КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Конфликты в конвейере и способы минимизации их влияния на производительность процессора
|
|
|
|
Значительное преимущество конвейерной обработки перед последовательной имеет место в идеальном конвейере, в котором отсутствуют конфликты и все команды выполняются друг за другом без перезагрузки конвейера. Наличие конфликтов снижает реальную производительность конвейера по сравнению с идеальным случаем.
Конфликты - это такие ситуации в конвейерной обработке, которые препятствуют выполнению очередной команды в предназначенном для нее такте.
Конфликты делятся на три группы:
- структурные,
- по управлению,
- по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Причины структурных конфликтов.
- Не полностью конвейерная структура процессора, при которой некоторые ступени отдельных команд выполняются более одного такта.
Пусть этап выполнения команды i+1 занимает 3 такта. Тогда диаграмма работы конвейера будет иметь вид, представленный в таблица 11.3.
| Таблица 11.3. | |||||||||||
| Команда | Такт | ||||||||||
| i | IF | ID | OR | EX | WB | ||||||
| i+1 | IF | ID | OR | EX | EX | EX | WB | ||||
| i+2 | IF | ID | OR | O | O | EX | WB | ||||
| i+3 | IF | ID | OR | O | O | EX | |||||
| i+4 | IF | ID | OR | O | O |
При этом в работе конвейера возникают так называемые "пузыри" (обработка команд i+2 и следующих за ней, начиная с такта 6), которые снижают производительность процессора.
Эту ситуацию можно было бы ликвидировать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки, так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение данного этапа (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и невозможности реализации на этой БИС других, функционально более важных, узлов. Так как представленная в таблица 11.3 ситуация возникает при реализации команд, относительно редко встречающихся в программе, то обычно разработчики процессоров ищут компромисс между увеличением длительности такта и усложнением того или иного устройства процессора.
- Недостаточное дублирование некоторых ресурсов.
Одним из типичных примеров служит конфликт из-за доступа к запоминающим устройствам. Из таблица 11.1 видно, что в случае, когда операнды и команды находятся в одном запоминающем устройстве, начиная с такта 3, работу конвейера придется постоянно приостанавливать, поскольку различные команды в одном и том же такте обращаются к памяти на считывание команды, выборку операнда, запись результата.
Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. Например, в современных микропроцессорах обычно разделяют кэш-память для хранения команд и кэш-память данных, а также используют многопортовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по одному каналу для записи, а по другому - для считывания информации. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium-4 предусмотрено 4 АЛУ для обработки целочисленных данных. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. В таблица 11.4 представлена последовательность выполнения команд в микропроцессоре, имеющем два конвейера, при условии, что команде К1 требуется 3 такта на этапе EX.
| Таблица 11.4. | |||||||||||||||
| Этап | Такт | ||||||||||||||
| IF | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K7 | K9 | K7 | K10 | K11 | K12 | |
| ID | K1 | K2 | K3 | K4 | K5 | K6 | K5 | K8 | K5 | K9 | K7 | K10 | |||
| OR | K1 | K2 | K3 | K4 | K3 | K6 | K3 | K8 | K5 | K9 | |||||
| EX | K1 | K2 | K1 | K4 | K1 | K6 | K3 | K8 | |||||||
| WB | K2 | K4 | K1 | K6 |
При этом команды будут завершаться в последовательности
К2-К4-К1-К6-...
Следовательно, для обеспечения правильной работы суперскалярного микропроцессора при возникновении затора в одном из конвейеров должны приостанавливать свою работу и другие. В противном случае может нарушиться исходный порядок завершения команд программы. Но такие приостановки существенно снижают быстродействие процессора. Разрешение этой ситуации состоит в том, чтобы дать возможность выполняться командам в одном конвейере вне зависимости от ситуации в других конвейерах. Это приводит к неупорядоченному выполнению команд. При этом команды, стоящие в программе позже, могут завершиться ранее команд, стоящих впереди. Аппаратные средства микропроцессора должны гарантировать, что результаты выполненных команд будут записаны в приемник в том порядке, в котором команды записаны в программе. Для этого в микропроцессоре результаты этапа выполнения команды обычно сохраняются в специальном буфере восстановления последовательности команд. Запись результата очередной команды из этого буфера в приемник результата проводится лишь после того, как выполнены все предшествующие команды и записаны их результаты.
