КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Системный interface
|
|
|
|
Классификация простейших процессоров по отношению к используемым регистрам.
1. Процессоры с аккумуляторами
2. Процессоры с регистрами общего назначения (РОН)
3. Процессоры со стековой организацией
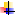 процессоры с аккумуляторами – имеется регистр команд, счётчик команд, регистр состояний, регистр адреса, аккумулятор, буферный регистр (для хранения и пересылки данных)
процессоры с аккумуляторами – имеется регистр команд, счётчик команд, регистр состояний, регистр адреса, аккумулятор, буферный регистр (для хранения и пересылки данных)
- все арифметические и логические операции выполняются с использованием аккумуляторов
- результат всегда помещается в аккумулятор, из него не извлекается и второй операнд
- для повышения производительности в такие процессоры вводят дополнительные регистры
- однако пока эти регистры остаются специализированными это процессоры с аккумуляторами
регистры общего назначения – универсальные регистры
- результат может быть записан в любой из РОН, в РОНах могут находиться и сами операнды
- использование РОНов позволяет значительно уменьшить число обращений к ОЗУ
стековая организация - с такой организацией нет ни аккумулятрных ни РОНов
- помимо регистра команд имеется программно доступный счётчик команд, регистр состояния, верхние регистры стека и указатели стека
- вся память разделена на стек и память для хранения команды данных
- подобная классификация условна, с одной стороны любой процессор с РОН может моделировать процессор с аккумуляторной и со стековой организацией
Рассмотрим структуру процессора подобного процессору mini-computer PDP-11 DEC
РА – регистр адреса
РК – регистр команд
Имеются 2 буферных регистра для временного хранения операндов
· управляющие сигналы управляют работой процессора
· это упрощённая схема – на ней не показаны шинные формирователи, через которые адреса данного управляющего сигнала выходят на системный интерфейс и блок прерывания
- ADD R0, R1
- ADD # 1000, R0 – непосредственная адресация
- следующая управляющая команда находится в счётчике, который пересылается через внутреннюю шину данных в РА, а также и в R1
- на шине управления – сигнал чтения
- на адресном интерфейсе – адрес команды
- по шине данных → на внутреннюю шину и оседает в регистре команд; в это время содержимое БР1 → АЛУ к нему автоматически суммируется 2 и результат из АЛУ по внутренней шине процессора пересылается в СК (счётчик) (R7); УУ дешифрует команду и выясняет, что речь идёт об операции сложения R0 и R1 – содержимое регистра R1 и R0 → в R2; содержимое БР1 и БР2 → АЛУ – выполняется сложение и результат пересылается в регистр R1
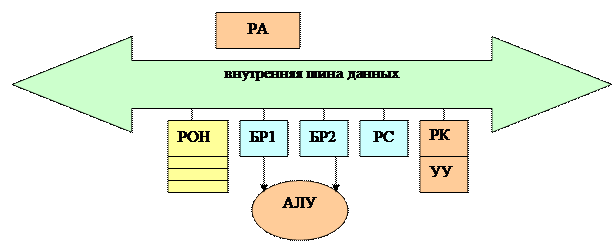
- каждая команда порождает выполнение последовательности микрокоманд; для выполнения одной микрокоманды используются те или иные устройства процессора, но, как правило, не все; то есть часть устройств периодически простаивает, поэтому для устранения этого недостатка и следовательно для повышения производительности процессора, во многих современных процессорах команды выполняются в конвейерном режиме - в этом режиме процессор выполняет не одну, а сразу несколько команд; они находятся в разной стадии выполнения, поскольку используют одни и те же устройства процессора
- в Pentium используются 2 конвейера
- в Pentium Pro 3 конвейера
- наличие даже одного 5-ти ступенчатого конвейера обеспечивает 486 процессору выигрыш со многими однотактными cisc – процессорами
- под системный интерфейсом понимают совокупность системной шины, связывающей процессор с памятью и контролерами внешних устройств; электрических схем, служащих для согласования, преобразования и управления сигналами машины; а также протоколов (унифицированных алгоритмов) обмена информации между устройствами компьютера по шине
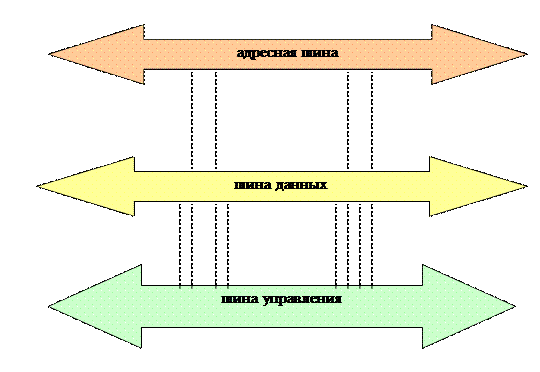
Функциональная системная шина – состоит из адресной шины, шины данных и шины управления (под шиной понимают группу линий, для передачи логически связанных сигналов).
