КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Структура процесорного елементу
|
|
|
|
У більшості матричних SIMD-систем як процесорні елементи застосовуються прості RISC-процесори з локальною пам'яттю обмеженої місткості.
Наприклад, кожен ПЕ системи MasPar MP-1 складається з чотирьохрозрядного процесора з пам'яттю місткістю 64 Кбайт. У системі МРР використовуються однорозрядні процесори з пам'яттю 1 кбіт кожен, а в СМ-2 процесорний елемент є однорозрядний процесор з 64 Кбіт локальної пам'яті. Завдяки простоті ПЕ масив може бути реалізований у вигляді однієї надвеликої інтегральної мікросхеми (НВІС). Це дозволяє скоротити число зв'язків між мікросхемами і, отже, габарити КС. Так, одна НВІС в системі СМ-2 містить 16 процесорів (без блоків пам'яті), а в системі MasPar MP-1 НВІС складається з 32 процесорів (також без блоків пам'яті). У системі МР-2 є видимим тенденція до застосування складніших мікросхем, зокрема 32-розрядних процесорів з 256 Кбайт пам'яті в кожному.
Невід'ємними компонентами ПЕ (рис.4.6) в більшості обчислювальних систем є:
- арифметико-логічний пристрій (АЛП);
- регістри даних;
- мережевий інтерфейс (МІ), який може включати в свій склад регістри пересилки даних;
- номер процесора;
- регістр прапора дозволу маскування (F);
- локальна пам'ять.
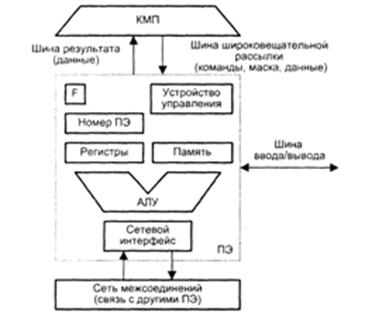
Рисунок 4.6 – Структура процесорного елемента
Процесорні елементи, керовані командами, що поступають по широкомовній шині з КМП, можуть вибирати дані з своєї локальної пам'яті і регістрів, обробляти їх в АЛП і зберігати результати в регістрах і локальній пам'яті. ПЕ можуть також обробляти ті дані, які поступають по шині широкомовної розсилки з КМП. Крім того, кожен процесорний елемент має право отримувати дані з інших ПЕ і відправляти їх в інші ПЕ по мережі з'єднань, використовуючи для цього свій мережевий інтерфейс. У деяких матричних системах, зокрема в MasParМР-1, елемент даних з ПЕ-джерела можна передавати в ПЕ-приймач безпосередньо, тоді як в інших, наприклад в МРР, - дані заздалегідь повинні бути розміщені в спеціальний регістр пересилки даних, що входить до складу мережевого інтерфейсу. Пересилка даних між ПЕ і пристроями введення/виведення здійснюється через шину введення/виведення КС. У ряді систем (MasParMP-1) ПЕ підключені до шини введення/виведення за допомогою мережі з'єднань і каналу введення/виведення системи. Результати обчислень будь-який ПЕ видає в КМП через шину результату.
Кожному з N ПЕ в масиві процесорів привласнюється унікальний номер, званий також адресою ПЕ, яка є цілим числом від 0 до N- 1. Щоб вказати, чи повинен даний ПЕ брати участь в загальній операції, в його складі є регістр прапора дозволу F. Стан цього регістра визначають сигнали управління з КМП, або результати операцій в самому ПЕ, або і ті та інші спільно.
Ще однією істотною характеристикою матричної системи є спосіб синхронізації роботи ПЕ. Оскільки всі ПЕ отримують і виконують команди одночасно, їх робота жорстко синхронізується. Це особливо важливо в операціях пересилки інформації між ПЕ. У системах, де обмін проводиться з чотирма сусідніми ПЕ, передача інформації здійснюється в режимі “регістр- регістр”.
4.5 Підключення і відключення процесорних елементів.
В процесі обчислень у ряді операцій повинні брати участь тільки певні ПЕ, тоді як решта ПЕ залишається недіючою. Дозвіл і заборона роботи ПЕ можуть виходити від контроллера масиву процесорів (глобальне маскування) і реалізуються за допомогою схем маскування ПЕ. В цьому випадку рішення про необхідність маскування ухвалюється на етапі компіляції коду. Рішення про маскування може також ухвалюватися під час виконання програми (маскування, визначене даними), при цьому спираються на той прапор дозволу маскування F, що зберігається в ПЕ.
