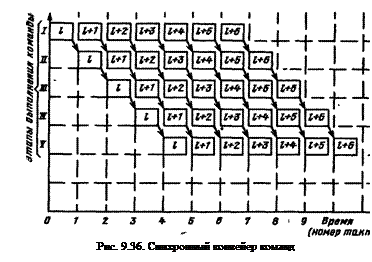
На рис. 9.36 показана временная диаграмма выполнения команд на 5-позиционном синхронном конвейере. Одинаковыми символами помечены разные этапы рабочего цикла одной и той же команды.
После того как все позиции конвейера окажутся заполненными, параллельно во времени обрабатывается столько команд, сколько в конвейере обрабатывающих блоков (позиций).
Конвейер характеризуется коэффициентом совмещения операций, равным числу одновременно выполняемых этапов обработки информации.
Номинальная производительность синхронного конвейера при его полной загрузке
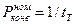
Найдем соотношение производительностей процессора при конвейерной обработке и при последовательном выполнении этапов рабочего цикла.
Из (*) и (**) имеем 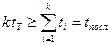 (****)
(****)
а из (*) и (***) получаем 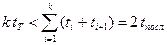 (*****)
(*****)
Из (****) и (*****) получаем 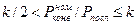 (******)
(******)
В действительности рост реальной производительности процессора окажется ниже из-за простоев (задержек) конвейера. В процедурах выполнения некоторых команд (например, команд пересылки данных) отдельные этапы общего рабочего цикла отсутствуют, и, следовательно, простаивают отдельные блоки конвейера. Для команды условного перехода по результату предыдущей операции выборка следующей команды должна быть задержана (конвейер простаивает несколько тактов), пока не будет сформирован признак результата (формируется на более позднем этапе) предыдущей операции.
Если pm — вероятность выборки команды, вызывающей задержку конвейера на m тактов (m = 1, 2,..., k), то действительная производительность конвейера
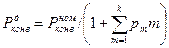
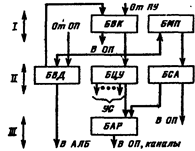 Рис. 9.37. Структура управляющего устройства процессора: БВК. — блок выборки команд; БМП — блок местной памяти; БВД — блок выборки данных; БЦУ — блок центрального управления; БСА — блок, сумматора адреса; БАР — блок адреса результата: АЛБ — арифметико-логический блок; ПУ — пульт управления; УП — управляющие сигналы
Рис. 9.37. Структура управляющего устройства процессора: БВК. — блок выборки команд; БМП — блок местной памяти; БВД — блок выборки данных; БЦУ — блок центрального управления; БСА — блок, сумматора адреса; БАР — блок адреса результата: АЛБ — арифметико-логический блок; ПУ — пульт управления; УП — управляющие сигналы
|
Асинхронный конвейер команд. При большой зависимости продолжительности выполнения процедур отдельных этапов от типа команды и вида операндов целесообразно применение асинхронного конвейера, в котором отсутствует единый такт работы его блоков, а информация с одного блока конвейера передается на следующий, когда данный блок закончит свою процедуру, а следующий полностью освободится от обработки предыдущей команды.
Управление передачей информации между соседними блоками в асинхронном конвейере осуществляется с помощью двух триггеров — готовности блока (сигнализирует о завершении операции в блоке) и освобождения последующего блока.
В качестве примера применения асинхронного конвейера команд может служить процессор ЭВМ ЕС-1050, в котором реализован конвейер, выполняющий одновременно три команды. Рабочий цикл выполнения команды разбит на три этапа: I — выборка очередной команды, II — формирование исполнительных адресов и выборка операндов, III — операция в АЛУ, формирование признака результата и запись результата в память.
Для каждого из указанных этапов выполнения команды имеется соответствующая аппаратура. Например, кроме сумматора АЛУ есть отдельный сумматор для формирования исполнительного адреса на этапе II. На рис. 9.37 представлена структура управляющего устройства с «жесткой» логикой процессора ЭВМ ЕС-1050, на которой показаны блоки, управляющие процедурами отдельных этапов выполнения команды.
