КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Помехоустойчивость и кодирование
|
|
|
|
Коды с обнаружением и исправлением ошибок занимают определенное место в отказоустойчивых системах. Они применяются для придания устойчивости к отказам и сбоям устройства хранения и передачи информации, т. е. устройствам, где информация не преобразуется. Попытки использовать коды с обнаружением и исправлением ошибок для придания свойства отказоустойчивости преобразователям информации пока не увенчались успехом. Тем не менее вопрос о кодах с обнаружением и исправлением ошибок представляет большой интерес, так как эти коды допускают применение теоретических методов синтеза, позволяющих получить наиболее эффективные и экономные технические решения. Например, если существующие методы резервирования требуют, по крайней мере, в однопроцессорных системах удваивания количества аппаратуры, то при помощи кодов с обнаружением и исправлением ошибок аналогичный эффект может быть достигнут увеличением количества оборудования на 10...30%.
Общая схема применения кодов с обнаружением и исправлением ошибок показана на рис. 8.1. Исходная кодовая комбинация U расширяется добавлением дополнительных корректирующих разрядов в кодирующем устройстве k. Полученная кодовая комбинация x передается через канал связи C или записывается в памяти П. При этом могут возникать ошибки либо из-за технической неисправности С или П, либо из-за сбоев. В результате передается или считывается кодовая комбинация x*, которая после декодирования устройством D приобретает вид исходной кодовой комбинации U.
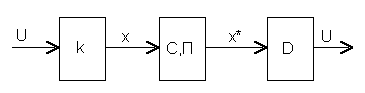
Рис. 8.1. Общая схема применения кодов с обнаружением и исправлением ошибок
Коды с обнаружением и исправлением ошибок подразделяются на блоковые коды, т. е. коды, где кодирование и декодирование производятся отдельными блоками, и на сверточные коды, декодирование и кодирование которых производится непрерывно.
Наиболее распространенными являются линейные блоковые коды, которые образуются при помощи линейных алгебраических операций. Для оценки корректирующей способности кода применяется, неравенство Хэмминга
d d
Σ Cin ≤ 2n-k, откуда k ≤ n – log2 Σ Cin,
i=0 i=0
где n — число разрядов кода x=(x1,x2, ...,хn) с обнаружением и исправлением ошибок; k — число информационных разрядов (разрядность кода U=(U1,U2, …,Uk), d — количество исправляемых ошибок).
Ниже приведены некоторые-результаты расчета по неравенству Хэмминга:
n … 7 63 63
d … 1 1 3
k … 4 57 47
Следовательно, относительное число информационных разрядов, используемых для передачи полезной информации, растет с увеличением длины кода. Однако при этом растет и сложность кодирующего и декодирующего устройства. При увеличении числа обнаруживаемых ошибок количество необходимых контрольных разрядов также растет.
Расстоянием ρ(x1,x2) между двумя n-кодовыми комбинациями x1 и x2 называется величина
n
ρ(x1,x2) = Σ (x1i + x2i),
i=1
где + — сложение по модулю 2.
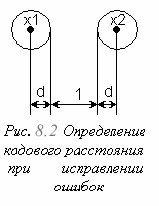 Чтобы кодовые комбинации, окружаемые гиперсферой с радиусом d (в такую гиперсферу вписываются все кодовые комбинации с ошибками кратности не более d), были взаимно различимы, достаточно, если расстояние ρ между этими кодовыми комбинациями удовлетворяет неравенству
Чтобы кодовые комбинации, окружаемые гиперсферой с радиусом d (в такую гиперсферу вписываются все кодовые комбинации с ошибками кратности не более d), были взаимно различимы, достаточно, если расстояние ρ между этими кодовыми комбинациями удовлетворяет неравенству
ρ ≥ 2d + 1 (8.1)
(рис. 8.2). Рассуждая аналогично, можно установить, что кодовые комбинации, позволяющие обнаружить d1 ошибок, должны быть разнесены друг от друга на расстояние
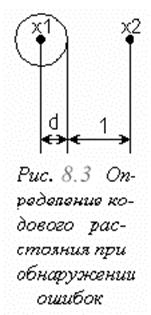 ρ ≥ d1 + 1 (8.2)
ρ ≥ d1 + 1 (8.2)
Действительно, для обнаружения ошибки достаточно, чтобы ошибочная кодовая комбинация не совпадала с другой, правильной кодовой комбинацией. Это гарантируется единичным (минимальным) расстоянием, поэтому в (8.2) к d1 прибавляется единица (рис. 8.3). В общем случае существует также неравенство ρ ≥ d + d1 + 1. Следовательно, проблема помехоустойчивого кодирования сводится к проблеме максимально плотной упаковки гиперсфер заданного радиуса в заданном двоичном гиперпространстве и установления их центров — отдельных «разрешенных» кодовых комбинаций.