При маскуванні, визначеному даними, кожен ПЕ самостійно оголошує свій статус “подключений/непідключений”. У складі системи команд є набори маскованих і немаскованих команд. Масковані команди виконуються залежно від стану прапора F, тоді як немасковані прапор просто ігнорують.
Процедуру маскування розглянемо на прикладі пропозиції IF-THEN-ELSE. Нехай х - локальна змінна (що зберігається в локальній пам'яті кожного ПЕ). Припустимо, що процесорні елементи масиву паралельно виконують, розгалуження:
If (х > 0) then < оператор А> else < оператор В >
і кожен ПЕ оцінює умову IF. Тобто ПЕ, для яких умова х > 0 справедливо, встановлять свій прапор F в одиницю, тоді як решта ПЕ - в нуль. Далі КМП розподіляє оператор А по всіх ПЕ. Команди, що реалізовують цей оператор, повинні бути маскованими. Оператор А буде виконаний тільки тими ПЕ, де прапор F встановлений в одиницю. Далі КМП передає у все ПЕ немасковану команду ELSE, яка примусить всі ПЕ інвертувати стан свого прапора F. Потім КМП транслює у всі ПЕ оператор В, який також повинен складатися з маскованих команд. Оператор буде виконаний тими ПЕ, де прапор F після інвертування був встановлений в одиницю, тобто де результат перевірки умови х > 0 був негативним.
При використанні схеми глобального маскування контролер масиву процесорів разом з командами посилає у всі ПЕ глобальну маску. Кожен ПЕ декодує цю маску і по результату з'ясовує, чи повинен він виконувати дану команду чи ні. Глобальні і локальні схеми маскування можуть комбінуватися. У такому разі активність ПЕ в рівній мірі визначається як прапором F, так і глобальною маскою.
4.6 Мережі взаємозв'язків процесорних елементів.
Ефективність мережевих взаємозв'язків процесорних елементів багато в чому визначає можливу продуктивність всієї матричної системи. Застосування знаходять найрізноманітніші топології мереж.
Оскільки процесорні елементи в матричних системах функціонують синхронно, обмінюватися інформацією вони також повинні по узгодженій схемі, причому необхідно забезпечити можливість синхронної передачі від декількох ПЕ-джерел до одного ПЕ-приймача. Коли для передачі інформації в мережевому інтерфейсі задіюється тільки один регістр пересилки даних, це може привести до втрати даних, тому у ряді КС для запобігання подібній ситуації передбачені спеціальні механізми. Так, в системі СМ-2 використовується устаткування, об'єднуюче повідомлення, що поступили до одного ПЕ.
У деяких SIMD-системах, наприклад МР-1, є можливість записати повідомлення, що одночасно прийшли, в різні елементи локальної пам'яті.
Хоча пересилки даних по мережі ініціюються тільки активними ПЕ, пасивні процесорні елементи також вносять внесок до цих операцій. Якщо активний ПЕ ініціює читання з іншого ПЕ, операція виконується незалежно від статусу ПЕ, з якого прочитується інформація. Те ж саме відбувається і при записі.
Найбільш поширеними топологіями в матричних системах є гратчасті і гіперкубічні. Так, в ILLIAC IV, МРР і СМ-2 кожен ПЕ сполучений з чотирма сусідніми. У МР-1 і МР-2 кожен ПЕ пов'язаний з вісьма суміжними ПЕ. У ряді систем реалізуються багатоступінчаті динамічні мережі з'єднань (МР-1, МР-2, GF11).
Контрольні запитання
1 Які є типи архітектурної організації масиву процесорних елементів у матричних SIMD-системах?
2 Яка різниця між матричними і векторними комп’ютерними системами?
3 З яких компонентів складається матрична комп’ютерна система?
4 Які функції контролера масиву процесорів?
5 Які компоненти процесорного елемента?
Лекція № 5
Комп’ютерні системи класу SIMD
Комп’ютерні системи класу SIMD (Single Instruction stream / Multiple Data stream) характеризуються одиничним потоком команд і множинним потоком даних. Дані системи виконують одну арифметичну операцію відразу над багатьма даними – елементами вектора (рис.5.1).
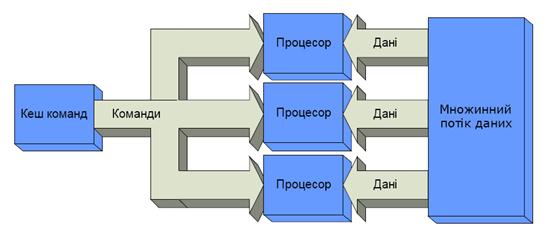
Рисунок 5.1 – Структура обчислювальних систем класу SIMD
Безперечними представниками класу SIMD вважаються матриці процесорів: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 і т.п. У таких системах єдиний керуючий пристрій контролює безліч процесорних елементів. Кожен процесорний елемент одержує від пристрою керування в кожен фіксований момент часу однакову команду і виконує її над своїми локальними даними.
