КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методы исследования операций в управлении инновационными проектами
|
|
|
|
Классификация и особенности аналитических методов и моделей процесса управления инновациями
МАТЕМАТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА ПРОЦЕССА УПРАВЛЕНИЯ ИННОВАЦИОННЫМИ ПРОЕКТАМИ
аналитические методы и модели, классификация аналитических моделей, исследование операций, сетевые модели, сетевое планирование, стохастические методы, балансовый модели, одно- и многопродуктовые модели Леонтьева, производственные функции, методы принятие решений
Классифицируют методы и модели управления ИП по различным признакам:
- по признаку целевого назначения выделяют теоретические и прикладные модели;
- по признаку масштаба (величины) изучаемого объекта модели делят на макроэкономические и микроэкономические;
- по признаку характера зависимости от времени модели делят на статические и динамические;
- по признаку способа отображения времени модели делят на дискретные и непрерывные;
- по характеру отображения причинно-следственных связей различают детерминированные, стохастические и теоретико-игровые модели;
- по математическому инструменту, применяемому при моделировании.
Выбор того или другого метода (модели) в каждом конкретном случае может производиться на основе следующих критериев [С.Янга, 32]:
- практическая применимость;
- стоимость использования;
- выход, получаемый при применении;
- достоверность;
- стабильность решения, получаемого с помощью метода;
- сбалансированность данного метода с другими методами.
Методы, используемые для формирования решений, могут быть эффективны лишь при определенных условиях, и возможность их применения может быть сужена различными ограничениями. Например, при корреляционном анализе объем выборки должен быть не меньше 30. Если мы хотим применить линейное программирование, используемые функции должны быть линейными.
В табл. 25 представлены основные математические методы, используемые при управлении ИП.
Кратко прокомментируем эту таблицу.
Ситуация 1-1 “статика-определенность”. Методы решения наиболее хорошо разработаны для подобных задач. Особенно эффективными являются вычислительные алгоритмы линейного программирования, в том числе точные. Когда целевая функция и ограничения нелинейны, существуют лишь приближенные методы, среди которых следует отметить весьма перспективный метод Скарфа. Геометрическое программирование применяется для решения задач с функциями типа производственных функций Кобба - Дугласа. Можно отметить, что из-за несовершенности методов нелинейного программирования исследователи часто пытаются использовать линейную аппроксимацию, чтобы применить аппарат линейного программирования.
Стохастическое программирование позволяет дополнительно учесть вероятностные факторы. Не все задачи математического программирования с вероятностными параметрами удается решить с его помощью, а лишь те, которые сводятся к некоторым детерминированным задачам.
Ситуация 1-2 “статика-неопределенность”. Специальных методов решения статических задач при неопределенности мало. Однако если понятие оптимальности определено, то для дальнейшего решения можно использовать методы из 1-1.
Таблица 25. Основные математические методы, используемые при анализе ИП
| Определенность -1 | Неопределенность - 2 | ||||
| Несколько лиц | Незнание | Несколько критериев | |||
| С т а т и к а - 1 | Линейное программирование Нелинейное программирование Параметрическое программирование, дискретное, в т.ч. целочисленное программирование геометрическое программирование | Стохастическое программирование Антагонис-тические игры | Теория игр | Статистические решения Игры с природой | Многоцелевая оптимизация Групповые решения Игры с природой |
| Д и н а м и к а - 2 | 1. Вариационное исчисление 2. Оптимальное управление 3. Динамическое программирование 4. Сетевое планирование 5. Математическое программирование в функциональных пространствах | 1. Стохастическое динамическое программирование 2. Теория массового обслуживания 3. Управление случайными процессами | 1. Теория позиционных игр, в т.ч. дифферен-циальных игр 2. игры на случайных процессах | 1. Теория обучения 2. статистиче- ские решения | 1. Многоцеле- вая оптимизация в функциона- льных пространствах |
Ситуация 2-1 “динамика-определенность”. Методы этого типа в основном предназначены для решения технологических, отчасти технико-экономических задач. Точная определенность, непрерывность времени и гладкость функций, которые требуются для применения методов типа оптимального управления делает их малопригодными для социально-экономических задач. Однако можно ими пользоваться, если сделать необходимые поправки в решении согласно реальным условиям. Сетевое планирование разработано специально для технико-экономических задач, однако весьма частных - составления плана создания новых изделий, строительства новых объектов и т.п.