Матричное представление кодов с обнаружением и исправлением ошибок. Указанная выше задача может быть разрешена при помощи линейной матричной операции x = UGk×n, где Gk×n — некоторая матрица двоичных элементов, называемая порождающей матрицей. Матричные операции в данном случае производятся по обычным правилам, только взамен сложения по правилам элементарной алгебры применяется операция сложения по модулю 2 (обозначение +). Тогда все элементы матриц и векторов остаются в множестве {0,1}. Для декодирования вводится матрица Н(n-k)×n, называемая контрольной матрицей. Произведение xНT(n-k)×n = S называется синдромом. Синдром позволяет получить представление о наличии и характере ошибок в коде x. Допустим, что
G = [Ek | Ak×(n-k)], (8.3)
где
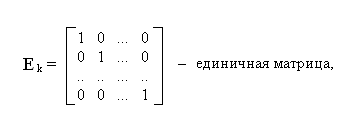
и требуем, чтобы xНТ= [0], тогда Н(UG)T=[0] или HGTUT=[0] или HGT=[0], или GTHT=[0]. Произведение GTHT=[0], если
Н = [ATkx(n-k) | En-k] (8.4)
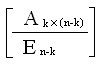 Действительно
Действительно
[Ek | Akx(n-k)] [AT(n-k)×k | En-k]T = [Ek | Ak×(n-k)] = Ak×(n-k) +
Ak×(n-k) ≡ [0].
Если корректирующая матрица составлена по (8.4), то в случае, когда код х* содержит ошибки, что обозначается звездочкой, х*НТ ≠ [0], иначе х*HТ ≠ [0]. Далее необходимо расшифровать синдром х*НТ ошибочного кода, т. е. локализовать и затем исправить возникшую ошибку.
Коды Хэмминга. Расшифровка синдрома наиболее проста, когда порождающая матрица строится по способу Хэмминга. Исходным при этом является некоторая вспомогательная матрица Н0, состоящая из возрастающих двоичных чисел (начиная от единицы), читаемых сверху вниз. На основании матрицы Н0 строится матрица Н перестановкой столбцов матрицы Н0 так, чтобы справа образовалась единичная подматрица. Затем, переставляя единичную подматрицу Е и подматрицу A между собой и транспонируя в соответствии с (8.3) и (8.4), получаем порождающую матрицу G. Замечательным свойством синдрома кодов Хэмминга является то, что синдром, читаемый как двоичное число, указывает номер разряда, где произошла ошибка. Однако при переходе от матрицы Н0 к матрице Н последовательность столбцов изменяется. Исправляемый разряд определяется по столбцу матрицы Н, совпадающему с синдромом.
Пример. Кодирование и декодирование кода Хэмминга. Пусть
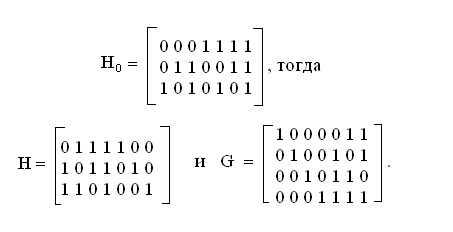
Если имеется, например, кодовая комбинация U=1110, то x = UG = 1110000.
Пусть ошибка возникает в пятом элементе кодовой комбинации x, т. е. x* = 1110100. Тогда синдром S = x*НT = 100, что указывает на то, что отказал пятый элемент кодовой комбинации х.
Код Хэмминга дает возможность исправлять только одиночные ошибки. Модифицированный код Хэмминга позволяет обнаруживать двойные ошибки и часть ошибок более высокой кратности, а также исправлять одиночные ошибки. Модифицированный код Хэмминга образуется путем прибавления к кодовой комбинации кода Хэмминга x = (x1, …xn) дополнительного разряда xn+1, который образуется по следующей формуле:
n
xn+1 = Σ + xi,
i=1
где Σ + означает суммирование по модулю 2. Следовательно, минимальное кодовое расстояние между двумя кодовыми комбинациями модифицированного кода Хэмминга d ≥ 4.
Декодирование модифицированного кода Хэмминга осуществляется на основании табл. 8.1.
Таблица 8.1
| Синдром | xn+1 | Описание ситуации |
| = 0 | Ошибок нет или 4,6,… ошибок | |
| ≠ 0 | Две ошибки обнаруживаются | |
| = 0 или ≠0 | 3,5… ошибок | |
| ≠0 | Одна ошибка, исправляется |
Формально модифицированный код Хэмминга может быть образован с помощью порождающей матрицы G, к которой добавлен столбец, образующий дополнительный (U+1)-й разряд. Рассмотрим образование этого разряда на примере кодирования по Хэммингу, рассмотренного выше.