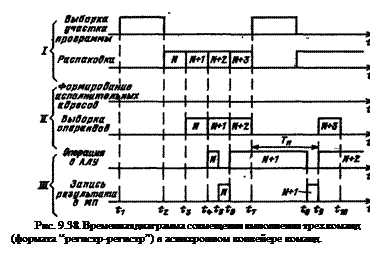 На рис. 9.38 показана временная диаграмма совмещения выполнения трех команд в ЭВМ ЕС-1050 Временная диаграмма построена для случая, когда выбираемый за одно обращение к памяти «участок программы» содержит четыре команды формата «регистр-регистр».
На рис. 9.38 показана временная диаграмма совмещения выполнения трех команд в ЭВМ ЕС-1050 Временная диаграмма построена для случая, когда выбираемый за одно обращение к памяти «участок программы» содержит четыре команды формата «регистр-регистр».
Этап I содержит две процедуры, выборку из ОП участка программы (8 байт) и распаковку участка — выделение из него очередной команды и размещение ее в регистре команды.
Этап II в общем случае включает в себя формирование исполнительных адресов (при выполнении команд формата “регистр-регистр” отсутствует) и выборку операндов.
Этап III состоит также из двух процедур: выполнения операций в АЛУ и записи результата в память.
Из диаграммы видно, что, начиная с момента времени t 4 выполняются одновременно три этапа цикла соответственно для трех команд. В приведенном примере с момента t 7 из-за большой длительности в команде N+ 1 операции в АЛУ приостанавливается работа блоков аппаратуры, соответствующих этапам I и II.
Арифметический конвейер. Выше был рассмотрен конвейер команд. Однако в целях повышения производительности машины принцип конвейерной обработки широко используется и в самих выполняющих содержательную обработку информации устройствах (АЛУ), которые строятся в виде арифметического конвейера, причем таких арифметических конвейерных линий может быть в процессоре несколько, в том числе и специализированных для определенных операций с данными Подобные операционные (арифметические) устройства часто называют магистральными.
Пусть операционное устройство должно вычислять некоторую функцию Ф от входных данных (выполнять некоторую операцию над входными данными). Можно функцию Ф представить в виде последовательности более простых подфункций
j1 ® j2 ® j3 ®... ® jk
причем такой, что результаты преобразования, выполняемые подфункцией ji, используются в качестве входных данных при вычислении подфункции ji+1, и если при этом для каждой подфункции иметь реализующую ее схемный блок, то получим арифметический конвейер, который может быть выполнен как синхронный или как асинхронный.
Приведенные выше элементы теории синхронного конвейера команд остаются в силе и для синхронного арифметического конвейера. Если tT — такт конвейера, то после полной загрузки он станет выдавать значения функции Ф через интервалы времени tT. Увеличение производительности процессора за счет использования арифметического конвейера можно оценить по (******).
Если арифметический конвейер используется для выполнения разных операций, то осложняется определение состава рабочих позиций (блоков) конвейера и может потребоваться настройка (диспетчеризация) с соответствующей коммутацией блоков конвейера на операцию, задаваемую текущей командой.
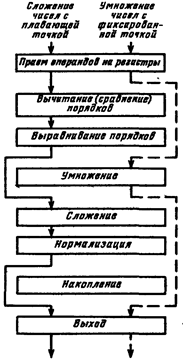
Рассмотрим в качестве примера использование арифметического конвейера для сложения двух векторов X+Y=Z, компонентами» которых являются числа, представленные в форме с плавающей точкой и в нормализованном виде.
Выделим в операции сложения чисел с плавающей точкой четыре этапа: 1) сравнение и определение разности порядков, 2) выравнивание порядков - сдвиг мантиссы числа с меньшим порядком на число разрядов, равное разности порядков; 3) сложение мантисс; 4) нормализация результата.
