КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основные положения теории прогнозирования
|
|
|
|
Тема 11. Применение методов прогнозирования в логистике
В снабженческой, производственной и распределительной логистиках широко используются методы прогнозирования, поскольку значения прогнозных оценок развития анализируемых процессов или явлений являются основой принятия управленческих решений при оперативном, тактическом и стратегическом планировании. Очевидно также, что точность и надежность прогноза определяет эффективность реализации различных логистических операций и функций – от оценки вероятности дефицита продукции на складе до выбора стратегии развития фирмы.
Теория прогнозирования включает анализ объекта прогнозирования; методы прогнозирования, подразделяющиеся на математические (формализованные) и экспертные (интуитивные); системы прогнозирования, в частности непрерывного, при котором за счет мониторинга осуществляется корректировка прогнозов в процессе функционирования объекта.
Одним из основных классификационных признаков является также период прогноза, при этом большинство авторов выделяют три вида прогнозов: краткосрочный, среднесрочный и долгосрочный. Естественно, что временные интервалы прогнозов зависят от природы объекта, т. е. изучаемой области деятельности. Так, при рассмотрении технико-экономических показателей деятельности фирм период краткосрочного прогноза не превышает 1 года, среднесрочного прогноза – от 1 до 5 лет, долгосрочного – свыше 5 лет.
Математические методы прогнозирования подразделяются на три группы:
- симплексные (простые) методы экстраполяции по временным рядам;
- статистические методы, включающие корреляционный и регрессионный анализ и др.;
- комбинированные методы, представляющие собой синтез различных вариантов прогнозов.
Прогнозы I типа (в «узком» смысле):
- осуществляются с применением симплексных или статистических методов на основе временных рядов;
- число значимых переменных включают от 1 до 3 параметров, т. е, по масштабности они относятся к сублокальным прогнозам;
- при использовании одного параметра, например, времени, такие прогнозы считаются сверхпростыми, при двух-трех взаимосвязанных параметрах – сложными;
- по степени информационной обеспеченности периода ретроспекции прогнозы I типа могут быть отнесены к объектам с полным информационным обеспечением.
Для повышения точности и достоверности прогнозных оценок I типа целесообразно использование комбинированных методов, при этом желательно использование большого количества вариантов прогноза, рассчитанных на основе различных подходов или альтернативных источников информации.
Прогноз II типа (в «широком» смысле) подразумевает, что исходные данные для получения оценок определяются с использованием опережающих методов прогнозирования: «патентного», публикационного и др. Как правило, прогнозы II типа используются для долгосрочного прогнозирования и разбиваются на два этапа: первый – получение прогнозных оценок основных факторов; второй – собственно прогноз развития процесса или явления. Учитывая объективную сложность и трудоемкость выполнения прогнозов II типа, можно констатировать, что наибольшее распространение получили методы прогнозирования I типа.
Наиболее часто для прогнозирования I типа используется метод экстраполяции. В общем случае модель прогноза включает три составляющие (рис. 3.4.1) и записывается в виде: (1.1)
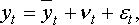
где yt – прогнозные значения временного ряда;
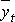 – среднее значение прогноза (тренд);
– среднее значение прогноза (тренд);
vt – составляющая прогноза, отражающая сезонные колебания (сезонная волна);
εt – случайная величина отклонения прогноза.
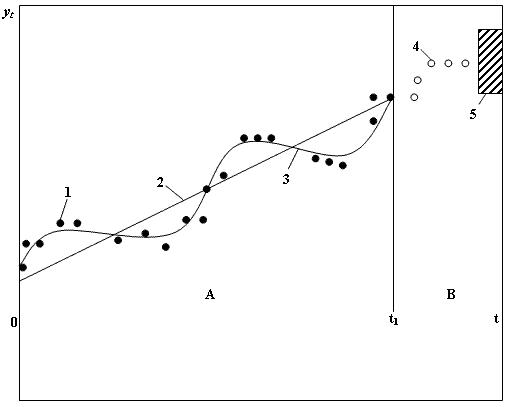
Рис.11.1. Прогнозирование на основе временных рядов:
1 – экспериментальные данные на интервале наблюдения (A);
2 – тренд; 3 – тренд и сезонная волна;
4 – значение точечного прогноза на интервале упреждения (B);
5 – интервальный прогноз
В частных случаях количество составляющих модели меньше, например, только 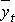 и vt.