Продолжение примера. По определению,
x8 = x1 + x2 + x3 + x4 + x5 + x6 +x7 =
x5
= U1 + U2 + U3 + U4 +U2 + U3 + U4 +
x6 x7
+ U1 + U3 + U4 + U1 + U2 + U4 = U1 + U2 + U3
Следовательно, матрица модифицированного кода Хэмминга GM приобретает вид
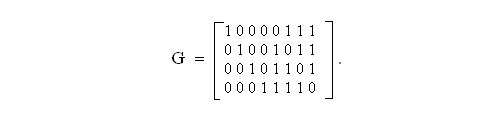
Контрольная матрица модифицированного кода НМ образуется путем прибавления единичной верхней строки к соответствующей контрольной матрице исходного кода Хэмминга. При этом добавляется также дополнительный столбец справа, все элементы которого, кроме верхнего, равны нулю.
Коды Хэмминга могут быть построены также с основанием системы счисления q > 2. В этом случае матрица Н0 строится из столбцов, представляющих собой возрастающие q-ичные числа. Однако при этом могут возникать линейно зависимые столбцы, т. е. столбцы, сумма которых (по модулю q) равна нулю. Например, при q = 3
0 + 0 = 0,
……….
1 + 2 = 0,
……….
2 + 1 = 0,
где + означает сложение по модулю 3. Поскольку линейно зависимые столбцы в матрице Н0 (и H) не позволяют построить код Хэмминга, в случае q = 3 рекомендуется исключить из матрицы все столбцы, которые начинаются с двойки или с двойки после нуля или нулей.
Пример. Построить матрицы Н0, Н и G для кода Хэмминга с основанием q=3 и с числом контрольных разрядов m = n - k =3.
Тогда матрица Н0 приобретает следующий вид:
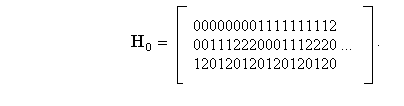
Запрещенные столбцы в матрице Н0 вычеркиваются. Матрица Н образуется из матрицы Н0 путем перестановки столбцов так, чтобы справа образовалась единичная матрица, т. е.
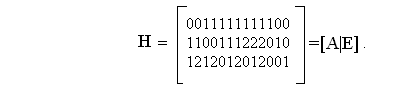
Порождающая матрица образуется тогда путем перестановки подматриц A и Е, т.е.
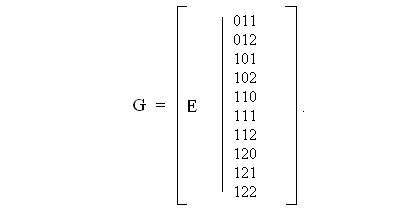
Если выбирать q = 3, то каждый q-ичный разряд представляется двумя двоичными разрядами. Следовательно, такой код Хэмминга позволяет исправлять ошибки в двух двоичных разрядах, образующих один q-ичный разряд.
В случае, когда необходимо исправлять больше одной ошибки при произвольной их комбинации, может быть применен код Рида — Маллера. Порождающая матрица G кода Рида—Маллера образуется состоящей из r +1 подматриц, расположенных следующим образом,
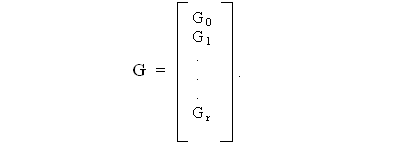
Матрица G0 — это единичная строка, т. е.
G0 = [11…1].
Матрица G1 образуется как матраца Н0 в виде возрастающих m-разрядных двоичных чисел, только с добавлением нулевого столбца слева, т. е.
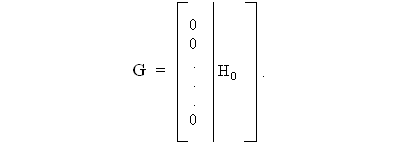
Следующие подматрицы G2, G3, …,Gi, …, Gr образуются из строк, полученных как произведения всех комбинаций строк матрицы G1, взятых по i. Следовательно, число строк матрицы G
r
k = Σ Cin,
i=0
где n — число столбцов матрицы G. Минимальное кодовое расстояние между кодовыми комбинациями Рида—Маллера
dmin ≤ 2 m-r.
Например, если m = 4, r = 2, n = 16, то k = C14 + C24 = 1 + 4 + 6 = 11, dmin ≤ 2 m-r = = 2 4 – 2 = 4.