В арифметическом конвейере эти этапы выполняются отдельными блоками, образующими конвейер, по которому перемещаются операнды или промежуточные результаты операции По мере их перемещения в конвейер вводятся новые компоненты векторов.
Пусть времена, необходимые для выполнения этапов сложения чисел с плавающей точкой, есть t 1, t 2, t 3, t 4.
|
Рис.9.39 Пример настройки арифметического конвейера на выполнение различных операций
Следовательно, если не организовать конвейер и выполнять все этапы операции последовательно, то для получения компонента zi = xi + yi потребуется время T = t 1 + t 2 + t 3 + t 4.
В синхронном конвейере, как указывалось выше, продолжительность каждого этапа устанавливается по самому длинному из них, пусть в данном случае это t 3. Тогда, если конвейер заполнен, результаты сложения элементов векторов будут выдаваться через каждые промежутки времени t3, т. е. значительно быстрее, чем в случае отсутствия конвейерной обработки.
На рис. 9.39 в качестве примера представлена структура конвейерного (магистрального) АЛУ, соответствующего АЛУ известной в свое время ЭВМ ASC фирмы Texas Instruments, и показаны варианты коммутации блоков конвейера для выполнения разных операций, в данном случае сложения чисел с плавающей точкой и умножения чисел с фиксированной точкой.
Особенно эффективно использование операционных (арифметических) конвейеров в специализированных вычислительных устройствах с ограниченным набором алгоритмов обработки входных потоков данных, так как в этом случае возможно разбиение АЛУ на большое число простейших быстродействующих конвейерных блоков при небольших схемных и временных потерях на их коммутацию.
В ряде микропроцессоров одновременно присутствуют конвейер команд и арифметический конвейер, при этом часто в процессоре (микропроцессоре) выделяют I -часть — аппаратуру, относящуюся к обработке собственно команд и E -часть — аппаратуру, связанную с операциями над данными1.
I — от Instruction (инструкция, команда) и Е — от Execution (выполнение).
Контрольные вопросы
Что относится к элементам архитектуры ЭВМ.
Что определяет остроту проблемы при выборе структуры и формата команд современных ЭВМ. Каковы пути решения этой проблемы.
Что такое самоопределяемые данные? Почему при использовании тегов сокращается количество различных команд в системе команд машины.
Почему в малоразрядных ЭВМ и микропроцессорах широко используется косвенная адресация? Приведите пример совместного использования регистровой и косвенной адресации. |
Поясните, почему стековая память позволяет использовать безадресные команды? 1
Каковы назначение и особенности реализации команды безусловного перехода с возвратом?
Как с помощью индексации организуется обработка упорядоченных массивов данных?
Каковы назначение и процедуры автоинкрементной и автодекрементной адресаций?
Что общего между вектором состояния программы (процессора) и вектором прерывания?
Каковы назначение и процедура прерывания программ ЭВМ?
Что такое векторное прерывание? Опишите процедуру векторного прерывания с использованием стековой памяти.
В чем различие синхронного и асинхронного конвейеров?
Каким образом особенности RISC-архитектуры способствуют повышению ее быстродействия? Какова при этом роль «перекрывающихся регистровых окон»?
Идеальная память должна обеспечивать процессор командами и данными так, чтобы не вызывать простоев процессора. При этом память должна иметь большую емкость. В современных условиях уменьшение времени доступа достигается введением многоуровневой иерархии памяти. Время доступа зависит от объема и типа используемой памяти.
Типовая современная иерархия памяти имеет следующую структуру:
· регистры 64 - 256 слов с временем доступа 1 такт процессора;
· кэш 1 уровня - 8к слов с временем доступа 2 такта;
· кэш 2 уровня - 256к слов с временем доступа 3-5 тактов;
· основная память - до 4 Гигаслов с временем доступа 12-55 тактов.