Адресная шина – служит для передачи адреса элемента данных, который далее будет передаваться по шине данных.
· в простейших вычислительных устройствах (компьютер не относится) только процессор может формировать адрес (выставлять адрес на адресную шину); в этом случае адресная шина является однонаправленной
· в более сложных вычислительных системах (PC) помимо процессора адрес могут выставлять контролёр прямого доступа в память и контролёр внешних устройств, если они имеют средства управления шинами
· разрядность адресной шины определяется объёмом физической памяти
Шина данных – является двунаправленной (данные передаются в 2 направлениях, но не одновременно – временное мультиплексирование).
Шина управления – служит для передачи управляющих сигналов, которые используются для синхронизации устройств и указания типа операции выполняемых этими устройствами; для каждого управляющего сигнала существует своя индивидуальная линия на шине управления
Управляющие сигналы:
· ввод/вывод – внешние устройства
· чтение/запись – операционная память
· запрос на прерывание
· запрос на прямой доступ к памяти
· предоставление прямого доступа к памяти
Эти сигналы могут генерироваться процессором, контролером шины по сигналам процессора, контролером прямого доступа к памяти (ПДП), контролер прерывания → контролер большинства современных внешних устройств.
- В вычислительных системах используются различные системные интерфейсы и различные шинные структуры
- Если процессор имеет отдельные шины (адреса данных и управления) для организации обмена с памятью и аналогичные шины для обмена с внешними устройствами – системный интерфейс с раздельными шинами.
- В вычислительных системах также используются системные интерфейсы с изолированными и общими шинами; если для организации обмена данных с внешними устройствами используются специальные команды ввода/вывода и соответственно управляющие сигналы ввод/вывод, а для обмена с памятью команды пересылки данных и управляющие сигналы чтение/запись, то это системный интерфейс с изолированной шиной.
Системный интерфейс с общей шиной:
· таким образом один и тот же адрес может быть либо адресом регистра контролера внешнего устройства, либо адресом ячейки ОП, также изолированная шина используется в IBM
· если из системы команд процессора исключить команды ввода/вывода, то можно существенно упростить и структуру процессора и структуру интерфейса: в этом случае часть адресного пространства памяти отводится под адреса регистров контроллеров внешних устройств и для организации ввода/вывода используются команды пересылки данных, и соответственно управляющий сигнал чтения/записи
· системный интерфейс с общей шиной был разработан фирмой DEC в 1970 г.
· системный интерфейс с изолированными или общими шинами можно упростить за счёт объединения адресной шины и шины данных в единую адресно-информационную шину → мультиплексированная шина (или шина с мультиплексированием адресов и данных)
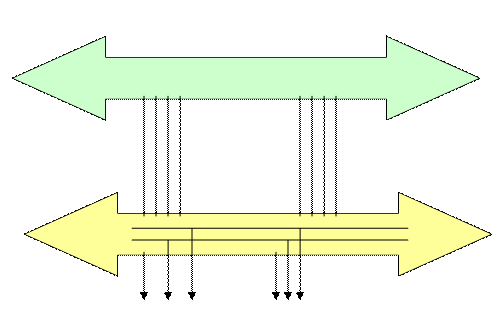
- заметно снижается пропускная способность системного интерфейса и соответственно уменьшается производительность компьютера
Многие шины могут быть синхронными и асинхронными:
- на синхронных шинах все операции выполняются по тактовым импульсам синхрогенератора
- на асинхронных шинах все операции синхронизируются на асинхронных шинах управляющими сигналами, передаваемыми взаимодействующими устройствами
Основные шины системного интерфейса ПК:
1. Системная шина (то, что соединяет процессор с контроллером памяти)
2. Локальная шина памяти (между котроллером памяти и самой памятью)
3. Шины расширения ввод/вывод
| название | ISA | ISA | EISA | MCA | MCA | VLB | PCI |