Следовательно, код позволяет обнаруживать две ошибки и исправлять одну. Если же m = 6, r = 3, n = 64, то k = 42 и dmin = 8, т. е. обнаруживается до семи и исправляется до трех ошибок.
В первом случае порождающая матрица имеет вид

x0x1x2x3 x4x5x6x7 x8x9x10x11 x12x13x14x15
Кодирующее устройство строится аналогично тому, как построено кодирующее устройство для кода Хэмминга, выполняющее операцию умножения вектора на матрицу x = UG.
Декодирование кода Рида-Маллера осуществляется по особому алгоритму, основанному на том, что отдельные составляющие вектора U можно получить виде сумм различных комбинаций составляющих вектора x*. Если отдельные составляющие искажены, то полученные. значения составляющего U могут различаться и правильное значение каждого составляющего находится методом голосования. Например, в случае приведенной порождающей матрицы имеется четыре варианта U10,
U10(1) = x*0 + x*1 + x*2 + x*3,
U10(2) = x*4 + x*5 + x*6 + x*7,
U10(3) = x*8 + x*9 + x*10 + x*11,
U10(4) = x*12 + x*13 + x*14 + x*15.
I
Легко убедиться в том, что все остальные составляющие приведенных сумм столбцов порождающей матрицы нулевые, так как в каждой их строке, кроме десятой, число слагаемых единиц — четное.
Аналогичным образом могут быть составлены варианты дла U9,
U9(1) = x*0 + x*1 + x*2 + x*3,
U9(2) = x*4 + x*5 + x*6 + x*7,
U9(3) = x*8 + x*9 + x*10 + x*11,
U9(4) = x*12 + x*13 + x*14 + x*15.
Такие зависимости имеются для всех строк подматрицы Gr. При декодировании следующей подматрицы Gr-1, нужно, чтобы под матрица Gr при этом не участвовала.
На рис.8.4 приведен фрагмент схемной реализации выше приведенных уравнений с последующим голосованием.
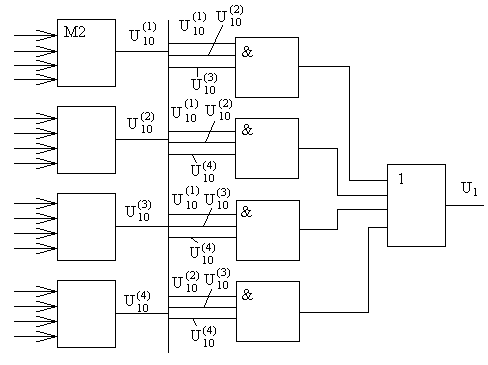
x*0
x*1
x*2
x*3
x*4
x*5
x*6
x*7
x*8
x*9
x*10
x*11
x*12
x*13
x*14
x*15
Рис. 8.4. Фрагмент схемной реализации дешифратора для кода Рида-Маллера
Циклические коды. При передаче данных, осуществляемых последовательно, большое значение имеют циклические коды — коды, для которых циклическая перестановка кодовых символов некоторого кодового слова порождает также кодовое слово. Например, если задано некоторое кодовое слово x = (x0, …,xn), то при циклической перестановке образуются кодовые слова x(1) =(xn,x0,...,xn-1), x(2) =(xn-1,xn, x0,...,xn-2) и т. д. Циклические коды удобно представлять в виде полиномов, тогда говорят о циклических полиномиальных кодах. Полиномиальное представление кода заключается в том, что код представляется в виде полинома, причем степень каждого слагаемого соответствует позиции данного ненулевого кодового элемента.
Например, двоичное кодовое слово 11010 может быть представлено виде полинома 1 · x4 + 1 · x3 + 0 · x2 + 1 · x1 + 0 · x0 = x4 + x3 + x. Полиномиальные циклические коды позволяют обнаруживать и исправлять ошибки. Кодирование при циклических кодах осуществляется путем деления полинома, изображающего исходное кодовое слово, на подходящим образом подобранный полином, называемый порождающим полиномом. Остаток, образовавшийся при делении, приписывается к исходному кодовому слову в качестве набора контрольных символов.