Используя помимо основной памяти небольшую и более быструю буферную память, можно значительно сократить количество обращений к основной памяти, за счет аккумуляции текущего фрагмента программного кода в буферной памяти. Создание иерархической многоуровневой памяти, пересылающей блоки программ и данных между уровнями памяти за время, пока предшествующие блоки обрабатываются процессором, позволяет существенно сократить простои процессора в ожидании данных. При этом эффект уменьшения времени доступа в память будет тем больше, чем больше время обработки данных в буферной памяти по сравнению с временем пересылки между буферной и основной памятью. Это достигается при локальности обрабатываемых данных, когда процессор многократно использует одни и те же данные для выработки некоторого результата. Например, такая ситуация имеет место при решении систем уравнений в научных и инженерных расчетах, когда короткие участки программного кода с большим количеством вложенных и зацепленных друг с другом циклов обрабатывают поочередно, переходя от точки к точке, небольшие порции данных, многократно используя одни и те же данные и внутренние результаты.
В связи с тем, что локально обрабатываемые данные могут возникать в динамике вычислений и не обязательно сконцентрированы в одной области при статическом размещении в основной памяти, буферную память организуют как ассоциативную, в которой данные содержатся в совокупности с их адресом в основной памяти. Такая буферная память получила название кэш-памяти. Кэш-память позволяет гибко согласовывать структуры данных, требуемые в динамике вычислений, со статическими структурами данных основной памяти.
Кэш имеет совокупность строк (cache-lines), каждая из которых состоит из фиксированного количества адресуемых единиц памяти (байтов, слов) с последовательными адресами. Типичный размер строки: 16, 64, 128, 256 байтов.
Наиболее часто используются три способа организации кэш-памяти, отличающиеся объемом аппаратуры, требуемой для их реализации. Это так называемые кэш-память с прямым отображением (direct-mapped cache), частично ассоциативная кэш-память (set-associative cache) и ассоциативная кэш-память (fully associative cache).
При использовании кэш-памяти с прямым отображением адрес представляется как набор трех компонент, составляющих группы старших, средних и младших разрядов адреса, соответственно тега, номера строки, смещения. Например, при 16-разрядном адресе старшие 5 разрядов могут представлять тег, следующие 7 разрядов - номер строки и последние 4 разряда - смещение в строке. В этом случае строка состоит из 16 адресуемых единиц памяти, всего строк в кэше 128. Кэш-память с прямым отображением представляет собой набор строк, каждая из которых содержит компоненту тег и элементы памяти строки, адрес которых идентифицируется смещением относительно начала строки.
При этом устанавливается однозначное соответствие между адресом элемента памяти и возможным расположением этого элемента памяти в кэше, а именно: элемент памяти всегда располагается в строке, задаваемой компонентой "номер строки" адреса, и находится на позиции строки, задаваемой компонентой "смещение" адреса.
Наличие элемента данных по запрашиваемому адресу в кэше определяется значением тега. Если тег строки кэш-памяти равен компоненте "тег" адреса, то элемент данных содержится в кэш-памяти.
Иначе необходима подкачка в кэш-память строки, с заданным в адресе тегом.
Так как для определения наличия нужной строки данных в кэш-памяти требуется только одно сравнение тегов заданной строки и адреса, а само замещение строк выполняется по фиксированному местоположению, то объем оборудования, необходимый для реализации этого типа кэш-памяти, достаточно мал.
Недостатки этой организации - очевидны. Если программа использует поочередно элементы памяти из одной строки, но с различными значениями тегов, то это вызывает при каждом обращении замену строки с обращением к данным основной памяти.
Ассоциативная кэш-память использует двухкомпонентное представление адреса: группа старших разрядов трактуется как тег, а группа младших разрядов - как смещение в строке.
Нахождение строки в кэше определяется совпадением тега-строки со значением тега адреса. Количество строк в кэше может быть произвольным (естественное ограничение - количество возможных значений тегов). Поэтому при определении нахождения требуемой строки в кэш-памяти необходимо сравнение тега адреса с тегами всех строк кэша. Если выполнять это последовательно, строка за строкой, то время выполнения сравнений будет непозволительно большим. Поэтому сравнение выполняется параллельно во всех строках с использованием принципов построения ассоциативной памяти, что и дало название этому способу организации кэш-памяти.