| разрядность | 32/64 | ||||||
| пропускная способность (Мбит/с) | 133/266 266/66.6 | ||||||
| частота синхронизации (МГц) | 8.33 | 33.3 | 33.3/66.6 |
4. LPC bus – шина с малым числом выводов (x – bus)
5. USB 2.0 – универсальная последовательная шина (480 Мбит/с)
6. SM bus – шина системного управления
7. ATA – интерфейсная шина (100 Мбит/с)
8. SATA – интерфейсная шина (150, 300 Мбит/с)
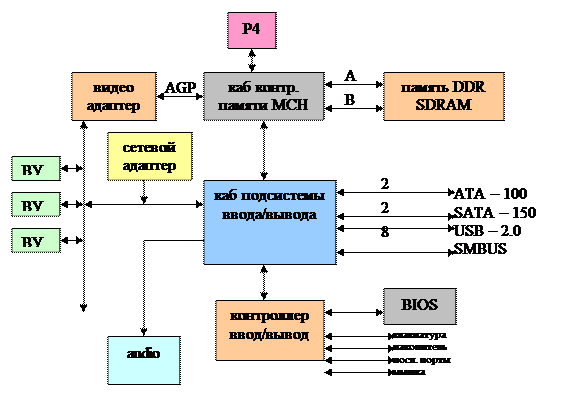
- I865PE (чипсет – это набор больших интегральных схем, обеспечивающих взаимодействие основных компонент компьютера)
- начиная с 810, интеловские чипсеты имею кабовую архитектуру
- каб – устройство, обеспечивающее передачу информации между подключенными к нему шинами
7.8. Обмен данными с внешними устройствами ввода/вывода.
1. возможна организация команд ввода/вывода с использованием специальных команд ввода/вывода
2. по аналогии с обращением к памяти
· упрощается схема взаимодействия системного интерфейса с изолированными шинами, с контроллером внешних устройств

- при вводе данных из внешнего устройства процессор выставляет на адресную шину адрес регистра данных контроллера ВУ и с помощью единичного сигнала «ввод» информирует контроллер ВУ о типе операции, которую оно должно выполнить → устройство, обнаружив появление сигнала «ввод», выставляет на шину данных байт слова или двойное слово (содержимое регистра данных), полученное от внешнего устройства
- для синхронизации процессора и контроллера ВУ может использоваться сигнал готовности ВУ → процессор, обнаружив появление сигнала «готовность ВУ», считывает данные с шины данных и снимает сигнал «ввод», на этом цикл обмена заканчивается
- принцип обмена данными, при котором сигналы, посланные активным устройством (процессору в данном случае) подтверждаются сигналами пассивного устройства называется колетированием
- активное устройство называют задатчиком, а пассивное исполнителем
- устройство, осуществляющее ввод/вывод с использованием специальных команд и сигналов, называется устройством с отображением на пространство ввод/вывод
- устройство, осуществляющее ввод/вывод по аналогии с обращением в память называется устройством с отображением на память
- в контроллере всегда имеется группа регистров – адресуемые регистры
Регистры контроллера внешних устройств:
- регистры данных (если устройство осуществляет однонаправленную передачу – 1 регистр: если двунаправленную – 2 регистра: регистр входных и регистр выходных данных)
- через регистр выходных данных данные вводятся в устройство компьютера
- через выходной регистр – данные выводятся
- регистры состояния и управления
· регистр состояния (один или несколько) доступен в режиме чтения и сохраняет в своих разрядах информацию о текущем состоянии внешнего устройства
· регистр управления (один или несколько) работает в режиме записи и служит для приёма команд управления внешними устройствами
· регистры в состоянии управления, также как и регистры данных доступны только через шину данных; другими словами часть управляющей информации в компьютере передаётся не по шине управления, а по шине данных;
· такая организация передачи управления информации обусловлена тем, что каждое внешнее устройство имеет целый набор собственных сигналов и команд, а потому предусмотреть для них соответствующие линии на шине управления системного интерфейса не представляет возможным, очевидно, что это существенно замедляет обмен данными с внешним устройством
Нарисуем упрощённую блок-схему контроллера внешнего устройства для системного интерфейса с изолированной шиной:

- логика управления обеспечивает дешифрацию регистров контроллеров; приём управляющих сигналов системного интерфейса (ввод/вывод); формирование на их основе внутренних управляющих сигналов, кроме того, она может генерировать сигнал готовности ВУ; запрос на прерывание; запрос на прямой доступ к памяти
- внутренние управляющие сигналы определяют, в какой из регистров контроллера будет подключён через приемо-передатчик шины к шине данных
Различают 3 основных способа организации ввода/вывода:
- программно – управляющий обмен
- обмен в режиме прерывания
- обмен в режиме прямого доступа к памяти
программно – управляющий обмен – это передача данных по инициативе и под управлением программы, осуществляющей ввод/вывод
Такой обмен может быть реализован в 2 режимах:
а) обмен в синхронном режиме – обмен с безусловной передачей данных (без контроля приёма данных);
· синхронный режим используется для обмена с такими ВУ, для которых точно известно время выполнения одной операции ввода/вывода;
· программа, управляющая обменом, должна давать команды на приём или передачу данных с временным интервалом не меньшим, чем время необходимое для выполнения одной операции
· если команды и данные будут передаваться в более быстром темпе, то они будут потеряны
· этот наиболее простой способ обмена требует минимальных и аппаратных и программных затрат
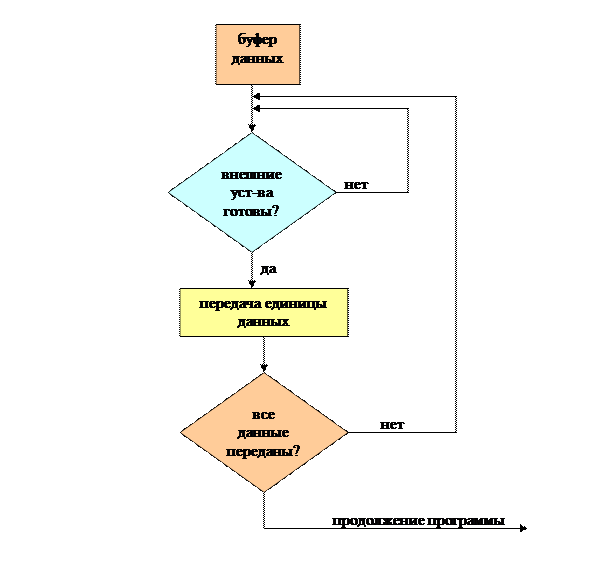
б) обмен в асинхронном режиме – обмен с проверкой готовности ВУ (обмен по готовности ВУ)
· в этом режиме каждая следующая команда на приём или передачу данных даётся только тогда, когда ВУ выполнит предыдущую команду и сообщит об этом, установив бит (флаг) готовности в своём регистре состояний
Изобразим алгоритм обмена:
Рассмотрим действия, необходимые для печати слова EPSON на принтере, подключённом параллельно в входу PC (LPT1).
Контроллер параллельного интерфейса имеет 3 регистра:
- регистр данных – 378h: записывается байт данных, который затем пересылается в буфер принтера
- регистр состояний – 379h
- регистр управления – 37Ah: записывается команда, управляющая работой принтера
Рассмотрим простейшую программу:
const D: array [1..7] of byte = ($45,$50,$53,$4F,$4E,$D,$A);
var
I: byte;
DR, SR, CR: word;
begin
DR:= MemW[0:$408];
SR:= DR + 1;
CR:= SR + 1;
if (Port[SR] and $80) = 0 then
begin
writeln(‘принтер не готов’);
readln;
end
else
for I:=1 to sizeof (D) do
begin
while (Port[SR] and $80) = 0 do;
Port[DR]:= D[I];
Port[CR]:= $D; {13}
{можно добавить ещё одно переприсвоение, для того чтобы компьютер успевал сначала добавить, а потом сбросить бит}
Port[CR]:= $C; {12}
end;
End.
обмен в режиме прерывания – такой способ обмена, при котором производится приостановка (для выполнения ввода/вывода) или прерывание выполняемой программы; причём обмен инициирует не программа, выполняемая процессором, а само внешнее устройство (ВУ)
· при реализации этого способа обмена команды или инструкции обслуживания этого устройства оформляются в виде подпрограммы – подпрограммы обработки прерываний (ПОП)
· процессор передаёт управление ПОП только в том случае, если ВУ, исходя из своих внутренних побуждений, само известит процессор о готовности к обмену, для этого он выставляет на соответствующую линию шины управления системного интерфейса сигнал «запрос на прерывание»
· если при программо-управляемом обмене готовность ВУ определяется путём программного считывания содержимого регистра состояний контроллера ВУ, то появление запроса на прерывание появляется аппаратно
· наличие сигнала готовности проверяется процессором автоматически при выполнении каждой команды – это существенно экономит время процессора, поскольку программный цикл ожидания отсутствует
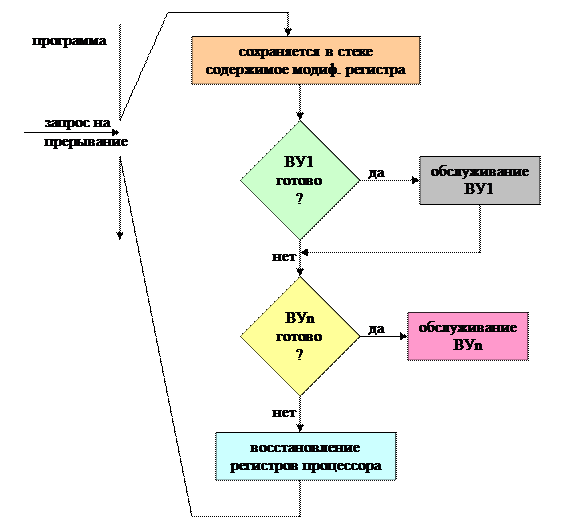
Какие действия выполняются в компьютере при появлении сигнала на прерывание?