Обозначая через U — исходное кодовое слово в полиномиальной форме, g — порождающий полином, q — частное и r — остаток, получаем соотношение Ux(n-k)/g = = q + r/g откуда Ux(n-k) = qg + r. Здесь и далее подразумевается, что сложение производятся по модулю 2 и поэтому вычитание равноценно сложению, следовательно, кодовое слово ν = qg = Ux(n-k) + r. При этом исходное кодовое слово умножается на коэффициент x(n-k), где n — общая длина кодового слова, а k — количество информационных разрядов. Эта операция означает, что информационная часть кодового слова сдвигается влево на n – k разрядов, а на освободившееся справа свободное место записывается остаток r. Поскольку операция сложения остатка r по модулю 2 равноценна вычитанию этого остатка, получающееся кодовое слово ν, подлежащее передаче, делится на порождающий многочлен g без остатка. Если же при передаче кодовое слово ν исказятся, т. е. образуется кодовое слово (или соответственно многочлен) ν*‚ то в результате деления на приемном конце канала связи ν* на g образуется остаток, который служит синдромом, позволяющим обнаруживать и исправлять ошибку.
Приведем пример кодирования и декодирования циклического кода. Пусть порождающий полином g имеет вид g = x4 + x + 1, а общая длина кодовых слов с коррекцией n = 9 при числе информационных разрядов k = 4. Пусть передается кодовое слово 1101, что соответствует полиному U = x3 + x2 + 1. Произведение
Ux(n-k) = (x3 + x2 + +1)x5 = x8 + x7 + x5.
При делении Ux(n-k)/g получается, что частное q = x4 + x3, а остаток r = x3. Все вместе дает полином ν = x8 + x7 + x5 + x3, что соответствует передаваемому кодовому слову 110101000.
Если это кодовое слово передается без искажений, то при его делении на g получается, что остаток r = 0. При одиночкой ошибке возможны девять различных векторов ошибок, приведенных ниже, в табл. 8.2.
В таблице приведены синдромы, полученные при делении, принятого кодового слова на порождающий полином. Например, если передается кодовое слово 110101000 и искажается старший разряд, то получается кодовой слово 010101000, которому соответствует полином x7 + x5 + x3. При делении этого полинома на порождающий полином вида x4 + x + 1
Таблица 8.2
| Вектор ошибок | Полиномиальная запись ошибки | Синдром (остаток) | Полиномиальная запись остатка |
| x8 | x2 + 1 | ||
| x7 | x3 + x + 1 | ||
| x6 | x3 + x2 + 1 | ||
| x5 | x2 + x | ||
| x4 | x + 1 | ||
| x3 | x3 | ||
| x2 | x2 | ||
| x1 | x | ||
x7 + x5 + x3 |_ x4 + x + 1
x7 + x4 + x3 x3 + x + 1
x5 + x4
x5 + x2 + x
x4 + x2 + x
x4 + x + 1
x2 + 1
получим остаток r = x2 + 1. Аналогично находятся также и другие остатки.
Каждой одиночной ошибке соответствует определенное значение синдрома, которое может быть заранее установлено, введено в запоминающее устройство, а затем использовано для исправления ошибки.
Вследствие того что кодовое слово делится на порождающий полином без остатка, вектор ошибок определяется однозначно синдромом (остатком). Векторы ошибок, соответствующие отдельным синдромам, могут быть установлены заранее и использованы при декодировании. Основным преимуществом полиномиальных циклических кодов перед линейными блоковыми кодами, кодируемыми и декодируемыми при помощи матричных операций, является простота схемной реализации. Сложность, т.е. количество элементов в преобразователе, определяется при операциях типа деления полиномов как величина пропорциональная n. Количество элементов для схемной реализации матричных операций пропорционально n2. Преимущество циклических кодов проявляется при последовательном представлении кодов. Поэтому циклические полиномиальные коды применяются для повышения помехоустойчивости каналов связи, НМЛ и НМД, в которых информация передается и представляется последовательными кодами. Отметим, что при помощи последовательных кодов, в том числе циклических полиномиальных кодов, нельзя повысить отказоустойчивость устройств, поскольку отказ канала передачи или запоминания влечет за собой искажение всех элементов кода.
Устройства для деления полиномов (цифровые фильтры) реализуются схемно достаточно просто. На рис. 8.5 в качестве примера изображена схема фильтра для деления некоторого полинома на полином x4 + x + 1. Фильтр состоит из регистра сдвига P с разрядами 1-4 и из двух сумматоров по модулю 2.

Рис. 8.5. Схема устройства для деления полиномов
Таблица 8.3
| Такт | Вход | Содержание регистра | Выход | |||
| P1 | P2 | P3 | P4 | |||
В качестве примера на вход подается кодовое слово 110100000, начиная со старшего разряда, что соответствует полиному x8 + x7 + x5. В таблице 8.3 изображены такты работы устройства, начиная с момента достижения старшим разрядом делимого ячейки Р4. Строки таблицы соответствуют тактам работы схемы, столбцы — содержанию ячеек регистра. По бокам таблицы изображены входящие и выходящие элементы кодов, не записанные в регистре.