При отсутствии необходимой строки в кэш-памяти одна из его строк должна быть заменена на требуемую. Используются разнообразные алгоритмы определения заменяемой строки, например циклический, замена наиболее редко используемой строки, замена строки, к которой дольше всего не было обращений, и другие.
Частично-ассоциативная кэш-память комбинирует оба вышеописанных подхода: кэш-память состоит из набора ассоциативных блоков кэш-памяти. Средняя компонента адреса задает в отличие от прямо адресуемой кэш-памяти не номер строки, а номер одного из ассоциативных блоков. При поиске данных ассоциативное сравнение тегов выполняется только для набора блоков (возможна организация кэша, когда таких наборов несколько), номер которого совпадает со средней компонентой адреса. По количеству n строк в наборе кэш-память называется n -входовой.
Соответствие между данными в оперативной памяти и кэш-памяти обеспечивается внесением изменений в те области оперативной памяти, для которых данные в кэш-памяти подверглись модификации. Соответствие данных обеспечивается параллельно с основными вычислениями. Существует несколько способов его реализации (и, соответственно, несколько режимов работы кэш-памяти).
Один способ предполагает внесение изменений в оперативную память сразу после изменения данных в кэше. При этом процессор простаивает в ожидании завершения записи в основную память. В основной памяти поддерживается правильная копия данных кэша, и при замене строк не требуется никаких дополнительных действий. Кэш-память, работающая в таком режиме, называется памятью со сквозной записью (write- through).
Другой способ предполагает отображение изменений в основной памяти только в момент вытеснения строки данных из кэша. Если данные по адресу памяти, в который необходимо произвести запись, находятся в кэш-памяти, то идет запись только в кэш-память. При отсутствии данных в кэш-памяти производится запись в основную память. Такой режим работы кэша получил название обратной записи (write-back).
Существуют также промежуточные варианты (buffed write though), при которых запросы на изменение в основной памяти буферизуются и не задерживают процессор на время операции записи в память. Эта запись выполняется по мере возможности доступа контроллера кэш-памяти к основной памяти.
Кэш-память с обратной записью (write-back) создает меньшую нагрузку на шину процессора и обеспечивает большую производительность, однако контроллер для write-back кэша значительно сложнее.
Контроллер кэша отслеживает адреса памяти, выдаваемые процессором, и если адрес соответствует данным, содержащимся в одной из строк кэша, то отмечается "попадание в кэш", и данные из кэша направляются в процессор. Если данных в кэше не оказывается, то фиксируется "промах", и инициируются действия по доставке в кэш из памяти требуемой строки. В ряде процессоров, выполняющих одновременно совокупность команд, допускается несколько промахов, прежде чем будет запущен механизм замены строк.
Рассуждения о том, какой способ организации кэш-памяти более предпочтителен, должны учитывать особенности генерации программ компилятором, а также использование программистом при подготовке программы сведений о работе компилятора и контроллера кэш-памяти. То есть более простой способ организации кэш-памяти, поддерживаемый компилятором, при исполнении программ, написанных в соответствии с некоторыми правилами, обусловленными особенностями компиляции и организации кэш-памяти, может дать лучший результат, чем сложный способ организации кэш-памяти.
Так как области памяти программ и данных различны и к ним происходит одновременный доступ, то для повышения параллелизма при работе с памятью делают отдельные кэши команд и данных.
Классификация вычислительных систем
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном [1,2]. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.

| SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка - как машина CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными попадают в этот класс. |

| SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1. |

| MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей [3,4,5] относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе. Будем считать, что пока данный класс пуст. |

| MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. |
Итак, что же собой представляет каждый класс? В SISD, как уже говорилось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими критиками подмечено, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. Для классических процессорных матриц никаких вопросов не возникает, однако в этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP,BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно--конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
Наличие пустого класса (MISD) не стоит считать недостатком схемы. Такие классы, по мнению некоторых исследователей в области классификации архитектур [6,7], могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
Основные классы современных параллельных компьютеров
MPP, SMP, NUMA, PVP, кластеры.