Конфликты по управлению возникают при конвейеризации команд переходов и других команд, изменяющих значение счетчика команд.
Суть конфликтов этой группы наиболее удобно проиллюстрировать на примере команд условного перехода. Пусть в программе, представленной в таблица 11.1, команда i+1 является командой условного перехода, формирующей адрес следующей команды в зависимости от результата выполнения команды i. Команда i завершит свое выполнение в такте 5. В то же время команда условного перехода уже в такте 3 должна прочитать необходимые ей признаки, чтобы правильно сформировать адрес следующей команды. Если конвейер имеет большую глубину (например, 20 ступеней), то промежуток времени между формированием признака результата и тактом, где он анализируется, может быть еще большим. В инженерных задачах примерно каждая шестая команда является командой условного перехода, поэтому приостановки конвейера при выполнении команд переходов до определения истинного направления перехода существенно скажутся на производительности процессора.
Наиболее эффективным методом снижения потерь от конфликтов по управлению служит предсказание переходов. Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется. Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение). Однако так как направление перехода может быть предсказано неверно, то получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB), а накапливаются в специальном буфере результатов.
Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, а выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, то буфер результатов очищается. Также очищается и конвейер, содержащий команды, находящиеся на разных этапах обработки, следующие за командой условного перехода. При этом аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы. Так как конвейерная обработка эффективна при большом числе последовательно выполненных команд, то перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается или программистом с помощью специальных средств, имеющихся в некоторых языках программирования, по опыту выполнения аналогичных программ либо результатам тестового выполнения программы, или программой-компилятором по заложенным в ней алгоритмам.
Методы динамического прогнозирования учитывают направления переходов, реализовывавшиеся этой командой при выполнении программы. Например, подсчитывается количество переходов, выполненных ранее по тому или иному направлению, и на основании этого определяется направление перехода при следующем выполнении данной команды.
В современных микропроцессорах вероятность правильного предсказания направления переходов достигает 90-95 %.
Конфликты по данным возникают в случаях, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
При обсуждении этих конфликтов будем предполагать, что команда i предшествует команде j.
Существует несколько типов конфликтов по данным.
1. Конфликты типа RAW (Read After Write): команда j пытается прочитать операнд прежде, чем команда i запишет на это место свой результат. При этом команда j может получить некорректное старое значение операнда.
Проиллюстрируем этот тип конфликта на примере выполнения команд, представленных в таблица 11.1. Пусть выполняемые команды имеют следующий вид:
i) ADD R1,R2; R1 = R1+R2i+1=j) SUB R3,R1; R3 = R3-R1Команда i изменит состояние регистра R1 в такте 5. Но команда i+1 должна прочитать значение операнда R1 в такте 4. Если не приняты специальные меры, то из регистра R1 будет прочитано значение, которое было в нем до выполнения команды i.
Уменьшение влияния конфликта типа RAW обеспечивается методом обхода (продвижения) данных. В этом случае результаты, полученные на выходах исполнительных устройств, помимо входов приемника результата передаются также на входы всех исполнительных устройств микропроцессора. Если устройство управления обнаруживает, что данный результат требуется одной из последующих команд в качестве операнда, то он сразу же, параллельно с записью в приемник результата, передается на вход исполнительного устройства для использования следующей командой.
Конфликты типа RAW обусловлены именно конвейерной организацией обработки команд.
Главной причиной двух других типов конфликтов по данным является возможность неупорядоченного выполнения команд в современных микропроцессорах, то есть выполнение команд не в том порядке, в котором они записаны в программе.
2. Конфликты типа WAR (Write After Read): команда j пытается записать результат в приемник, прежде чем он считается оттуда командой i, При этом команда i может получить некорректное новое значение операнда:
3. i) ADD R1,R2i+1 =j) SUB R2,R3Этот конфликт возникнет в случае, если команда j вследствие неупорядоченного выполнения завершится раньше, чем команда i прочитает старое содержимое регистра R2.
4. Конфликты типа WAW (Write After Write): команда j пытается записать результат в приемник, прежде чем в этот же приемник будет записан результат выполнения команды i, то есть запись заканчивается в неверном порядке, оставляя в приемнике результата значение, записанное командой i:
5. i) ADD R1,R26....j) SUB R1,R3Устранение конфликтов по данным типов WAR и WAW достигается путем отказа от неупорядоченного исполнения команд, но чаще всего путем введения буфера восстановления последовательности команд.