процессор завершает выполнение текущей команды
↓
если аппаратное прерывание разрешено, т.е. установлен флаг в прерывании в регистре состояний процессора, то процессор с помощью специальных сигналов и соответствующих циклов шины подтверждает готовность к прерыванию и идентифицирует источник запроса
↓
процессор сохраняет в (текущем) стеке содержимое счётчика команд (СК) и содержимое регистра состояний (РС)
↓
процессор помещает в СК адрес подпрограммы обработки прерывания для данного устройства и приступает к её выполнению
↓
в начале своей работы подпрограмма обработки прерывания должна сохранить в стеке содержимое регистров процессора и в конце работы она должна восстановить эти регистры из стека
↓
подпрограмма обработки прерываний завершается специальной инструкцией возврата из прерывания, по этой инструкции процессор извлекает из стека адрес возврата прерванной программы – после чего продолжается выполнение прерванной программы
· такой алгоритм обслуживания прерываний с использованием стека обеспечивает вложенность прерываний; вложенность означает, что любое ВУ может прервать уже выполняющуюся подпрограмму обработки прерываний, если оно имеет более высокий приоритет, чем обслуживаемое устройство
· приоритет – число, приписанное ВУ, которое определяет очерёдность его обслуживания (обычно наибольший приоритет имеет наиболее быстродействующие устройства или устройства, данные от которых не могут быть восстановлены
· устройство с высшим приоритетом обслуживается первым
· если обслуживание запрашивает устройство, приоритет которого не выше приоритета уже обслуживаемого устройства, то его запрос блокируется до завершения текущей ПОП

- в контроллерах ВУ, работающих в режиме прерывания в регистре управления, как правило, имеется бит, с помощью которого можно разрешить или запретить устройству генерацию сигналов «запрос на прерывание»
- прерывания, о которых идёт речь, это аппаратные или внешние прерывания (т.е прерывания генерируемые внешними по отношению к процессору устройствами)
аппаратные прерывания подразделяют на:
- маскируемые прерывания (INIR) можно запретить, сбросив флаг прерывания в регистре флагов процессора; можно также запретить прерывания от отдельных устройств с помощью регистра маски контроллера прерываний
- немаскируемые прерывания с помощью регистра флагов запретить нельзя; немаскируемые прерывания могут генерировать схемы контроля чётности оперативной памяти (NMI), а также систему управления энергопотребления (SMI)
- также различают программные или внутренние прерывания – генерируются самим процессором
- к программным прерываниям относят особые случаи (исключения) (деление на ноль; запрос о отсутствующей в памяти страницы; нарушение защиты по привилегиям)
- прерывания, генерируемые машинными командами, используются для доступа к стандартным подпрограммам, адреса которых программисту неизвестны
- программные прерывания обрабатываются так же, как и аппаратные, только в первом случае отсутствуют циклы подтверждения прерывания
Высшие приоритеты имеют:
- программы прерывания
- немаскируемые аппаратные прерывания
- маскируемые прерывания
Существуют 2 основных свойства идентификации ВУ, запросившего обслуживание:
- с помощью программного опроса (полинга) готовности ВУ, работающих в режиме прерывания
- с использованием векторов прерывания
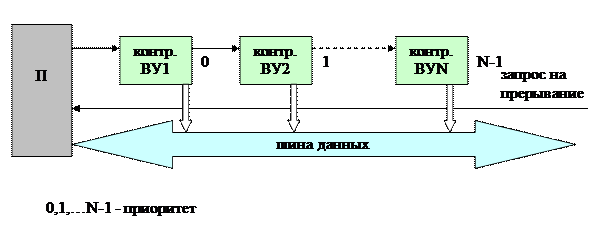
- в первом случае запросы на прерывание от всех ВУ объединяются по схеме ИЛИ (монтажное ИЛИ) и подаются на соответствующий вход процессора; обработка прерываний осуществляется с помощью единой подпрограммы обработки прерываний
- приоритеты ВУ при такой организации обслуживания прерываний определяются очерёдностью их опроса, чем раньше в подпрограмме опрашивается устройство, тем выше его приоритет и тем меньше время реакции на его запрос
- необходимость последовательного опроса всех ВУ существенно увеличивает время устройств, опрашиваемых последними