и vt.
Подробно вопросы прогнозирования с использованием методов экстраполяции изложены в ряде работ, но ввиду отсутствия общепринятого алгоритма обработки временных рядов может быть предложена следующая последовательность расчета:
1). На основе значений временного ряда на предпрогнозном периоде (интервале наблюдения) с использованием метода наименьших квадратов определяются коэффициенты уравнения тренда yt, видом которого задаются. Обычно для описания тренда используются полиномы различных порядков, экспоненциальные, степенные функции и т. п.
2). Для исследования сезонной волны значения тренда исключаются из исходного временного ряда. При наличии сезонной волны определяют коэффициенты уравнения, выбранного для аппроксимации vt.
3) Случайные величины отклонения εt определяются после исключения из временного ряда значений тренда и сезонной волны на предпрогнозном периоде. Как правило, для описания случайной величины εt используется нормальный закон распределения.
4). Для повышения точности прогноза применяются различные методы (дисконтирование, адаптация и др.). Наибольшее распространение в практике расчетов получил метод экспоненциального сглаживания, позволяющий повысить значимость последних уровней временного ряда по сравнению с начальными.
Примеры прогноза текущего запаса на складе. Рассмотрим применение методов прогнозирования на основе данных расхода деталей на складе. В табл. 11.1 приведены три реализации текущего расхода; для каждой реализации даны величины расхода за день характеристики, представляющие собой расход деталей со склада за соответствующий цикл.
Таблица 11.1
Динамика спроса в течение трех циклов расхода запасов
| 1 й цикл | 2 й цикл | 3 й цикл | ||||||
| День | Спрос, ед. | Всего с начала цикла | День | Спрос, ед. | Всего с начала цикла | День | Спрос, ед. | Всего с начала цикла |
| * | ||||||||
| * |
Проиллюстрируем возможные варианты прогнозов для одной реализации.
Пример 1. Воспользуемся первой реализацией. Допустим, что нам известны значения расхода деталей со склада за пять дней работы (табл. 11.2).
Таблица 11.2
Исходные данные и результаты расчета коэффициентов уравнения (11.2) при N=5
| ti, дн. | yi, ед. | 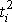
| yiti | Прогноз yi* | (yt–yi)2 |
Суммы 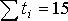
| 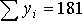
| 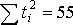
| 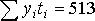
| 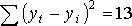
|
* Значения округлены
Выберем уравнение тренда yt в виде линейной зависимости:
(11.2)
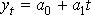
Расчет коэффициентов уравнения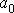 и
и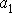 производится по формулам, полученных на основе метода наименьших квадратов:
производится по формулам, полученных на основе метода наименьших квадратов:
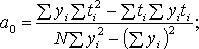 (11.3)
(11.3)
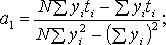 (11.4)
(11.4)
Находим: a0 = 45,2, a1 = –3,0. Таким образом, уравнение прогноза пишется в виде:
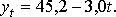 (11.5)
(11.5)
Для оценки границ интервального прогноза необходимо рассчитать среднее квадратичное отклонение σt:
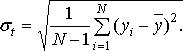 (11.6)
(11.6)
Подставляя значения в формулу, находим σt:
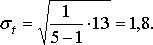 (11.7)
(11.7)
На основании полученных зависимостей yt и σt рассчитываются прогнозные оценки:
среднего времени расхода текущего запаса 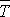 ;
;
страхового запаса yc с заданной доверительной вероятностью Р.
Расчет прогнозной величины среднего времени расхода производится по формуле
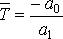 (11.8)
(11.8)
Приняв yt = 0, находим:
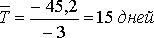
Для расчета страхового запаса воспользуемся формулой:
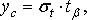 (11.9)
(11.9)
где σt – среднее квадратичное отклонение,
tβ – параметр нормального закона распределения, соответствующий доверительной вероятности β.
Параметр tβ определяет для нормального закона число средних квадратических отклонений, которые нужно отложить от центра рассеивания (влево и вправо) для того, чтобы вероятность попадания в полученный участок была равна β.
В нашем случае доверительные интервалы откладывают вверх и вниз от среднего значения уt..