Стохастическое динамическое программирование и управление случайными процессами относятся к динамическому программированию и оптимальному управлению так же, как стохастическое программирование к математическому программированию. Теория массового обслуживания предназначена для анализа систем обслуживания случайно возникающих требований в услугах.
Ситуация 2-2 “динамика-неопределенность”. В принципе методы этого раздела мало отличаются от методов 1-2., однако технические трудности здесь значительно больше. Даже корректная формулировка некоторых задач требует весьма высокой математической культуры.
Наиболее распространенными и эффективными математическими методами (скорее – это группы методов, включающие в себя отдельные методы) являются методы оптимизации, эконометрические методы, методы исследования операций, системная динамика. Коротко охарактеризуем каждую группу методов.
Задача оптимизации технических и экономических процессов (к которым относятся и процессы управления ИП) состоит в таком их построении и организации, которые при данных условиях обеспечивают достижение наилучших результатов. В общем случае задача оптимизации разделяется на три:
- разработка математической модели процесса;
- математическая формулировка целевой функции (критерия качества);
- определение метода решения задачи.
Различают два класса задач оптимизации. При статической оптимизации отыскивается оптимум стационарной точки процесса (иначе - оптимизация в пространстве параметров).
При динамической оптимизации отыскивается оптимальная стратегия управления или регулирования процесса (или - оптимизация в пространстве состояний). В этом случае рассматривают, прежде всего, оптимальное управление, или регулирование процессов.
Эконометрия представляет собой направление экономических и социальных наук, ориентированное на применение математических и статистических методов. Ее задача состоит в том, чтобы на основе статистических данных строить математические модели социально-экономических процессов. Поскольку статистические данные об экономических процессах характеризуют их состояние лишь в отдельные моменты времени, эконометрические модели, как правило, имеют вид разностных уравнений. Основными методами идентификации параметров здесь служат методы максимального правдоподобия, линейного и нелинейного регрессионного анализа. В последнее время широкое применение получили методы спектрального анализа.
Исследование операций (ИО) - это научная дисциплина, изучающая процессы принятия решений в экономических, социальных и других системах, стратегии и способы организации, обеспечивающие оптимальное поведение исследуемой системы. К задачам ИО относят: оптимальное распределение капвложений, прогнозирование технического прогресса и экономического роста, оперативное и долгосрочное планирование, управление организацией (фирмой), контроль качества, изучение рынка и т.д. Использование ИО позволяет принимать обоснованные решения, осуществляя в ряде случаев оптимальный выбор имеющихся альтернатив.
Системная динамика представляет собой качественный метод моделирования и имитации сложных динамических социально-экономических систем, отличающихся нелинейными и сильно разветвленными структурами контуров регулирования. Этот метод, основанный на отображении в пространстве состояний, был предложен Дж.Форрестером /28/.
Процесс моделирования связан с рядом процедур, таких, например, как выбор целевой функции, переменных, параметров и т.д. Рассмотрим некоторые из них.
Для построения моделей формулируются следующие понятия:
- целевая функция - характеристика объекта для дальнейшего поиска критерия оптимальности, математически связывающая между собой те или иные факторы объекта исследования;
- критерий оптимальности - показатель, выбираемый исследователем, имеющий, как правило, экономический смысл, который служит для формализации конкретной цели управления объектом исследования и выражается при помощи целевой функции. Целевая функция и критерий оптимальности - разные понятия и могут быть описаны функциями одного и того же вида или же разными функциями;
- ограничения - определяют пределы, сужающие область осуществимых, приемлемых или допустимых решений, и фиксируют основные внешние и внутренние свойства объекта. Ограничения определяют области исследования и протекания процессов, пределы изменения параметров и факторов объекта.
Переменные в моделях могут быть переменными состояния, скорости, роста, вспомогательными и управляющими.
Переменные состояния определяют или помогают определить состояние системы в любой момент времени (фазовые переменные). Типичным примером может служить, например, объем продаж и прибыль. Переменные состояния должны поддаваться измерению и представлять интерес для исследования.
Переменные скорости (роста) - характеристики, задающие процесс, который протекает в системе в заданный момент времени. Данный процесс можно квалифицировать либо как преобразование, либо как перемещение.
Вспомогательные переменные способствуют более глубокому пониманию объекта и в отдельных случаях упрощают сопоставление результатов наблюдения. Это, как правило, относительные показатели.