Іншим підкласом SIMD-систем є векторні комп'ютери. Векторні комп'ютери маніпулюють масивами схожих даних подібно тому, як скалярні машини обробляють окремі елементи таких масивів. Це робиться за рахунок використання спеціально сконструйованих векторних центральних процесорів. При роботі у векторному режимі векторні процесори обробляють дані практично паралельно, що робить їх в кілька разів швидшими, ніж при роботі в скалярному режимі. Прикладом таких систем є Hitachi S2600.
Матрична система ILLIAC IV (ILLInois Automated Computer) створена університетом Ілінойса і корпорацією Берроуз (Burroughs Corporation). Вона розроблялася з 1966 і в 1972 система експлуатувалася в Науково-дослідному центрі НАСА (NASA - National Aeronautics and Space Administration - Національне управління аеронавтики і космосу):
- кількість процесорів в системі - 64;
- швидкодія - 2*108 опер./с;
- місткість оперативної пам'яті - 1 Мбайт;
- корисний час складає 80-85% загального часу роботи ILLIAC IV;
- вартість 40 000 000 дол.;
- вага 75 т;
- займана площа 930 м2.
Система ILLIAC IV була включена в обчислювальну мережу ARPA (Advanced Research Projects Agency - Управління перспективних досліджень і розробок Міністерства оборони США) і успішно експлуатувалося до 1981 р (рис.5.2).
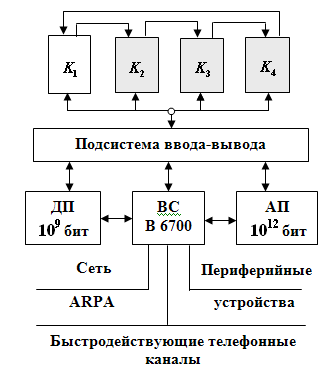
Рисунок 5.2 – Функціональна структура системи ILLIAC IV
Матрична обчислювальна система ILLIAC IV повинна була складатися з 4 квадрантів (К1-К4), підсистеми введення-виведення інформації, керуючої КС B 6700 (або B 6500), дискової пам'яті (ДП) і архівної пам'яті (АП). Планувалося, що КС забезпечить швидкодію 109 опер./с. У реалізованому варіанті ILLIAC IV містився тільки один квадрант, що забезпечив швидкодію 2*108 опер./с. При цьому ILLIAC IV залишалася самою швидкодіючою обчислювальною системою аж до 80-х років 20 сторіччя.
Квадрант - матричний процесор, що включав пристрій управління і 64 елементарних процесора. Пристрій управління був спеціалізованою ЕОМ, яка використовувалася для виконання операцій над скалярами і формувала потік команд на матрицю ПЕ. Елементарні процесори матриці були пов'язані один з одним. Структура квадранта системи ILLIAC IV представлялася двовимірними гратами, в яких граничні ПЕ були зв'язані по канонічній схемі (циркулянтним графом), що можна зобразити у вигляді плоских грат, де вузли в кожному стовпці замкнуті в кільце, а вузли в послідовних рядах сполучені в замкнуту спіраль. Другий варіант уявлення - хордальне кільце з кроком хорди рівному 4 (рис.5.3).
Кожен ПЕ мав:
- накопичуючий суматор (64 розряди);
- регістр другого операнда (64 розряди);
- регістр передаваної інформації з даного ПЕ в сусідній ПЕ (64 розряди);
- регістр, що використався як тимчасова пам'ять (64 розряди);
- регістр модифікації адресного поля команди (16 розрядів);
- регістр стану даного ПЕ (8 розрядів).
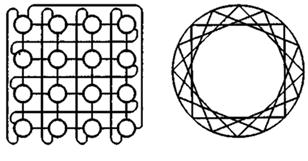
Рисунок 5.3 – Структура міжпроцесорних зв'язків в ILLIAC IV
ПЕ міг знаходитися в одному з двох станів - активному або пасивному. У першому стані йому дозволялося, а в другому заборонялося виконувати команди, що поступали з пристрою управління. Стан ПЕ задавався за допомогою спеціальних команд. Накопичуючий суматор і всі регістри ПЕ були програмно адресуємі.