При продвижении элементов кода слева направо происходит деление. В результате деления образуется кодовая комбинация 11000, соответствующая частному (x4 + x3).
В регистре при этом остается остаток x3 в виде кодовой комбинации 1000.
В общем случае умножение двух полиномов ν(x) = U(x)g(x), где
U(x) = Unxn + Un-1xn-1 +…+ U1x + U0,
g(x) = gmxm + gm-1xm-1 +…+ g1x + g0,
ν(x) = ν sxs + ν s-1xs-1 +…+ ν 1x + ν 0
осуществляется на основании следующего уравнения:
ν = Ungmxn+m + (Ungm-1 +Un-1gm)xn+m-1 + (Ungm-2 + Un-1gm-1 + Un-2gm)xn+m-2 + …
…+ (U1g0 + U0g1)x + U0g0,
которое получено путем упорядочения членов произведения двух полиномов по степеням х.
Аппаратно умножение может быть осуществлено с помощью устройства, схема которого изображена на рис.8.6. Устройство предназначено для умножения полинома, g(x), задаваемого схемой, на полином U(x), подаваемые на вход схемы в виде последовательности импульсов, соответствующих ненулевым коэффициентам полинома, начиная со старшего разряда. Произведение выходит из устройства также в виде последовательности импульсов, начиная со старшего разряда. В схеме (рис.5.13) квадратиками обозначены элементы задержки 3 (триггерные ячейки), знаком + обозначены одноразрядные сумматоры по модулю 2, а знак i означает прямое соединение, если коэффициент многочлена gi = 1 и отсутствие соединения в противоположном случае.
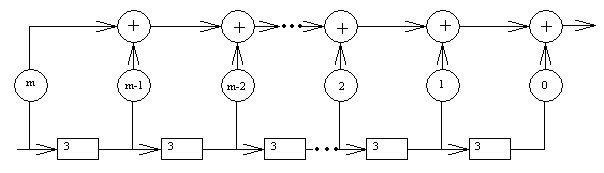
ν0ν1…νs-1νs
U0U1…Un-1Un
Рис. 8.6. Общая схема устройства для умножения полиномов
В первый такт работы устройства коэффициент Un умножается на коэффициент gm и результат поступает через элементы + на выход как νs. Во втором такте на вход поступает Un-1 и, умноженный на gm, поступает на вход левого сумматора +. В то же время на нижний вход этого же сумматора поступает задержанный сигнал Un, умноженный на gm-1, а сумма выдается как νs-1 в полном соответствии с вышеприведенной формулой. После s + 1 = m + n -1 тактов работы на выходе произведение появляется полностью. Деление полиномов ν(x): g(x) = U(x) в общем случае осуществляется с помощью устройства, схема которого изображена на рис. 8.7.
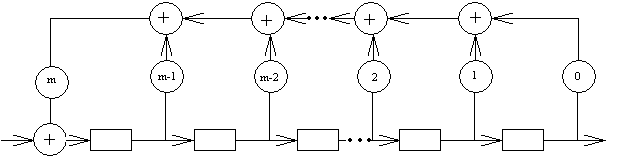
ν0ν1…νs-1νs U0U1…Un-1Un
Рис 8.7. Общая схема устройства для деления полиномов
Функционирование устройств умножения и деления удобно списывать с помощью автоматного уравнения в виде
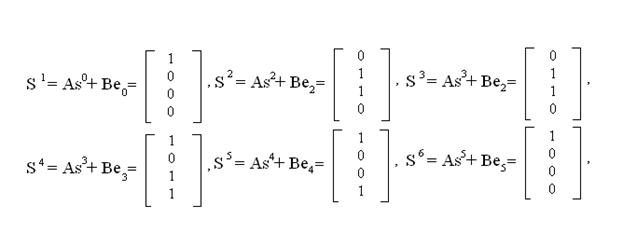
si+1 = Asi + Bei,
где А — матрица переходов состояний регистра, В — матрица-столбец входов, si — матрица-столбец, описывающее состояние регистра в i-м такте и ei — значение входа в i-м такте.
Так, для примера рис. 5.12
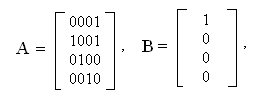
е0 = x8 = 1, e1 =x7 = 1, е2 = x6 = 0, е3 = x5 = 1,
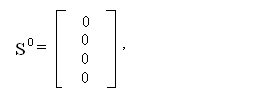
е4 …e8 = x4 … x0 = 0,
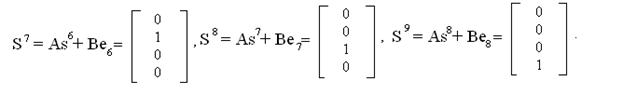
Наиболее универсальными и удобными для кодирования и декодирования являются коды БЧХ, названные так по первым буквам фамилий авторов (Боуз, Чоудхри, Хоквингем). Основное преимущество их заключается в том, что декодирование этих кодов может быть произведено алгоритмически и для этого не требуется запоминать остатки для всех конфигураций ошибок. Это особенно важно в случае длинных кодовых слов, где число конфигураций ошибок может быть очень большим.