Как отмечалось выше, наличие конфликтов приводит к значительному снижению производительности микропроцессора. Определенные типы конфликтов требуют приостановки конвейера. При этом останавливается выполнение всех команд, находящихся на различных стадиях обработки (до 20 ти команд в Pentium-4). Другие конфликты, например, при неверном предсказанном направлении перехода, ведут к необходимости полной перезагрузки конвейера. Потери будут тем больше, чем более длинный конвейер используется в микропроцессоре. Такая ситуация явилась одной из причин сокращения числа ступеней в микропроцессорах последних моделей. Так, в микропроцессоре Itanium конвейер содержит всего 10 ступеней. При этом его тактовая частота составляет около 1 МГц [[2]]. Однако на каждой ступени выполняется больше функциональных действий, чем в Pentium-4.
| 12. Лекция: Организация работы мультипрограммных ЭВМ | |

| |

| |

| |
| Страницы: 1 | 2 | вопросы |» | | учебники | для печати и PDA | ZIP |
|
| |
| Если Вы заметили ошибку - сообщите нам, или выделите ее и нажмите Ctrl+Enter | |
|
| |
| Рассматриваются основные понятия мультипрограммного режима работы ЭВМ, аппаратные и программные средства, обеспечивающие работу ЭВМ в этом режиме, показатели, характеризующие мультипрограммный режим работы, и их зависимость от коэффициента мультипрограммирования. | |
|
| |
|
| |
|
| |
Основные характеристики мультипрограммного режима работы ЭВМ
Мультипрограммным режимом работы (многозадачностью) называется такой способ организации работы системы, при котором в ее памяти одновременно содержатся программы и данные для выполнения нескольких процессов обработки информации (задач) [[4]]. При этом должна обеспечиваться взаимная защита программ и данных, относящихся к различным задачам, а также возможность перехода от выполнения одной задачи к другой (переключение задач).
Мультипрограммирование позволяет повысить производительность работы ЭВМ за счет более эффективного использования ее ресурсов.
Базовыми понятиями мультипрограммного режима функционирования ЭВМ являются процесс и ресурс [[12]]
В строгом понимании процесс - это система действий, реализующая определенную функцию в вычислительной системе и оформленная так, что управляющая программа вычислительной системы может перераспределять ресурсы этой системы в целях обеспечения мультипрограммирования. То есть процесс - это некоторая деятельность, связанная с исполнением программы на процессоре.
Процесс может находиться в следующих состояниях:
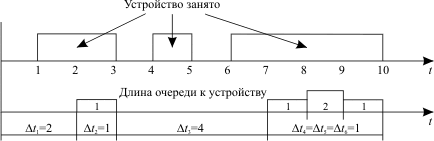 Рис. 12.1. Оценка основных показателей использования аппаратных ресурсов
Тогда рассмотренные выше показатели работы этого устройства будут следующими: Рис. 12.1. Оценка основных показателей использования аппаратных ресурсов
Тогда рассмотренные выше показатели работы этого устройства будут следующими:
|
Работа мультипрограммной ЭВМ в большой степени зависит от коэффициента мультипрограммирования (Км) - количества программ, которое может одновременно обрабатываться в мультипрограммном режиме.
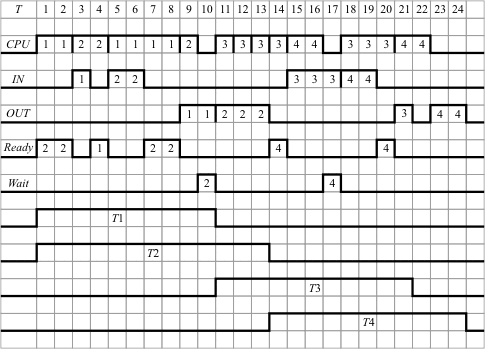
Рис. 12.2. Порядок выполнение программ в мультипрограммной ЭВМ при Км = 2
Пример выполнения программ в мультипрограммном режиме при Км=2 представлен на рис. 12.2. Предполагается, что выполнение каждой программы включает следующую последовательность действий: счет1 - ввод - счет2 - вывод. Счет выполняется на процессоре (CPU), для ввода и вывода данных используются отдельные внешние устройства (IN и OUT). На графике помечены номера программ, которые в данный момент занимают тот или иной ресурс.