Пам'ять кожного ПЕ - 16 Кб. До кожної пам'яті безпосередній доступ мав власний ПЕ. Обмін інформацією між пам’яттями різних ПЕ здійснювався по мережі зв'язку за допомогою спеціальних команд пересилок.
Підсистема введення/виведення складалася з пристрою управління, буферного пристрою, що запам'ятовує, і комутатора. Комплекс цих пристроїв забезпечував обмін інформацією між квадрантами ILLIAC IV і засобами введення/виведення: ЕОМ В 6700, дисковою і архівною пам'яттю, периферійними пристроями, мережею ARPA.
Керуюча КС В 6700 - це мультипроцесорна система корпорації Burroughs, яка могла мати в своєму складі від 1 до 3 центральних процесорів і від 1 до 3 процесорів введення/виведення інформації і володіла швидкодією 1-3 млн. операцій в секунду. Вона використовувалася для реалізації функцій операційної системи (включаючи уведення-виведення інформації, операції по компіляції і компоновці програм, розподіл апаратних ресурсів, виконання службових програм і т.п.).
Дискова пам'ять (ДП) складалася з двох дисків і обрамляючих електронних схем.
Ця пам'ять мала місткість близько 109 біт і була забезпечена двома каналами, по кожному з яких можна було паралельно передавати і приймати інформацію із швидкістю 0,5*109 біт/с. Середній час звернення до диска 20 мс.
Архівна пам'ять (АП) - постійна лазерна пам'ять з одноразовим записом, розроблена фірмою Precision Instrument Company.
У системі ILLIAC IV налічувалося більше 6*106 електронних компонентів. Відмови компонентів або з'єднань могли відбуватися через декілька годин. З цієї причини в систему була включена обширна бібліотека контрольних і діагностичних тестів.
Засоби програмування ILLIAC IV включали мову асемблер (Assembler Language) і три мови високого рівня: Tranquil, Glynpir, FORTRAN. Мови високого рівня через архітектурні особливості ILLIAC IV відрізнялися від відповідних мов ЕОМ в частині розподілу двовимірної пам'яті, операцій над векторами і пересилок даних.
Контрольні запитання
1 На які підкласи ділиться клас комп’ютерних систем SIMD?
2 Коли була розроблена комп’ютерна система ILLIAC IV?
3 Що означає термін “квадрант”?
Лекція № 6
Мультипроцесорні комп’ютерні системи
6.1 Загальна характеристика мультипроцесорних комп’ютерних систем
В мультипроцесорних КС спільним ресурсом є оперативна пам’ять. Паралельна робота процесорів і використання загальної оперативної пам’яті забезпечується управлінням єдиної операційної системи.
В мультипроцесорних КС швидкодія і надійність істотно вищі від аналогічних показників мультикомп’ютерних КС, що взаємодіють на рівні каналів зв'язку. Це відбувається, по-перше, завдяки більш швидкому обміну інформацією між процесорами і швидшому реагуванню на ситуації, що виникають у системі, по-друге, унаслідок більшого ступеня резервування пристроїв системи (система зберігає працездатність, поки працездатні хоч би по одному модулю кожного типу пристроїв).
В більшості випадків мультипроцесорні КС реалізовані в суперкомп'ютерах. Багато дослідників вважають, що використання мультипроцесорних КС є основним шляхом розвитку обчислювальної техніки нових поколінь.
Якщо всі процесори мають рівний доступ до всіх модулів пам'яті і до всіх пристроїв введення/виведення і кожен процесор взаємозамінний з іншими процесорами, то така система називається симетричним мультипроцесором (SMP - Symmetric Multiprocessor), якщо ні, то така система називається асиметричним мультипроцесором ( АSMP ).
Симетричні мультипроцесорні КС (SMP) бувають з архітектурою UMA, COMA, NUMA.
У системах із загальною пам'яттю всі процесори мають рівні можливості по доступу до єдиного адресного простору. Єдина пам'ять може бути побудована як одноблокова або за модульним принципом, але зазвичай практикується другий варіант.
Обчислювальні системи із загальною пам'яттю, де доступ будь-якого процесора до пам'яті проводиться одноково і займає однаковий час, називають системами з однорідним доступом до пам'яті і позначають абревіатурою UMA (Uniform Memory Access). Це найбільш поширена архітектура пам'яті паралельних КС із загальною пам'яттю.