Управляющие переменные - входы модели, значения которых изменяются во времени независимо от поведения исследуемого объекта. Рост объема производства - результат управления со стороны внешней среды, воздействие которой на определенных стадиях может рассматриваться как постоянная величина. Управляющую переменную можно представить как функцию от времени.
Параметры и константы - это не зависящие от времени количественные показатели и коэффициенты, включаемые в математическую модель. Под константой понимают численную величину, имеющую надежно и точно вычисленное значение, которое остается неизменным при варьировании условий эксперимента, а также в тех случаях, когда модель используется для проверки различных гипотез или описания различных компонентов системы.
Термин “параметр” обычно относится к характеристикам, численные значения которых отличаются меньшей определенностью по сравнению с константами, но, тем не менее, остаются неизменными на протяжении исследования модели. Параметры подвержены влиянию условий эксперимента и могут иметь приближенное значение.
Построение математической модели системы включает несколько этапов.
1.Определяется объект исследования.
2.Формулируется цель исследования.
3.В рассматриваемом экономическом объекте выделяются структурные и функциональные элементы и выделяются наиболее существенные качественные характеристики этих элементов, влияющие на достижение поставленной цели.
4.Вводятся символические обозначения для учитываемых характеристик экономического объекта. Определяется, какие из них будут рассматриваться как эндогенные, а какие как экзогенные; какие как зависимые величины, а какие как независимые; какие как неизвестные (искомые), а какие как известные.
5.Формализуются взаимосвязи между определенными параметрами модели, т.е. строится собственно экономико-математическая модель (ЭММ).
6.Проводятся расчеты по модели и анализируются результаты полученных расчетов.
7. Если результаты оказываются неудовлетворительными с точки зрения неадекватности отображения моделируемого процесса или явления, то происходит возврат к одному из предшествующих пунктов и процесс повторяется.
Теперь коротко охарактеризуем методы, которые используются для анализа процесса управления инновационными проектами.
В статистическом анализе производится обработка некоторой случайной выборки, под которой понимаются результаты N последовательных и независимых экспериментов со случайной величиной или событием. Выборка должна быть состоятельной.
Используется для исследования процессов и объектов по результатам массовых экспериментов со случайными величинами или событиями.
Наиболее употребительные методы: регрессионный анализ, корреляционный анализ, дисперсионный анализ, ковариационный анализ, анализ временных рядов, метод главных компонентов, факторный анализ.
В практической деятельности регрессионный анализ часто используется для создания так называемой эмпирической модели, когда, обрабатывая результаты наблюдений (или характеристики существующих систем), получают регрессионную модель и используют ее для оценки перспективных систем или поведения системы при гипотетических условиях.
Точность и надежность получаемых оценок зависят от числа наблюдений и расположения прогностических значений xj относительно базовых (т.е. известных на некоторый момент времени xj(0)). Чем больше разность, тем меньше точность прогноза.
Корреляционный анализ используется для определения степени линейной зависимости между случайными величинами.
Дисперсионный анализ используется для проверки статистических гипотез о влиянии на показатели качественных факторов, т.е. факторов, не поддающихся количественному измерению (организация производства). В этом заключается его отличие от регрессионного анализа, в котором факторы выступают как параметры, имеющие количественную меру (например, затраты на производство).
Ковариационный анализ используется для создания и изучения вероятностных моделей процессов, в которых присутствуют одновременно как количественные, так и качественные факторы, т.е. он объединяет регрессионные и дисперсионные методы.
Анализ временных рядов используется при исследовании дискретного случайного процесса, протекающего на интервале времени Т.
Результаты экспериментов или наблюдений, полученные на данном интервале, представляются в виде временного ряда, каждое значение Yi которого включает детерминированную f(t) и случайную z(t) составляющие:
Yi = f(t) + z(t).
Детерминированная составляющая описывает влияние детерминированных факторов в момент времени t, влияние же множества случайных факторов описывает случайная составляющая.
С помощью представления случайного процесса в виде временных рядов можно исследовать динамику этого процесса, выделить факторы, существенным образом влияющие на показатели и определить периодичность их максимального воздействия, провести интегральный или точечный прогноз показателя Y на некоторый промежуток времени Dt.
Метод главных компонентов используется при рассмотрении некоторого множества случайных значений показателей Yi, i=1,...,k в целях определения общих для них факторов (компонентов), от которых они все зависят. Степень зависимости i-го показателя от j-го компонента отражается величиной aij, называемой нагрузкой i-го показателя на j-ый компонент.