| Таблица 12.1. | ||||
| Программа | CPU1 | IN | CPU2 | OUT |
Если построить аналогичные графики для ЭВМ, работающей с различными коэффициентами мультипрограммирования, то получим следующие сравнительные характеристики работы ЭВМ для рассматриваемого пакета программ (таблица 12.2).
| Таблица 12.2. | |||
| Характеристика | Км = 1 | Км = 2 | Км = 3 |
| Время выполнения программы Т1 | |||
| Время выполнения программы Т2 | |||
| Время выполнения программы Т3 | |||
| Время выполнения программы Т4 | |||
| Время выполнения всех программ (Т) | |||
| Пропускная способность (П) | 0,11 | 0,17 | 0,18 |
| kCPU | 0,56 | 0,83 | 0,91 |
| kIN | 0,22 | 0,33 | 0,36 |
| kOUT | 0,22 | 0,33 | 0,36 |
Под временем выполнения программы понимается время, прошедшее от начала выполнения программы или ее постановки в очередь к процессору, до ее завершения, а время выполнения всех программ определяется моментом завершения выполнения последней программы пакета.
При увеличении коэффициента мультипрограммирования изменение значений показателей эффективности зависит от того, в каком состоянии находится система: перегрузки или недогрузки. Если какие-либо ресурсы ЭВМ используются достаточно интенсивно, то добавление новой программы, активно использующей эти ресурсы, будет малоэффективным для увеличения пропускной способности ЭВМ. Очевидно, что зависимость пропускной способности (П), времени выполнения каждой программы (Тi) и времени выполнения всего пакета программ (Т) от коэффициента мультипрограммирования будет иметь вид, представленный на рис. 12.3.
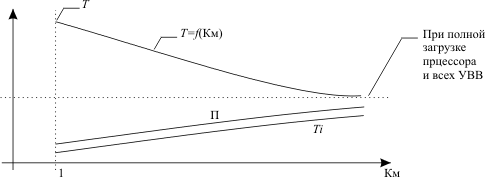
Рис. 12.3. Зависимость основных характеристик работы мультипрограммной ЭВМ от коэффициента мультипрограммирования
На изменение эффективности работы мультипрограммной ЭВМ может повлиять назначение различных приоритетов выполняемым программам. Перераспределение приоритетов может привести как к увеличению, так и к снижению пропускной способности ЭВМ. Конкретный результат зависит от характеристик выполняемых программ. В частности, если в составе мультипрограммной смеси имеется единственная программа, надолго занимающая процессор, то увеличение ее приоритета понизит, а уменьшение - повысит пропускную способность ЭВМ. Это объясняется тем, что выполнение программ, обладающих меньшим приоритетом, чем рассматриваемая, фактически блокируется из-за недоступности процессора. Аналогичная ситуация может сложиться и в отношении других совместно используемых ресурсов. Особое значение при этом имеют те из них, которые являются наиболее дефицитными, то есть имеют наибольший коэффициент загрузки и наибольшую среднюю длину очереди. Как правило, наиболее высокий приоритет назначается тем программам, которые в состоянии быстро освободить наиболее дефицитный ресурс. Такого рода проблемы решаются в рамках теории расписаний. При этом поиск решения зачастую сводится к полному перебору вариантов. Ввиду сложности полной теоретической оценки всех возможных вариантов, на практике широко используются различные эвристические алгоритмы, дающие не оптимальные, а рациональные решения.
В мультипрограммной ЭВМ ресурсы могут распределяться как на статической, так и на динамической основе. В первом случае ресурсы распределяются до момента порождения процесса и являются для него постоянными. Освобождение ресурсов, занятых каким-либо процессом, происходит только в момент окончания этого процесса. При динамическом распределении ресурсы выделяются процессу по мере его развития.
Распределение на статической основе способствует наиболее быстрому развитию процессов в системе с момента их порождения. Распределение же ресурсов на динамической основе позволяет обеспечить эффективное использование ресурсов с точки зрения минимизации их простоев.
Схема статического распределения используется в том случае, когда необходимо гарантировать выполнение процесса с момента его порождения. В качестве недостатка этого подхода следует отметить возможность длительных задержек заявок на порождение процесса с момента поступления таких заявок в систему, так как необходимо ожидать освобождения всех требуемых заявке ресурсов и только при наличии их полного состава порождать процесс. Часто распределение ресурсов с использованием исключительно статического принципа приводит фактически к однопрограммному режиму работы.