Технічно UMA-системи припускають наявність вузла, що сполучає кожний з процесорів з кожним з модулів пам'яті. Найпростіший шлях побудови таких КС - об'єднання декількох процесорів з єдиною пам'яттю за допомогою загальної шини (рис.6.1). Проте, в цьому випадку в кожен момент часу обмін по шині може вести тільки один з процесорів, тобто процесори повинні змагатися за доступ до шини. Коли процесор Рi, вибирає з пам'яті команду, решта процесорів повинна чекати, поки шина звільниться. Якщо в систему входять тільки два процесори, вони в змозі працювати з продуктивністю, близькою до максимальної, оскільки їх доступ до шини можна чергувати (поки один процесор декодує і виконує команду, інший має право використовувати шину для вибору з пам'яті наступної команди). Проте коли додається третій процесор, продуктивність починає падати (рис.6.2). За наявності на шині десяти процесорів, крива швидкодії шини стає горизонтальною, так що додавання 11-го процесора вже не дає підвищення продуктивності (рис.6.2). Тому дана схема широкого застосування не знайшла.
Можна оптимізувати архітектуру UMA, додаючи локальний кеш і локальну пам'ять до кожного з процесорів (рис.6.3).
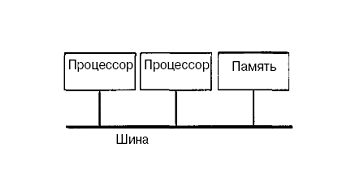
Рисунок 6.1 – Архітектура UMA
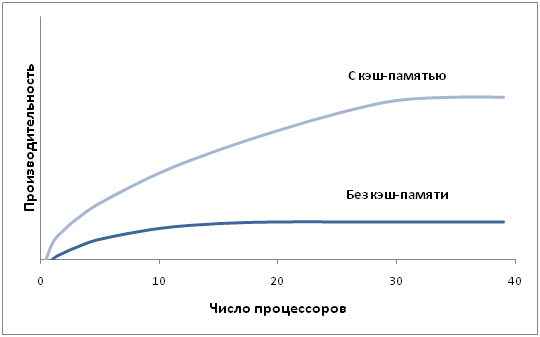
Рисунок 6.2 – Продуктивність багатопроцесорних КС з архітектурою UMA
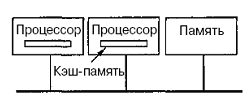
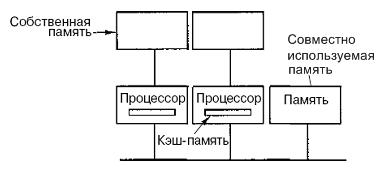
Рисунок 6.3 – Оптимізована архітектура UMA
Щоб оптимально використовувати конфігурацію вказану на рис.6.3, компілятор повинен помістити в локальні модулі пам'яті весь текст програми, ланцюжки, константи, інші дані, призначені тільки для читання, стечи і локальні змінні. Загальна розділена пам'ять використовується тільки для загальних змінних. В більшості випадків таке розумне розміщення сильно скорочує кількість даних, що передаються по шині, і не вимагає активного втручання з боку компілятора.
Навіть при всіх можливих оптимізаціях використання тільки однієї шини обмежує розмір мультипроцесора UMA до 16 або 32 процесорів. Щоб отримати більший розмір, потрібний інший тип комунікаційної мережі. Найпростіша схема з'єднання n процесорів з k блоками пам'яті через координатний комутатор (рис.6.4). Координатні комутатори використовуються впродовж багатьох десятиліть для з'єднання групи вхідних ліній з рядом вихідних ліній довільним чином.
Координатний комутатор є мережею, що не блокується. Це означає, що процесор завжди буде зв'язаний з потрібним блоком пам'яті, навіть якщо якась лінія або вузол вже зайняті. Більш того, ніякого попереднього планування не потрібно.
Недолік системи: зростання вузлів як n2. За наявності 1000 процесорів і 1000 модулів пам'яті отримуємо число вузлів - 1 млн. Це неприйнятно. Проте координатні комутатори можна застосовувати для систем середніх розмірів.
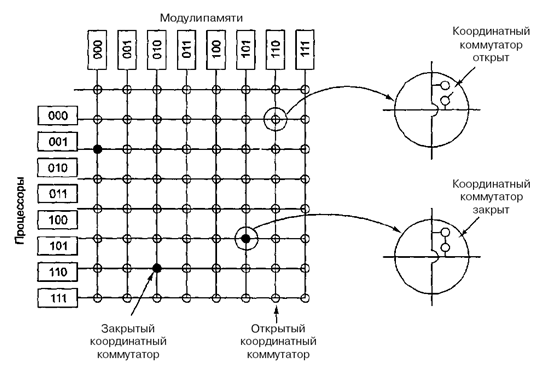
Рисунок 6.4 – Координатний комутатор
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1019; Нарушение авторских прав?; Мы поможем в написании вашей работы!