Порождающий многочлен кодов БЧХ образуется по следующей формуле:
g(x) = HOK[f1(x),f2(x), …,f2t(x)],
где НОK означает наименьшее общее кратное некоторого числа заданных многочленов; fi(x) — i-й минимальный многочлен кода, а t — число исправляемых ошибок.
Величина d = 2t + 1 носит название конструктивного расстояния. Практически минимальное расстояние между двумя генерированными кодовыми комбинациями может быть и больше.
Минимальный многочлен fi(x) — это многочлен минимального порядка, который равен нулю, если в качестве аргумента x подставить элемент поля Галуа αi. Элемент поля Галуа α выбирается так, чтобы все другие элементы поля могли быть найдены как степени этого элемента. Кроме степенного представления существует полиномиальное представление каждого элемента поля Галуа в виде полинома от z. Такая двойственность представления элементов поля Галуа полезна тем, что умножение многочленов удобно осуществлять в степенной, а сложение — в полиномиальной форме.
Значение i-го элемента поля в полиномиальной форме находится по условию
βi(z) = Rp(z)(zi), (8.5)
где функция Rp(z) означает вычисление остатка по модулю p(z).
От выбора примитивного многочлена p(z) зависит число элементов поля, определяемое как qm - 1, где q — основание системы счисления, а m — степень примитивного многочлена p(z). В табл. 8.4 приведены значения примитивных полиномов для различных значений m в случае, когда q = 2.
Таблица 8.4
| m | p(z) |
| z2 + z + 1 | |
| z3 + z + 1 | |
| z4 + z + 1 | |
| z5 + z2 + 1 | |
| z6 + z + 1 | |
| z7 + z3 + 1 | |
| z8 + z4 + z3 + z2 + 1 | |
| z9 + z4 + 1 | |
| z10 + z3 + 1 |
На основании примитивного многочлена составляются элементы поля. В случае, когда m = 4, элементы поля будут следующими (табл. 8.5).
Таблица 8.5
| Степенная форма αi | Полиномиальная форма | Минимальный многочлен |
| α0 | x + 1 | |
| α1 | z | x4 + x + 1 |
| α2 | z2 | x4 + x + 1 |
| α3 | z3 | x4 + x3 + x2 + x + 1 |
| α4 | z+1 | x4 + x + 1 |
| α5 | z2 + z | x2 + x + 1 |
| α6 | z3 + z2 | x4 + x3 + x2 + x + 1 |
| α7 | z3 + z + 1 | x4 + x3 +1 |
| α8 | z2 + 1 | x4 + x + 1 |
| α9 | z3 + z | x4 + x3 + x2 + x + 1 |
| α10 | z2 + z +1 | x2 + x + 1 |
| α11 | z3 + z2 + z | x4 + x3 +1 |
| α12 | z3 + z2 + z +1 | x4 + x3 + x2 + x + 1 |
| α13 | z3 + z2 + 1 | x4 + x3 +1 |
| α14 | z3 + 1 | x4 + x3 +1 |
Таким образом, элементы поля в полиномиальной форме находятся по выражению (8.5).
До третьей степени степенная форма элемента поля совпадает с полиномиальной формой. Однако уже α4 не равно z4, а образуется как остаток от деления z4 на примитивный полином при m = 4, т. е. на полином z4 + z + 1. Очевидно, остаток при делении будет z +1. Таким образом определяют всё полиномиальные элементы данного поля. Интересно отметить, что, поступая таким образом получают, что элемент α15 = α0 =1, элемент α16 = α1 = z и т. д. Другими словами, степени α начнут циклически повторяться по модулю 15.
Кодирование кодов БЧХ осуществляется обычным способом, т. е. каждый многочлен U(x) умножается на порождающий полином g(х). Декодирование при этих кодах сложнее и осуществляется, как правило, программными средствами, особенно в случае длинных кодов.
Алгоритм декодирования кодов БЧХ заключается в следующем.
1. Вычисляются синдромные многочлены Si = n* (αi), для i = 1,..., n‚ при n = t. Многочлен n*(x) является многочленом, описывающим принятую, возможно, с ошибками кодовую комбинацию.