В табл. 11.3 приведены наиболее часто встречающиеся в практических расчетах значения вероятности β и параметра tβ для нормального закона распределения.
Таблица 11.3
Доверительная вероятность β и параметр tβ нормального закона распределения
| β | tβ | β | tβ |
| 0,80 | 1,282 | 0,92 | 1,750 |
| 0,82 | 1,340 | 0,94 | 1,880 |
| 0,84 | 1,404 | 0,95 | 1,960 |
| 0,86 | 1,475 | 0,96 | 2,053 |
| 0,88 | 1,554 | 0,98 | 2,325 |
| 0,90 | 1,643 | 0,99 | 2,576 |
| 0,91 | 1,694 | 0,999 | 3,290 |
Страховой запас рассчитывается так же, как и границы интервального прогноза. Для рассматриваемого примера при доверительной вероятности β=0,9 находим по табл. 3.4.3 tβ = 1,643. Тогда величина страхового запаса составит:
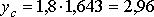
Примем yc=3,0.
На рис. 11.2 приведены границы интервального прогноза при β = 0,9.
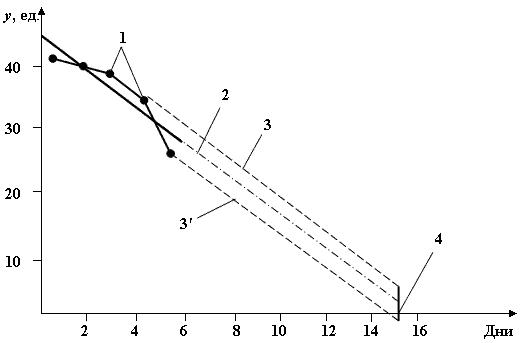
Рис. 11.2. Прогноз текущего расхода деталей на складе (N = 5):
1 – исходные данные; 2 – уравнение тренда;
3, 3' – границы интервального прогноза; 4 – время расхода запаса
Рассчитанное значение страхового запаса соответствует только одному дню наступления дефицита, а именно согласно прогнозу T = 15. Для учета возможных нарушений срока поставки необходимо также при расчете страхового запаса оценить влияние задержки, связанной с выполнением заказа, в частности с транспортировкой.
К сожалению, по одной реализации невозможно оценить вероятностный характер длительности функциональных циклов поставки. Однако можно предположить, что выявленная тенденция расхода запаса сохранится. В этом случае для оценки прогнозной величины страхового запаса можно воспользоваться формулой
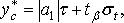 (11.10)
(11.10)
где τ – параметр, характеризующий количество дней задержки поставки заказа.
Рассчитаем величину страхового запаса при условии задержки на один день по сравнению с прогнозной оценкой T = 15 дней, т. е. на 16-й день:
Аналогично, при τ = 2 (17 день)
Для оценки вероятности отсутствия дефицита допускается, что отклонения ежедневного расхода деталей от среднего значения (тренда) подчиняются нормальному закону распределения. Тогда, пользуясь уравнением функции нормального закона, определяют вероятность отсутствия дефицита:
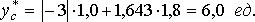 (11.11)
(11.11)
где yt – уравнение тренда;
σ – среднее квадратическое отклонение.
В табл. 11.4 приведен ряд значений функции Ф(х) и Р(х).
Таблица 11.4
Значения нормальной функции распределения Ф(х), вероятности Р(х) и параметра x
| x | Ф(х) | Р(х) | x | Ф(х) | Р(х) |
| 0,00 | 0,50 | 0,50 | -1,280 | 0,10 | 0,90 |
| -0,125 | 0,45 | 0,55 | -1,405 | 0,08 | 0,92 |
| -0,253 | 0,40 | 0,60 | -1,555 | 0,06 | 0,94 |
| -0385 | 0,35 | 0,65 | -1,645 | 0,05 | 0,95 |
| -0,525 | 0,30 | 0,70 | -1,75 | 0,04 | 0,96 |
| -0,675 | 0,25 | 0,75 | -2,05 | 0,02 | 0,98 |
| -0,842 | 0,20 | 0,80 | -2,30 | 0,01 | 0,99 |
| -1,037 | 0,15 | 0,85 | -3,10 | 0,001 | 0,999 |
Появление дефицита означает, что текущая величина запаса на складе равна нулю, т. е. у = 0.