- уменьшить время обслуживания ВУ можно с помощью векторной системы подготовки прерывания
- в случае векторной системы для каждого ВУ имеется собственная подпрограмма обработки прерываний, адрес этой подпрограммы обычно называется векторным прерыванием
- для того чтобы процессор смог обработать запрос от ВУ, он должен тем или иным способом получить вектор прерывания для данного устройства
Существует 2 основных способа получения вектора прерывания:
- само ВУ может сообщить вектор прерывания
- контроллер прерывания, общий для всех ВУ
Соответственно различают 2 варианта реализации векторной системы:
- векторная система с интерфейсным вектором
- с вне интерфейсным вектором
- в первом случае контроллер каждого внешнего устройства, работающего в режиме прерывания должен иметь специальный регистр для хранения вектора прерывания
- это схема намного эффективнее схемы прерывания с программным опросом, поскольку здесь опрос осуществляется не программно, а аппаратно
- во втором случае системы с вне интерфейсным вектором - специальные регистры для хранения векторов, адресов в контроллере ВУ отсутствует, а для идентификации используется общий для всех устройств контроллер прерывания – такая схема характерна для IBM совместимых PC
Изобразим схему взаимодействия процессора с контроллером прерывания и шины IBM PC:
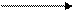
- за исключением IRQ0, IRQ1, IRQ8, IRQ13 (системный таймер, клавиатура, часы реального времени, сопроцессор); контроллер шины формирует 2 цикла чтения, только во 2 цикле чтения контроллер прерывания выставляет номер вектора прерывания на шину данных, а процессор считывает его с шины данных
- в реальном режиме вектора прерываний хранятся в таблице векторов прерываний, которые находятся в одном килобайте оперативной памяти, под каждый вектор выделено 4 байта (2 под смещение и 2 байта под адрес сегмента)
- абсолютный адрес вектора прерываний в таблице = номер вектора умножить на 4
- далее процессор сохраняет в стеке содержимое регистров флагов, содержимое регистра сегмента кода CS, смещение IP, затем сбрасывается флаг прерывания в регистре флагов; по адресу: номер вектора умноженный на 4 считывается из оперативной памяти адрес сегмента
- подпрограмма обработки прерывания завершается инструкцией конца прерывания – EOI (end of interruption)
- если обслуживание одновременно запрашивает несколько устройств, то контроллер прерывания обслуживает устройства с наибольшим приоритетом, а остальные устройства блокирует до получения команды конца прерывания
обмен в режиме прямого доступа к памяти – обмен между ВУ и памятью осуществляется без участия процессора – специальный контроллер доступа к памяти общий для всех устройств, либо контроллер ВУ, если он имеет средство управления шинами
· это наиболее быстрый способ обмена поскольку он требует меньшего числа тактов шины, чем при программно-управляющем обмене и обмене в режиме прерывания
· в режиме прямого доступа могут работать LPT, COM, накопитель на магнитной диске, жёсткий диск, сетевые адаптеры
· существует много способов организации обмена в режиме доступа к памяти
1. с захватом цикла (с идентификацией состояния памяти)
· в этом режиме обмен устройства с памятью осуществляется в течении тех машинных циклов процессора, когда последний не обращается к шине
· для идентификации таких состояний процессор может генерировать специальный сигнал, указывающий что шина свободна
2. прямой доступ к памяти с блокировкой процессора по запросу
· в этом случае на время обмена процессор отключается от шин системного интерфейса
· если устройство работает медленно, то оно в режиме прямого доступа к памяти (ПДП) – передаёт отдельные байты
· команда SC – после передачи байта запрос на прямой доступ к памяти сразу снимается DACK
· если устройство работает быстро – данные передаются блоками, DACK не снимается
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 1017; Нарушение авторских прав?; Мы поможем в написании вашей работы!