2. Вычисляется значение определителя
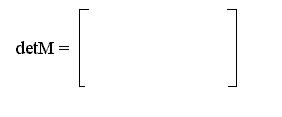
S1 S2 S3 …Sn
S2 S3 S4 …Sn-1.
………….
Sn Sn+1 …S2n-1
3. Если detМ=0, то n = n - 1, следует возвращаться к п. 2. Иначе‚ n — фактическое число ошибок и следует переходить к следующему пункту.
4. Вычисляются вспомогательные величины L1, L2, … Ln по следующему матричному уравнению:
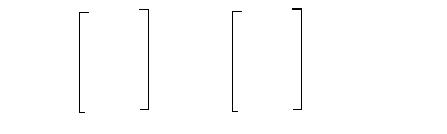
Ln Sn+1
Ln-1 Sn+2
… = - M-1 ….
L1 S2n
В случае q = 2 минусы в правой матрице отпадают.
5. Составляется полином
L(x) = Lnxn + Ln-1xn-1 + … + L1x + 1.
б. Определяются корни полинома п. 5 в виде элементов поля (степеней α).
7. Определяются номера разрядов ошибок как дополнения показателей степеней корней, найденных в п. б, по модулю qm -1.
Отметим, что все операции производятся над элементами поля Галуа в виде степеней a, причем операции умножения заключаются в сложении показателей степеней a по модулю qm -1, операции сложения — в сложении членов полинома одинакового порядка по модулю q в полиномиальной форме элементов кода.
Пример. Пусть m = 4 и q = 2, t = 3. Тогда порождающий многочлен
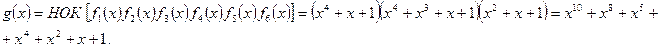
Пусть принятое кодовое слово n* (х) = х5 + x4.
Тогда по п. 1 алгоритма
S1 = a5 + a4 = z2 + z + z + 1 = z2 + z + z + 1 = a8,
S2 = a10 + a8 = z2 + z + 1 + z2 + 1 = z = a1,
S3 = a15 + a12 = a0 + a12 = 1 + z3 + z2 + z + 1 = a11,
S4 = a5 + a16 = a5 + a1 = z2 + z + z = z2 = a2,
S5 = a10 + a20 = a10 + a5 = z2 + z + 1 + z2 + z = a0,
S6 = a15 + a24 = a0 + a9 = 1 + z3 + z = a1.
По п. 2 алгоритма
a8 a1 a11
a1 a11 a2 = a8( a11 + a4) + a1(a1 + a13) + a11(a3 + a7) =0.
a11 a2 a0
По п. З алгоритма n = n -1 = 2 и по п. 1 определитель вычисляется снова:
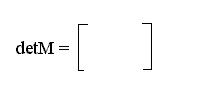
a8 a1
= a4 + a7 = z +1 +z2 = a10¹ 0.
a1 a11
Следовательно, фактическое число ошибок n = 2.
По п. 4 вычисляются вспомогательные величины L1, L2. Для этого находится обратная матрица.
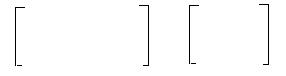

a8 a1 -1 a11/a10 a11/a10 a1 a6
M-1= = =.
a1 a11 a1/a10 a8/a10 a6 a13
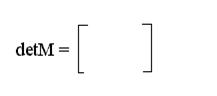 Так как определитель матрицы
Так как определитель матрицы
a8 a1
= a4 + a2 = z +1 +z2 = a10,
a1 a11
то тогда
L2 S3 a1 a6 a11 a12 + a8 a9
=M-1 = = =.
L1 S4 a6 a3 a2 a2 + a0 a8
По п. 5 составляем полином
L(x) = a9 x2 + a8x + 1.
Корни находятся из условия
a9 x2 + a8x + 1 = 0.
Если полином представить в виде
(aa x + 1)( abx + 1) = aa+b x2 + (aa + ab)x +1,
то имеем ограничения a + b = 9 и aa + ab = a8. Кроме того, требуется, чтобы a + 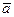 =15 и
=15 и
b + 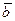 = 15, где и – степени искомых корней. Очевидно, тогда требуется, чтобы +=21. Путем проб и ошибок можно определить, что aa + ab = a8 при a = 5 и b = 4.
= 15, где и – степени искомых корней. Очевидно, тогда требуется, чтобы +=21. Путем проб и ошибок можно определить, что aa + ab = a8 при a = 5 и b = 4.
Эти значения и указывают номера ошибочных разрядов. Следовательно, правильный полином n(x) = 0.
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 650; Нарушение авторских прав?; Мы поможем в написании вашей работы!