Для определения вероятности отсутствия дефицита необходимо:
1. рассчитать 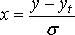 ,
,
2. по табл. 11.4 с помощью х найти Р(х).
Для рассматриваемого примера рассчитаем вероятности отсутствия дефицита деталей на складе на 13-й, 14-й и 15-й дни. Так, для T = 13 получаем:
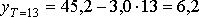
и
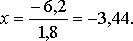
По табл. 11.4 находим РТ=13 > 0,999, т. е, вероятность отсутствия дефицита ничтожно мала.
Аналогично, для T = 14 получим yТ=14 = 3,2, x = –1,78, и вероятность отсутствия дефицита РТ=14 = 0,95.
Наконец, для T = 15 вероятность отсутствия дефицита Р = 0,5.
Следует подчеркнуть, что так же, как при оценке прогнозной величины страхового запаса, определение вероятности отсутствия дефицита по одной реализации справедливо только при строгом соблюдении сроков поставки. Если они не соблюдаются, то расчет должен проводиться с учетом рассеивания длительности функциональных циклов поставки.
В заключение определим ошибку прогноза среднего времени Т: 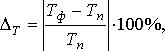 (11.12)
(11.12)
где Tф, Tп – соответственно фактическая и прогнозная продолжительность цикла, дн.
Получим:
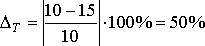
Ошибка прогноза велика, но это закономерно, так как нарушено одно из эмпирических правил экстраполяционного прогнозирования: между предпрогнозным периодом t и периодом упреждения (прогноза) τ = T – t должно соблюдаться соотношение:
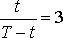 (11.13)
(11.13)
При T = 5 допустимая величина времени прогноза:
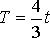
Следовательно, величина надежного прогноза соответствует T ≈ 7 дн. и период упреждения составляет τ = 2 дн.
Пример 2. Считается, что средняя длина функционального цикла расхода запасов составляет T = 10 дн. Тогда t = 7,5 дн.
Увеличим длину динамического ряда до N = 7 (рис. 11.3).
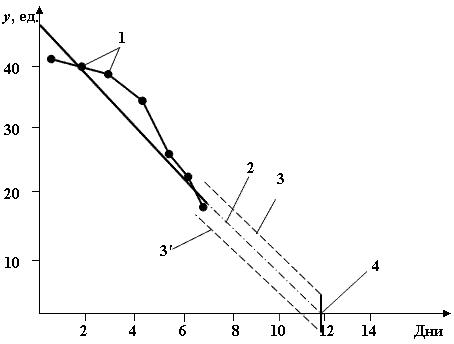
Рис. 11.3. Прогноз текущего расхода деталей на складе (N = 7):
1 – исходные данные; 2 – уравнение тренда;
3, 3' – границы интервального прогноза; 4 – время расхода запаса
Выполним расчеты аналогично примеру 1, полученные данные занесем в табл. 11.5.
Исходные данные и результаты расчета коэффициентов уравнения тренда при N=7
| ti | yi |
| yiti | yi | (yt–yi)2 |
| 43,1 | 4,41 | ||||
| 39,2 | 0,04 | ||||
| 35,3 | 7,29 | ||||
| 31,4 | 12,96 | ||||
| 27,6 | 0,25 | ||||
| 23,6 | 0,36 | ||||
| 19,7 | 0,49 | ||||
Суммы
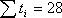
| 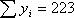
| 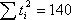
| 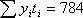
| 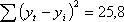
|
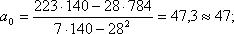 ,
, 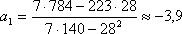
Получим уравнение тренда:
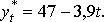
Соответственно, 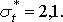
Рассчитаем среднее прогнозное время расхода запаса со склада
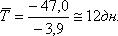
и ошибку прогноза:
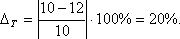
Рассчитаем величину страхового запаса yc для 12-го, 13-го и 14-го дней. Примем β = 0,95, т. е, tβ = 1,96. Тогда:
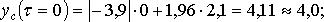
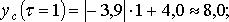
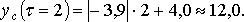
Определим вероятность дефицита на складе на 10-й день. Находим
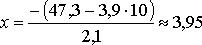 ;
;
по табл. 11.4 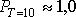 , т.е. наличие дефицита маловероятно. Аналогично, для
, т.е. наличие дефицита маловероятно. Аналогично, для 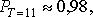 для
для 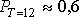 .