Модель главных компонентов показывает, что и в какой степени определяет исследуемые показатели, а также объясняет связи между ними.
Факторный анализ по своей сути совпадает с методом главных компонентов, однако позволяет представить показатели через меньшее количество факторов (компонентов), поэтому используется при исследовании сложных систем управления с большим числом показателей и сложными взаимосвязями между ними.
Следующая большая группа методов - методы оптимизации при исследовании ИП.
Синтез методами безусловной оптимизации. Сущность безусловной оптимизации состоит в поиске минимума функции Y = f(x) путем многократных вычислений при различных значениях параметров x = {xk}, k = 0,1,... причем на каждом k-м шаге вычислений контролируют выполнение условий f(x(k+1)) £ f(x(k)), которые должны привести к минимальному значению функции.
Основные трудности применения заключаются в определении шага изменения параметра x(k), направления этого изменения и начального приближения x(0).
Область применения. Методы безусловной оптимизации используются для однокритериальной оптимизации детерминированных функций при отсутствии ограничений на саму функцию и ее параметры.
Методы многокритериальной оптимизации используются в задачах многоцелевого характера, когда предназначение системы может быть реализовано лишь при достижении нескольких целей.
В многокритериальных задачах, как правило, большинство требований к улучшению значений используемых показателей противоречат друг другу. В таком случае говорят об антагонизме целей, и основной задачей становится поиск правила, удовлетворяющего все цели с помощью компромиссного решения.
Все существующие методы многокритериальной оптимизации делятся на две группы. К первой относятся методы, в которых количественно или качественно оценивается степень важности каждого показателя для достижения предназначения системы управления в целом.
Это позволяет создавать некоторый обобщенный показатель и описывать критерий уже относительно него, т.е. осуществляется сведение многокритериальной задачи к однокритериальной, методы решения которой хорошо известны.
Во второй группе методов осуществляется поиск решения на всем пространстве критериев путем сужения области возможных решений. Из суженной области возможных решений субъективно выбирается одно.
Методы математического программирования относятся к численным методам поиска оптимальных решений, которые позволяют найти решение только для конкретных значений параметров. Содержание математического программирования составляют теория и методы решения задач о нахождении экстремумов функций на множествах, определяемых линейными и нелинейными ограничениями (равенствами и неравенствами).
К методам математического программирования относятся методы линейного, нелинейного, дискретного, стохастического и динамического программирования.
Линейное программирование используется в случае, когда функции эффективности и ограничения линейны. Идея: задается некоторое неоптимальное решение (начальный план), а затем оптимальное решение находится путем изменения начального плана в направлении приближения к оптимальному. Линейное программирование является наиболее разработанной ветвью математического программирования.
При нелинейном характере хотя бы одного компонента математической модели (целевой функции или ограничений) применяются методы нелинейного программирования.
Некоторые математические модели могут содержать условие дискретности параметров (например, по своей физической сущности параметры должны быть только целыми числами - производимые автомобили). Решение таких задач осуществляется с помощью методов дискретного (целочисленного) программирования.
Отыскание решений в операциях, которые носят многоэтапный характер, проводится с помощью методов динамического программирования. Сущность метода состоит в отыскании оптимального решения не за все этапы одновременно, а последовательно от этапа к этапу; оптимизация каждого этапа проводится с учетом всех последующих этапов (передаточные функции).
Если операция носит случайный характер и приходится иметь дело со случайными величинами и функциями, то для ее исследования используются методы стохастического программирования.
Исследование процесса управления ИП можно эффективно проводить с использованием следующих математических теорий: теории принятия решений, теории массового обслуживания, теории игр.
Принятие решений является одним из основных этапов процесса управления в организационных системах и представляет собой выбор одной из альтернативных стратегий или способов действий, направленных на достижение цели. Теория принятия решений используется при необходимости сделать выбор варианта действий в условиях риска и (или) наличия неопределенности. Такие условия возникают, если исходная информация выражается через вероятностные характеристики (в таком случае говорят о принятии решения в условиях риска) либо исходные данные заданы неопределенно, например, интервалами изменения или вообще только названием. В п. 7.6 мы подробно рассмотрим подобные ситуации, возникающие в процесс управления ИП.
Теория массового обслуживания используется для исследования систем управления, в которых имеется необходимость пребывать в состоянии ожидания. Это является следствием вероятностного характера возникновения потребности в обслуживании и разброса показателей соответствующих систем. В таких случаях исследуемую систему представляют в виде системы массового обслуживания (СМО). В гл. 9 такие подходы будут использованы при помтроении имитационных моделей ИП.