Введение. Основным параметром классификации параллельных компьютеров является наличие общей (SMP) или распределенной памяти (MPP). Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры, где память физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом MPP. При поддержке команд обработки векторных данных говорят о векторно-конвейерных процессорах, которые, в свою очередь могут объединяться в PVP-системы с использованием общей или распределенной памяти. Все большую популярность приобретают идеи комбинирования различных архитектур в одной системе и построения неоднородных систем.
При организациях распределенных вычислений в глобальных сетях (Интернет) говорят о мета-компьютерах, которые, строго говоря, не представляют из себя параллельных архитектур.
Подробно рассмотрим особенности всех перечисленных архитектур, а также в описаниях конкретных компьютеров - представителей этих классов. Для каждого класса приводится следующая информация:
· краткое описание особенностей архитектуры,
· примеры конкретных компьютеров,
· перспективы масштабируемости,
· типичные особенности построения операционных систем,
· наиболее характерная модель программирования (хотя возможны и другие).
Рассмотрим наиболее типичные классы архитектур современных параллельных компьютеров и супер-ЭВМ.
Массивно-параллельные системы (MPP)
| Архитектура | Система состоит из однородных вычислительных узлов, включающих:
|
| Примеры | IBM RS/6000 SP2, Intel PARAGON/ASCI Red, SGI/CRAY T3E, Hitachi SR8000, транспьютерные системы Parsytec. |
| Масштабируемость | Общее число процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue Mountain). |
| Операционная система | Существуют два основных варианта: 6. Полноценная ОС работает только на управляющей машине (front-end), на каждом узле работает сильно урезанный вариант ОС, обеспечивающие только работу расположенной в нем ветви параллельного приложения. Пример: Cray T3E. 7. На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая отдельно на каждом узле. |
| Модель программирования | Программирование в рамках модели передачи сообщений (MPI, PVM, BSPlib) |
Симметричные мультипроцессорные системы (SMP)
| Архитектура | Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. |
| Примеры | HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). |
| Масштабируемость | Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. |
| Операционная система | Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. |
| Модель программирования | Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. |
Системы с неоднородным доступом к памяти (NUMA)
| Архитектура | Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA) |
| Примеры | HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600. |
| Масштабируемость | Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000). |
| Операционная система | Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). |
| Модель программирования | Аналогично SMP. |
Параллельные векторные системы (PVP)
| Архитектура | Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). |
| Примеры | NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, серия Fujitsu VPP. |
| Модель программирования | Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением). |
Кластерные системы
| Архитектура | Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах. Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку. |
| Примеры | NT-кластер в NCSA, Beowulf-кластеры. |
| Операционная система | Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки. |
| Модель программирования | Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач. |
Рассмотрим устаревшие и проектируемые архитектуры.
Denelcor HEP (Heterogeneous Element Processor)
Данный компьютер считается первой коммерчески доступной вычислительной системой с множественным потоком команд. В своей полной конфигурации Denelcor HEP содержит 16 процессорных модулей (Process Execution Module - PEM), через многокаскадный переключатель связанных со 128 модулями памяти данных (Data Memory Module - DMM). Все процессорные модули могут работать независимо друг от друга со своими потоками команд. В свою очередь каждый процессорный модуль может поддерживать до 50 потоков команд пользователей. На уровне процессорного модуля множественность потоков команд обеспечивается одним восьмиуровневым конвейерным устройством для обработки команд. На каждой ступени конвейера должны находиться команды из разных потоков. Следовательно, скорость вычислений увеличивается с увеличением количества потоков команд, пока конвейер не будет заполнен. После заполнения конвейера эта величина остается постоянной.
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 850; Нарушение авторских прав?; Мы поможем в написании вашей работы!