При динамическом распределении стремление уменьшить простои ресурсов приводит к увеличению сложности системы распределения ресурсов и, как следствие, к увеличению системных затрат на управление процессами. Поэтому необходим компромисс между сложностью алгоритмов планирования распределения ресурсов и эффективностью выполнения пакета задач.
Ресурсы разделяются на физические и виртуальные.
Под физическим понимают ресурс, который реально существует и при распределении его между пользователями обладает всеми присущими ему физическими характеристиками.
Виртуальный ресурс - это некая модель, которая строится на базе физического ресурса, имеет расширенные функциональные возможности по отношению к физическому ресурсу, на базе которого он создан, или обладает некоторыми дополнительными свойствами, которых физический ресурс не имеет.
Например, расширенные функциональные возможности имеет виртуальная память, представляющаяся как запоминающее устройство, имеющее больший объем, чем физическая. Дополнительные свойства имеет виртуальный процессор, одновременно обрабатывающий несколько задач.
| 13. Лекция: Дисциплины распределения ресурсов и основные режимы работы мультипрограммной ЭВМ | |
|
| |
|
| |
|
| |
| Страницы: 1 | 2 | вопросы |» | | учебники | для печати и PDA | ZIP |
|
| |
| Если Вы заметили ошибку - сообщите нам, или выделите ее и нажмите Ctrl+Enter | |
|
| |
| Рассматриваются одноочередные и многоочередные дисциплины распределения ресурсов, а также основные режимы работы мультипрограммной ЭВМ. | |
|
| |
|
| |
|
| |
Дисциплины распределения ресурсов мультипрограммной ЭВМ
Дисциплины распределения ресурсов (ДРР) - весьма важный показатель, влияющий на эффективность работы ЭВМ. Применение той или иной дисциплины распределения зависит от особенностей использования данного ресурса, критериев оценки эффективности работы системы, а также от сложности реализации данной ДРР [[12]]
Одноочередные дисциплины
1. FIFO (First In - First Out) - первый пришел - первый обслужен (рис. 13.1).
 Рис. 13.1. Схема распределения ресурса по дисциплине FIFO
Схема доступа - очередь.
Широко используется в качестве как самостоятельной дисциплины распределения, так и составной части более сложных дисциплин.
Время нахождения в очереди длинных (то есть требующих большого времени обслуживания) и коротких запросов зависит только от момента их поступления.
2. LIFO (Last In - First Out) - последний пришел - первый обслужен (рис. 13.2). Рис. 13.1. Схема распределения ресурса по дисциплине FIFO
Схема доступа - очередь.
Широко используется в качестве как самостоятельной дисциплины распределения, так и составной части более сложных дисциплин.
Время нахождения в очереди длинных (то есть требующих большого времени обслуживания) и коротких запросов зависит только от момента их поступления.
2. LIFO (Last In - First Out) - последний пришел - первый обслужен (рис. 13.2).
 Рис. 13.2. Схема распределения ресурса по дисциплине LIFO
Схема доступа - стек.
3. Круговой циклический алгоритм (рис. 13.3). Рис. 13.2. Схема распределения ресурса по дисциплине LIFO
Схема доступа - стек.
3. Круговой циклический алгоритм (рис. 13.3).
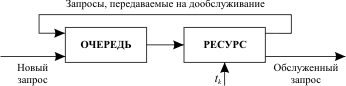 Рис. 13.3. Схема распределения ресурса по круговому циклическому алгоритму
Запрос обслуживается в течение кванта времени tk. Если за это время обслуживание не завершено, то запрос передается в конец входной очереди на дообслуживание.
Здесь короткие запросы находятся в очереди меньшее время, чем длинные.
Многоочередные дисциплины
Базовый вариант многоочередной дисциплины обслуживания представлен на рис. 13.4. Рис. 13.3. Схема распределения ресурса по круговому циклическому алгоритму
Запрос обслуживается в течение кванта времени tk. Если за это время обслуживание не завершено, то запрос передается в конец входной очереди на дообслуживание.
Здесь короткие запросы находятся в очереди меньшее время, чем длинные.