Игровые задачи управления предполагают участие в активном воздействии на объект управления двух сторон или игроков: управляющей системы, определяющей состояние объекта, обеспечивающее эффективное управление, и среды, формирующей воздействие, ухудшающее эффективность управления. Подобные ситуации, когда игроки преследуют прямо противоположные интересы, называются конфликтными ситуациями.
В случае, когда задача предназначена для принятия одного решения, то она сводится к задаче линейного программирования и результат отыскивается с помощью его методов.
Если же речь идет о многократно повторяемой ситуации, то используются численные методы, где игроки разыгрывают несколько партий и цена игры определяется средним выигрышем.
Если цели не совпадают, то математическая модель становится гораздо сложнее и получить четкие рекомендации по оптимальному действию сторон становится значительно труднее.
Приведенное краткое описание аналитических методов и моделей для исследования процесса управления ИП позволяет сделать следующие выводы.
Для эффективного решения задач управления ИП необходим комплексный подход с использованием основных положений анализа и синтеза систем управления.
Выбор метода поиска решения задачи осуществляется в зависимости от вида решения, степени соответствия потребностей и их удовлетворения в объекте управления, вида переменной лимитирующей проблемы задачи, квалификации специалистов. Если какой-либо метод на определенном этапе творческого процесса исчерпал себя, следует рассмотреть другие методы, а также их комбинации.
Области применения математических методов для целей исследования систем управления зависят от особенностей математической модели системы управления и вида исходной информации. Например, задачи синтеза значительно проще решать на детерминированных моделях, т.к. используемые при этом методы требуют рассмотрения большого числа вариантов построений системы или перебора множества значений ее параметров для поиска лучшего согласно принятому критерию. В то же время в задачах оптимизации все хорошо, когда модель линейна, однокритериальна и детерминирована. Любые отклонения от этих свойств приводят к появлению новых трудностей. Так, если оптимизируемая функция нелинейна, то приходится представлять ее как совокупность линейных функций, или линейно аппроксимировать на каком-либо интервале, либо вводить ряд допущений, т.е. искусственно уходить от нелинейности.
При многокритериальности стремятся выделить главный критерий или ранжировать критерии, чтобы свести к некоторому обобщенному критерию, а затем переходить к однокритериальной оптимизации.
Использовать математический метод в чистом виде обычно не удается. Поэтому под определенный метод приходится вводить ряд допущений для “подгонки” задач под метод.
Эффективное использование аналитических методов возможно для задач с высоким уровнем их формализации. Чем интеллектуальнее задача, тем труднее ее формализовать, а значит, и автоматизировать с использованием вычислительных средств.
Рассмотрим особенности применения теории исследования операций на примере трех известных методик прогнозирования изменений неких переменных как функций времени:
- прогнозирование с использованием скользящего среднего;
- прогнозирование путем экспоненциального сглаживания;
- регрессионное прогнозирование.
Используем следующие основные обозначения:
yt - действительное (или наблюдаемое) значение случайной величины y в момент времени t,
y*t - расчетное значение (оценка) случайной величины y в момент времени t,
e t - случайный компонент (или шум) в момент времени t.
Прогнозирование с использованием скользящего среднего. При использовании этой методики основное предположение состоит в том, что временной ряд является устойчивым в том смысле, что его члены являются реализациями следующего случайного процесса:
yt = b + et,
где b - неизвестный постоянный параметр, который оценивается на основе представленной информации. Предполагается, что случайная ошибка et имеет нулевое математическое ожидание и постоянную дисперсию. Кроме того, предполагается, что данные для различных периодов времени не коррелированны.
Предполагает, что последние n наблюдений являются равнозначно важными для оценки параметра b. Другими словами, если в текущий момент времени t последние n наблюдений есть yt-n+1, yt-n+2,..., yt, тогда оцениваемое значение для момента t+1 вычисляется по формуле:
y*t+1 = (yt-n+1 + yt-n+2 +... + yt) / n.
Не существует четкого правила для выбора числа n - базы метода, использующего скользящее среднее. Если есть весомые основания полагать, что наблюдения в течение достаточно длительного времени удовлетворяют модели yt = b + et, то рекомендуется выбирать большие значения n. Если же наблюдаемые значения удовлетворяют приведенной модели в течение коротких периодов времени, то может быть приемлемым и малое значение n. На практике величина n обычно принимается в пределах от 2 до 10.