.
В заключение можно сделать следующее замечание: рассчитанные величины среднего запаса получены при условии, что наблюдающая величина дефицита и вариация ежедневного расхода – независимые величины. Несомненно, это допущение требует проверки.
Комбинированный прогноз. На формирование стратегии автотранспортного предприятия (АТП) на рынке влияют факторы как внешней, так и внутренней среды, в том числе определяющие состояние спроса на услуги. Основным является вопрос о потенциальных возможностях предприятия, определяемых технико-технологическими и организационно-финансовыми факторами среды. Принципиальное различие между предъявляемыми к перевозке грузами (или спросом) и провозными возможностями АТП состоит в том, что первое следует отнести к условиям внешней среды, т. е. «природе», состояние которой формируется под действием большого количества факторов и в подавляющем большинстве случаев не зависит от транспортной политики конкретного АТП (если рассматриваемое предприятие не является монополистом в данном сегменте рынка транспортных услуг), а второе определяется политикой и тактикой действий предприятия, не имея случайного характера, а, скорее, подчиняясь неким внутренним закономерностям. Таким образом, под влиянием случайных факторов объем перевозок представляет собой случайную величину, подчиняющуюся определенному закону или функции распределения F(Q). Введение функции распределения для описания состояния «природы» позволяет, согласно теории статистических решений, использовать вероятностные критерии принятия решений в условиях риска.
Что касается состояния АТП, то оно может быть представлено в виде различных стратегий Ai, каждая из которых количественно характеризуется числом автомобилей Ni и их провозными возможностями Wi.
Указанные стратегии Ai, являются дискретными величинами, если используется число автомобилей N, или непрерывными за счет варьирования показателей, входящих в расчет производительности автомобиля Wi.
Связь между Ai стратегией и объемом перевозок Qi определяется в виде матрицы (табл. 11.6), элементы которой (aij) отражают «выигрыш», получаемый АТП при выборе i-й стратегии.
Матрица возможных стратегий Ai АТП при различных объемах перевозок Qj («состояния природы») Таблица 11.6
| Стратегия АТП | Объëм перевозок | |||||
| Q1 | Q2 | ... | Qj | ... | Qn | |
| A1 | a11 | a12 | ... | a1j | ... | a1n |
| A2 | a21 | a22 | ... | a2j | ... | a2n |
| ... | ... | ... | ... | ... | ... | ... |
| Ai | ai1 | ai2 | ... | aij | ... | ain |
| ... | ... | ... | ... | ... | ... | ... |
| Am | am1 | am2 | ... | am | ... | amn |
В ряде работ, где предпринимались попытки использования теории статистических решений для конкретных хозяйственных объектов, в качестве элемента матрицы aij – «выигрыша» – использовались условные величины. В качестве «выигрыша» могут быть использованы различные экономические показатели: доход, прибыль и другие, а также показатели, способствующие усилению конкурентных или рыночных позиций, усилению влияния на клиентуру и укреплению имиджа предприятия, улучшению качества производимых услуг.
Возможны три соотношения между объемом перевозок Qi и стратегией предприятия А. Первое – 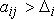 – состояние «выигрыша»; второе –
– состояние «выигрыша»; второе – 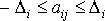 – нейтральное состояние; третье –
– нейтральное состояние; третье – 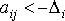 – состояние «проигрыша». Величина
– состояние «проигрыша». Величина 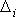 – вероятностное отклонение за счет случайного характера величин, определяющих значение элементов матрицы. Теоретически возможен вариант, когда области значений aij будут расположены иным образом, чем это показано на рис. 11.4.
– вероятностное отклонение за счет случайного характера величин, определяющих значение элементов матрицы. Теоретически возможен вариант, когда области значений aij будут расположены иным образом, чем это показано на рис. 11.4.