Многоочередные дисциплины
Базовый вариант многоочередной дисциплины обслуживания представлен на рис. 13.4.
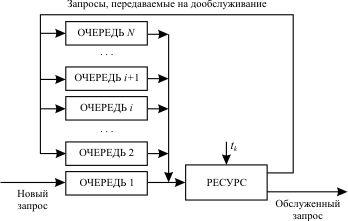 Рис. 13.4. Схема распределения ресурса при многоочередной дисциплине обслуживания
Основа дисциплины - круговой циклический алгоритм.
Все новые запросы поступают в очередь 1.
Время, выделяемое на обслуживание любого запроса, равно длительности кванта tk. Если запрос обслужен за это время, то он покидает систему, а если нет, то по истечении выделенного кванта времени он поступает в конец очереди i+1.
На обслуживание выбирается запрос из очереди i, только если очереди 1,…, i-1 пусты.
Таким образом, длинные запросы поступают сначала в очередь 1, затем постепенно доходят до очереди N и здесь обслуживаются до конца либо по дисциплине FIFO, либо по круговому циклическому алгоритму.
Модификации базового варианта многоочередной дисциплины обслуживания запросов.
1. Выделяемый программе квант времени на обслуживание возрастает с увеличением номера очереди обычно по правилу
tki = 2i-1 · tk
где tk - квант времени, выделяемый для программ из очереди 1.
Такая дисциплина обслуживания наиболее благоприятна коротким программам, хотя явного указания приоритетов программ здесь нет. Степень благоприятствования тем выше, чем меньше tk. Однако уменьшение длительности кванта ведет к увеличению накладных расходов, необходимых для перераспределения ресурса между программами.
Данная ДРР может работать как с относительными, так и с абсолютными приоритетами программ. Рис. 13.4. Схема распределения ресурса при многоочередной дисциплине обслуживания
Основа дисциплины - круговой циклический алгоритм.
Все новые запросы поступают в очередь 1.
Время, выделяемое на обслуживание любого запроса, равно длительности кванта tk. Если запрос обслужен за это время, то он покидает систему, а если нет, то по истечении выделенного кванта времени он поступает в конец очереди i+1.
На обслуживание выбирается запрос из очереди i, только если очереди 1,…, i-1 пусты.
Таким образом, длинные запросы поступают сначала в очередь 1, затем постепенно доходят до очереди N и здесь обслуживаются до конца либо по дисциплине FIFO, либо по круговому циклическому алгоритму.
Модификации базового варианта многоочередной дисциплины обслуживания запросов.
1. Выделяемый программе квант времени на обслуживание возрастает с увеличением номера очереди обычно по правилу
tki = 2i-1 · tk
где tk - квант времени, выделяемый для программ из очереди 1.
Такая дисциплина обслуживания наиболее благоприятна коротким программам, хотя явного указания приоритетов программ здесь нет. Степень благоприятствования тем выше, чем меньше tk. Однако уменьшение длительности кванта ведет к увеличению накладных расходов, необходимых для перераспределения ресурса между программами.
Данная ДРР может работать как с относительными, так и с абсолютными приоритетами программ.
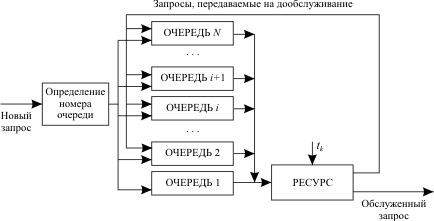 Рис. 13.5. Схема распределения ресурса при многоочередной дисциплине обслуживания со статическим указанием приоритетов программ
Эта дисциплина позволяет сократить количество системных переключений за счет того, что программам, требующим большего времени решения, будут предоставляться достаточно большие кванты времени уже при первом занятии ими ресурса (нерационально программе, которая требует для своего решения 1 час времени, первоначально выделять квант в 1 мс). Рис. 13.5. Схема распределения ресурса при многоочередной дисциплине обслуживания со статическим указанием приоритетов программ
Эта дисциплина позволяет сократить количество системных переключений за счет того, что программам, требующим большего времени решения, будут предоставляться достаточно большие кванты времени уже при первом занятии ими ресурса (нерационально программе, которая требует для своего решения 1 час времени, первоначально выделять квант в 1 мс).
|
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 826; Нарушение авторских прав?; Мы поможем в написании вашей работы!