Пример 1.
В таблице представлены объемы спроса на некое изделие за прошедшие 24 месяца. Необходимо с помощью метода скользящего среднего дать прогноз объема спроса на следующий месяц (здесь t = 25).
| Месяц t | Спрос yt | Месяц t | Спрос yt |
Чтобы проверить применимость метода скользящего среднего, проанализируем приведенные данные. На рис. 20 нанесены значения временного ряда yt. График показывает, что наблюдается тенденция к возрастанию значений yt с течением времени. Это, вообще-то, означает, что скользящее среднее не будет хорошим предсказателем для будущего спроса. В частности использование большой базы n для скользящего среднего неприемлемо в этом случае, т.к. это приведет к подавлению наблюдаемой тенденции в изменении данных. Следовательно, если мы используем небольшое значение для базы n, то будем находиться в лучшем положении с точки зрения отображения упомянутой тенденции в изменении данных.
Если мы используем значение n = 3 в качестве базы скользящего среднего, то оценка спроса на следующий месяц (t = 25) будет равна средней величине спроса за 22, 23 и 24 месяцы:
y*25 = (62+70+72)/3 = 68 единиц.
Оценка величины спроса в 68 единиц для 25 месяца будет использоваться также при прогнозе спроса для t = 26:
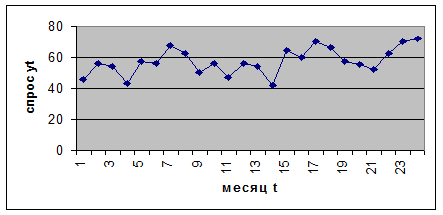
Рис.20
y*26 = (70+72+68)/3 = 70 единиц.
Когда значение реального спроса в 25 месяце будет известно, его следует использовать для вычисления новой оценки спроса для 26 месяца в виде средней величины спроса 23, 24 и 25 месяцев.
Метод экспоненциального сглаживания предполагает, что вероятностный процесс определяется моделью yt = b + et; это предположение использовалось и при рассмотрении метода скользящего среднего. Метод экспоненциального сглаживания разработан для того, чтобы устранить недостаток метода скользящего среднего, который состоит в том, что все данные, используемые при вычислении среднего, имеют одинаковый вес. В частности, метод экспоненциального сглаживания приписывает больший весовой коэффициент самому последнему наблюдению.
Определим величину a (0 < a < 1) как константу сглаживания, и пусть известны значения временного ряда для прошедших t моментов времени y1, y2,..., yt. Тогда оценка y*t+1 для момента времени t+1 вычисляется по формуле:
y*t+1 = ayt + a(1 - a)yt-1 + a(1 - a)2yt-2 +....
Коэффициенты при yt, yt-1, yt-2,... постепенно уменьшаются, тем самым эта процедура приписывает больший вес последним (по времени) данным.
Формулу для вычисления y*t+1 можно привести к следующему (более простому) виду:
y*t+1 = ayt + (1 - a){ayt-1 + a(1 - a)yt-2 + a(1 - a)2yt-3 +... } = ayt + (1 - a)y*t.
Т.о., значение y*t+1 можно вычислить рекуррентно на основании значения y*t. Вычисления в соответствии с этим рекуррентным уравнением начинаются с того, что пропускается оценка y*t для t = 1 и в качестве оценки для t = 2 принимается наблюденная величина для t = 1, т.е. y*2 = y1. В действительности же для начала можно использовать любую разумную процедуру. Например, часто в качестве оценки y*0 берется усредненное значение yi по “приемлемому” числу периодов в начале временного ряда.
Выбор константы сглаживания a является решающим моментом при вычислении значения прогнозируемой величины. Большее значение a приписывает больший вес последним наблюдениям. На практике значение a берут в пределах от 0.01 до 0.30.
Пример 2.
Применим метод экспоненциального сглаживания к данным из прим. 1 при a = 0.1.