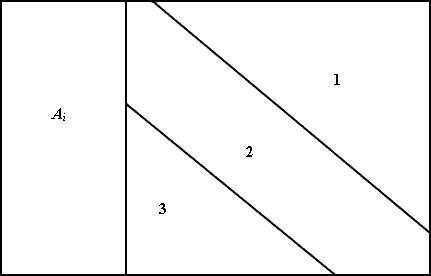
Рис. 11.4. Распределение на различные области матрицы стратегий АТП: 1 – «выигрыш», 2 – нейтральное состояние, 3 – «проигрыш»
В частности, введение оценки «упущенной выгоды» может изменить границы областей 1-3. Считается, что наилучшей стратегией A = Ai является та, при которой показатель Ai обращается в максимум:
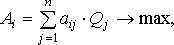 (11.14)
(11.14)
где Qj = F(Qj) – вероятность j-го состояния «природы».
Таким образом, оптимальная стратегия АТП может быть определена при наличии F(Qj) и матрицы стратегий aij.
Рассмотрим возможные варианты расчета F(Qj). Традиционно для количественной оценки прогноза Qj, используется метод экстраполяции по динамическим рядам с использованием полиномов различной степени.
Результаты прогноза представляются в виде среднего значения Q и дисперсии DQ, по которым определяется вид функции распределения F(Qj). Далее c использованием условия максимизации Ai выбираем стратегию АТП.
Основная трудность использования вышеописанной методики – это невысокая точность прогноза, Повышение точности может быть достигнуто за счет комбинированных методов прогноза, предусматривающих синтез двух и более прогнозных вариантов.
Каждый метод прогнозирования обладает определенной достоверностью, имеет свои преимущества и недостатки, Считается, что комбинированные методы прогнозирования (синтез прогнозов) позволяют компенсировать недостатки одних способов достоинствами других. На рис. 11.5 представлена блок-схема комбинированного прогноза для двух вариантов прогноза, один из которых – прогноз, выполненный эвристическим методом, основанным на статистической обработке мнений экспертов.
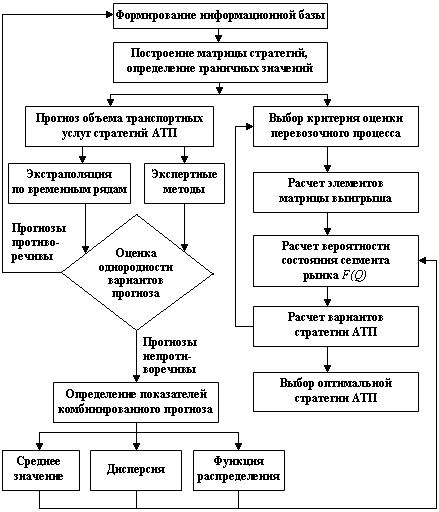
Рис. 11.5. Блок-схема выбора стратегии АТП
в целевом сегменте рынка транспортных услуг
Процедура получения экспертных оценок может быть формализована и представлена в виде блок-схемы (рис. 11.6).
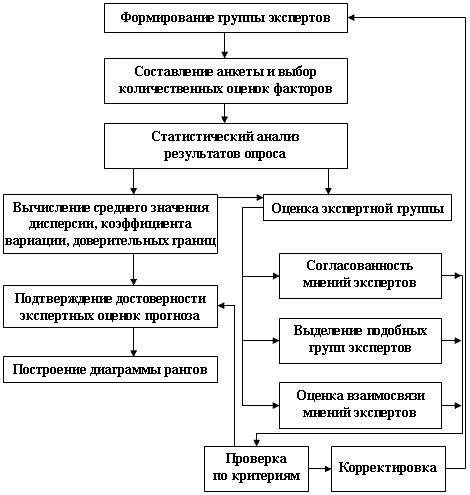
Рис. 11.6. Блок-схема прогноза на основе экспертных опросов
Рассмотрим некоторые блоки подробнее.
Формирование группы экспертов – важнейшая составляющая экспертного метода. Не останавливаясь подробно на вопросах персонального подбора, затронем только количественную сторону, а именно число экспертов. Известно, что при прогнозировании в целях минимизации расходов на прогноз стремятся привлекать минимальное число экспертов при условии обеспечения ошибки результата прогнозирования не более Е, где 0 < Е < 1. Поэтому рекомендуемое число экспертов может быть определено по формуле:
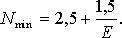 (11.15)
(11.15)
При подстановке предельных значений Е находим: 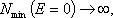
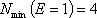
Таким образом, минимальное количество экспертов равно 4. Для определения максимальной численности экспертной группы используется неравенство:
 (11.16)
(11.16)
где Ki – компетентность i-го эксперта, рассчитываемая на основе анкеты самооценки;
Kmax – максимально возможная компетентность по используемой шкале компетентности экспертов.