В таблице содержатся результаты вычислений. При вычислениях пропускается y*1 и принимается, что y*2 = y1 = 46 единиц.
| i | yi | y*i | i | yi | y*i |
| - | 0.1´56+0.9´51.63 = 52.07 | ||||
| 0.1´54+0.9´52.07 = 52.26 | |||||
| 0.1´56+0.9´46 = 47 | 0.1´42+0.9´52.26 = 51.23 | ||||
| 0.1´54+0.9´47 = 47.7 | 0.1´64+0.9´51.23 = 52.50 | ||||
| 0.1´43+0.9´47.7 = 47.23 | 0.1´60+0.9´52.50 = 53.26 | ||||
| 0.1´57+0.9´47.23 = 48.21 | 0.1´70+0.9´53.26 = 54.93 | ||||
| 0.1´56+0.9´48.21 = 48.98 | 0.1´66+0.9´54.93 = 56.04 | ||||
| 0.1´67+0.9´48.98 = 50.79 | 0.1´57+0.9´56.04 = 56.14 | ||||
| 0.1´62+0.9´50.79 = 51.91 | 0.1´55+0.9´56.14 = 56.02 | ||||
| 0.1´50+0.9´51.91 = 51.72 | 0.1´52+0.9´56.02 = 55.62 | ||||
| 0.1´56+0.9´51.72 = 52.15 | 0.1´62+0.9´55.62 = 56.26 | ||||
| 0.1´47+0.9´52.15 = 51.63 | 0.1´70+0.9´56.62 = 57.63 |
Из приведенных данных следует, что оценка для t = 25 равна
y*25 = ay24 + (1 - a)y*24 = 0.1´72 + 0.9´57.63 = 59.07 единиц.
Эта оценка значительно отличается от полученной с помощью метода скользящего среднего (68 единиц). Большее значение для a даст оценку, более близкую к оценке метода скользящего среднего.
Регрессионный анализ определяет связь между зависимой переменной (например, спросом на продукцию) и независимой переменной (например, временем). Часто применяемая формула регрессии, описывающая зависимость между переменной y и независимой переменной x, имеет вид:
Y = b0 + b1x + b2x2 +... + bnxn + e,
где b0, b1,..., bn - неизвестные параметры. Случайная ошибка e имеет нулевое математическое ожидание и постоянную дисперсию (т.е. дисперсия случайной величины e одинакова для всех наблюдаемых значений у).
Самая простая регрессионная модель предполагает, что зависимая переменная линейна относительно независимой переменной, т.е.
y* = a + bx
Константы a и b определяются из временного ряда с использованием метода наименьших квадратов, в соответствии с которым находятся значения этих констант, доставляющих минимум сумме квадратов разностей между наблюденными и вычисленными величинами. Пусть (yi, xi) представляет i -ю точку исходных данных временного ряда, i = 1,2,...,n. Определим сумму квадратов отклонений между наблюденными и вычисленными величинами.
n
S = å (yi – a - bxi) 2
i=1
Значения коэффициентов a и b определяются из соответствующих условий минимума функции S, которые представимы в виде следующих уравнений.
n
¶S/¶a = -2 å (yi – a - bxi) = 0
i =1
n
¶S/¶b = -2 å (yi – a - bxi)xi = 0
i =1
После алгебраических преобразований получим следующее решение данных уравнений
n __ n _ _ _
b = ( å yixi – nyx) / ( å x2i - nx2); a = y - bx,
i=1 i=1
где
_ n _ n
x = å xi / n, y = å yi / n.
i =1 i =1
Приведенные соотношения показывают, что сначала необходимо вычислить b, а затем величину коэффициента a.
Вычисленные значения a и b имеют силу при любом вероятностном распределении случайных величин yi. Однако если yi является нормально распределенной случайной величиной с постоянным стандартным отклонением, можно установить доверительный интервал для среднего значения оценки при x = x0 (т.е. для y0 = a + bx) в виде интервала
_________________________
__ / _ _
(a + b0) ± ta / 2, n-2 Ö å ni = 1(yi - y*i)2 / (n-2) Ö 1/n + (x0 - x)2 / (åni = 1xi2 - nx2)
Выражение (yi - y*i) представляет собой отклонение i -го наблюдения зависимой переменной от его соответствующей оценки.
Мы заинтересованы в установлении для прогнозируемых значений зависимой переменной y соответствующих им интервалов предсказания (скорее чем доверительного интервала для среднего значения оценки). Как и следовало ожидать, интервал предсказания для значения прогнозируемой величины является более широким, чем доверительный интервал для среднего значения оценки. Действительно, формула для интервала предсказания такая же как и для доверительного интервала, но с той лишь разницей, что член 1/n под вторым квадратным корнем заменен на (n+1)/n.
Чтобы проверить, насколько линейная модель y* = a + bx соответствует исходным данным, необходимо вычислить коэффициент корреляции r по формуле:
____________________
n __ / n _ n _
r = (åyixi - nyx) / Ö (å xi2 - nx2)(åyi2 - ny2)
i=1 i=1 i=1
где -1 £ r £ 1.
Если r = ± 1, тогда линейная модель идеально подходит для описания зависимости между y и x. В общем случае, чем ближе | r | к 1, тем лучше подходит линейная модель. Если же r = 0, величины y и x могут быть независимыми. В действительности равенство r = 0 является лишь необходимым, но не достаточным условием независимости, т.к. возможен случай, когда для двух зависимых величин коэффициент корреляции будет равен 0.
Пример 3.
Применим модель линейной регрессии к данным из примера 1, которые для удобства приведены в таблице
| Месяц, xi | Спрос yi | Месяц xi | Спрос yi |
Из данных этой таблицы получаем следующее
24 24 24 24 24
å yixi = 17842, å xi = 300, å x2i = 4900, å yi = 1374, å y2i = 80254.
i=1 i=1 i=1 i=1 i=1
Следовательно,
x = 12.5, y = 57.25,
b = (17842 - 24´ 57.25´12.5)/(4900 - 24´(12.5)2),
a = 57.25 - 0.58´12.5 = 50.
Таким образом, оценка спроса представляется формулой
y* = 50 + 0.58x.
Например, при x = 25 получаем y* = 50+0.58´25 = 64.5 единицы.
Вычисляем коэффициент корреляции:
_________________________________
r = (17842 - 24´57.25´12.5) / Ö(4900 - 24´(12.5)2)(80.254 - 24´(57.25)2) = 0.493
Относительно малое значение коэффициента корреляции r указывает на то, что линейная модель y* = 50 + 0.58x является не совсем подходящей для исходных данных. Считается, как правило, что линейная модель подходит для исходных данных, если 0.75 £ | r | £ 1.
Предположим, что необходимо вычислить 95% доверительный интервал для полученной линейной оценки. Для этого надо сначала вычислить сумму квадратов отклонений от аппроксимирующей прямой. В таблице приведены результаты этих вычислений.
| s | d | d* | (d - d*) |
| 50.58 | 20.98 | ||
| 51.16 | 23.43 | ||
| 51.74 | 5.11 | ||
| 54.32 | 86.86 | ||
| 52.90 | 16.81 | ||
| 53.48 | 6.35 | ||
| 54.06 | 152.77 | ||
| 54.64 | 54.17 | ||
| 55.22 | 27.25 | ||
| 55.80 | 0.04 | ||
| 56.38 | 87.98 | ||
| 56.96 | 0.92 | ||
| 57.54 | 12.53 | ||
| 58.12 | 259.85 | ||
| 58.70 | 28.09 | ||
| 59.28 | 0.52 | ||
| 59.86 | 102.82 | ||
| 60.44 | 30.91 | ||
| 61.02 | 16.16 | ||
| 61.60 | 43.56 | ||
| 62.18 | 103.63 | ||
| 62.76 | 0.58 | ||
| 63.34 | 44.53 | ||
| 63.92 | 65.29 | ||
| 24 å (yi - y*i)2 = 1088.70 i=1 |
Табличное значение критерия Стьюдента t0.025,22 = 2.074. Следовательно, искомый доверительный интервал имеет вид:
__________ _________________________________
(50 + 0.58x0)±2.074Ö1088.7/(24-2)Ö1/24 + [(x0 - 12.5)2 / (4900 - 24´(12.5)2)].
Это выражение можно упростить, в результате получим следующее:
______________________
(50 + 0.58x0)±14.59Ö0.042 + [(x0 - 12.5)2 / 1150.
Чтобы продемонстрировать применение этой формулы, вычислим интервал предсказания для оценки спроса на следующий месяц (x0 = 25). В этом случае коэффициент 0.042 должен быть заменен на (1.042)2, и соответствующий интервал предсказания определяется как (64.5±15.82) или (46.68, 80.32). Следовательно, можно сказать, что с вероятностью 95% спрос для x = 25 будет находиться между 46.68 и 80.32 единицами.
Выше рассмотрены три метода прогнозирования хода инновационного проекта, основанных на теории исследования операций. Применимость каждого из них связана с характеристиками временного ряда, представляющего исходные данные. Ознакомиться с другими методиками прогнозирования можно, например, по […].
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 891; Нарушение авторских прав?; Мы поможем в написании вашей работы!