Статистический анализ результатов опроса предусматривает проведение двух взаимосвязанных процедур: традиционной статистической обработки в виде средних значений, дисперсий и т. п., а также оценки всей экспертной группы – степени согласованности, взаимосвязи и других показателей мнений экспертов. Оценка группы экспертов проводится с использованием части полученных статистических оценок. Если последние не удовлетворяют соответствующим критериям, то в блок-схеме предусмотрена корректировка, которая приводит, в частности, к изменению состава экспертов и повторной процедуре опроса.
Методика статистической обработки данных включает следующие этапы:
1. Определение для каждого фактора суммы рангов:
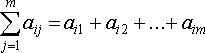 (11.17)
(11.17)
где aij – ранг, присвоенный j-м экспертом i -му фактору;
m – число экспертов.
2. Определение средней величины суммы рангов:
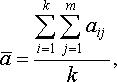 (11.18)
(11.18)
где k – число факторов.
3. Определение суммы квадратов отклонений:
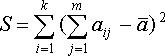 (11.19)
(11.19)
4. Определение коэффициента конкордации W, позволяющего оценить степень согласованности мнений экспертов (при отсутствии равных рангов):
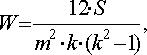 (11.20)
(11.20)
Если W существенно отличается от нуля, то можно полагать, что между оценками экспертов существует определенное согласие.
5. Оценка неслучайности согласия мнений экспертов производится с помощью критерия Пирсена по величине 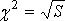 .при числе степени свободы n = k – 1 и заданном уровне значимости α:
.при числе степени свободы n = k – 1 и заданном уровне значимости α:
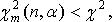 (11.21)
(11.21)
где  – табличное значение.
– табличное значение.
В случае соблюдения неравенства с доверительной вероятностью 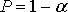 можно утверждать, что мнения экспертов относительно вероятности факторов согласуются неслучайно.
можно утверждать, что мнения экспертов относительно вероятности факторов согласуются неслучайно.
Представленный вариант получения прогноза на основе экспертных оценок является универсальным и в случае использования баллов заканчивается построением ранжированной диаграммы рангов.
Для перехода к конкретному прогнозу, в частности объема перевозок, последовательности расчета сводятся к следующему:
1. Составляется ряд интервальных значений Qj возможных объемов перевозок для рассматриваемого клиента; разбивка на n интервалов осуществляется на основе F(Qj).
2. Эксперты оценивают значимость каждого Qj с использованием баллов, шкала которых охватывает n интервалов, т.е. j = 1, 2, …, n.
3. Проводится статистическая обработка оценок экспертов, и после ранжирования каждому Qj присваивается новый номер в порядке убывания, т.е. интервалу Qj с наименьшей суммой баллов присваивается номер 1 и т.д.
4. Полагаем, что интервалу Qj соответствует наиболее правдоподобная гипотеза (П1), затем вторая ((П2) и т.д.
Вероятности гипотез (П1), (П2), …., (Пn) определяются по формуле:
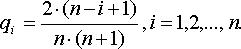 (11.22)
(11.22)
5. Восстанавливается функция распределения экспертного прогноза объема перевозок F(Qэj).
6. Для восстановленной «экспертной» функции находятся среднее значение и дисперсия Dэq.
Значения весовых коэффициентов для определения комбинированных оценок вероятностей каждого интервала находим по формулам:
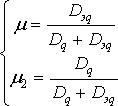 (11.23)
(11.23)
где μ1 и Dq – весовой коэффициент и дисперсия экстраполяционного прогноза;
μ2 и Dэq – весовой коэффициент и дисперсия экспертного прогноза.
7. Вероятности F(Qj) для комбинированного прогноза рассчитываются следующим образом:
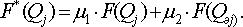 (11.24)
(11.24)
Вопросы для повторения
Классификация методов прогнозирования.
Суть прогноза текущего расхода деталей на складе.
Расчет страхового запаса.
Метод комбинированного прогноза.
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 437; Нарушение авторских прав?; Мы поможем в написании вашей работы!