КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Складені оголошення
|
|
|
|
Прості оголошення в мові Сі дозволяють визначати прості змінні, масиви, покажчики, функції, структури та об'єднання.
В найпростішому випадку, якщо оголошується проста змінна базового типу, типу структури або об'єднання, ідентифікатор описується типу, що заданий специфікацією типу.
Для оголошення масиву значень деякого типу, функції, що повертає значення деякого типу, або покажчика на значення деякого типу, ідентифікатор доповнюється відповідно квадратними дужками […] справа, круглими дужками (…) справа або ознакою покажчика - зірочкою (*) зліва.
Наступні приклади ілюструють найпростіші форми оголошень:
int list[20]; /* масив list із 20 цілих значень */
char *cp; /* покажчик cp на значення типу char */
double func(); /* функція func(), що повертає значення типу double*/
Синтаксис оголошення:
[ клас_пам'яті ] тип ідентифікатор [ = ініціалізатор ];
Оголошення складаються з чотирьох частин:
1. необов'язкового специфікатора класу пам'яті (auto, register, static, extern);
2. базового типу або типу користувача;
3. оголошуючої частини;
4. необов'язкового ініціалізатора.
Оголошуюча частина в свою чергу складається з ідентифікатора і, можливо, операторів оголошення. Найчастіше використовуються наступні оператори оголошення (таблиця 1.18).
Таблиця 1.18. "Оператори оголошення"
| * | покажчик | префікс |
| *const | константний покажчик | префікс |
| & | посилання (адреса) | префікс |
| [ ] | масив | суфікс |
| () | функція | суфікс |
Суфіксні оператори оголошення "міцніше зв'язані" з ім'ям, ніж префіксні. Тому typename *str[]; означає масив покажчиків на деякі об'єкти, а для визначення типів таких як "покажчик на функцію" необхідно використовувати дужки.
Складене оголошення - це ідентифікатор, що доповнений більше ніж однією ознакою масиву, покажчика, або функції.
З одним ідентифікатором можна створити множину різних комбінацій ознак типу масив, покажчик або функція. Причому, деякі комбінації неприпустимі. Наприклад, масив не може містити в якості елементів функцію, а функція не може повертати масив або функцію.
При інтерпретації складених оголошень спочатку розглядають квадратні і круглі дужки, що розташовані справа від ідентифікатора. Квадратні і круглі дужки мають однаковий пріоритет. Вони інтерпретуються зліва направо. Після них розглядаються зірочки, що розташовані зліва від ідентифікатора. Специфікація типу розглядається на останньому етапі, після того, як все складене оголошення проінтерпретоване.
Круглі дужки можуть також використовуватися для зміни існуючого по замовчуванню порядку інтерпретації оголошення. Наприклад:
int *func(); /*функція, що повертає покажчик на int */
int (*func)();/*покажчик на функцію, що повертає int */
Алгоритм інтерпретації складених оголошень:
1. Знайти ідентифікатор (якщо їх декілька, то необхідно почати з того, який знаходить ближче до "середини" складеного оголошення).
2. Подивитися вправо:
• Якщо справа розташована відкриваюча кругла дужка - тоді це функція, а вираз, що розташований між цією відкриваючою дужкою '(' і відповідною їй закриваючою дужкою ')' необхідно інтерпретувати як параметри функції.
• Якщо справа стоїть відкриваюча квадратна дужка '[' - тоді це масив і вираз між відповідними квадратними дужками […] необхідно інтерпретувати як розмір масиву. Примітка: якщо масив багатовимірний, то за дужками […] розташовується ще одна або декілька серій квадратних дужок […].
• Якщо на будь-якому етапі інтерпретації справа зустрічається закриваюча кругла дужка ')', то необхідно спочатку повністю провести інтерпретацію всередині даної пари круглих дужок, а потім подовжити інтерпретацію справа від закриваючої круглої дужки ')'.
3. Якщо зліва від проінтерпретованого виразу розташована зірочка і:
• проінтерпретований вираз є функцією, то вона повертає покажчик;
• проінтерпретований вираз є масивом, то кожний елемент цього масиву є покажчиком;
• проінтерпретований вираз не є ні функцію, ні масивом, то вираз є покажчиком.
4. Застосувати описані вище правила (2-3 пункт алгоритму) ще раз.
5. Проінтерпретувати специфікацію типу даних.
Приклад інтерпретації складених оголошень:

1. Ідентифікатор var оголошений як
2. покажчик на
3. функцію, що приймає в якості аргументу масив із ста значень типу char і повертає
4. покажчик на
5. масив із ста елементів, кожний з яких є
6. покажчиком на
7. значення типу char.
1.17.1 Описи з модифікаторами
Використання в оголошеннях спеціальних ключових слів (модифікаторів) дозволяють надавати оголошенням спеціального змісту. Інформація, яку несуть в собі модифікатори, використовуються компілятором мови Сі в процесі генерування коду.
Розглянемо правила інтерпретації оголошень, що містять модифікатори const, volatile, cdecl, pascal, near, far, huge, interrupt.
Модифікатори cdecl, pascal, interrupt повинні розташовуватися безпосередньо перед ідентифікатором.
Модифікатори const, volatile, near, far, huge впливають або на ідентифікатор, або на ознаку покажчика (зірочку), що розташована безпосередньо справа від модифікатора. Якщо справа розташований ідентифікатор, то модифікується тип об'єкта, що іменується даним ідентифікатором. Якщо ж справа розташована зірочка, то ця зірочка представляє собою покажчик на модифікований тип. Таким чином, конструкція
модифікатор *
читається як "покажчик на модифікований тип".
Наприклад,
int const *p; /* покажчик на цілу константу */
int *const p; /* константний покажчик на величину типу int */
Модифікатори типу const і volatile можуть також розташовуватися і перед специфікацією типу.
В ТС використання модифікаторів near, far, huge обмежене: вони можуть бути записані тільки перед ідентифікатором функції або перед ознакою покажчика (зірочкою).
Допускається більше одного модифікатора для одного об'єкта (або елемента оголошення). В наступному прикладі тип функції func модифікується одночасно спеціальними ключовими словами far і pascal. Порядок ключових слів неважливий, тобто комбінації far pascal і pascal far мають однаковий зміст.
int far * pascal far func();
Тип значення, що повертається функцією func, представляє собою покажчик на значення типу int. Тип цих значень модифікований спеціальним ключовим словом far.
Як і звичайно, в оголошенні можуть бути використані круглі дужки для зміни порядку його інтерпретації.
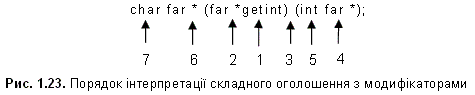
В даному прикладі наведене оголошення з різними варіантами розташування модифікатора far. Враховуючи правило, відповідно до якого модифікатор впливає на елемент оголошення, розташований справа від нього, можна інтерпретувати це оголошення наступним чином.
1. Ідентифікатор getint оголошений як
2. покажчик на far
3. функцію, що приймає
4. один аргумент, який є покажчиком на far
5. значення типу int
6. і повертає покажчик на far
7. значення типу char
1.17.2 Модифікатори const і volatile
Про модифікатор const йшла мова в розділі 1.2.3."Константи". Модифікатор const не допускає явного присвоювання змінній або інших дій, що можуть вплинути на зміну її значення, таких як виконання операції інкременту і декременту. Значення покажчика, що оголошений з модифікатором const, не може бути зміненим, на відміну від значення об'єкта, на який він вказує.
Модифікатори volatile і const протилежні за змістом.
Модифікатор volatile вказує на те, що значення змінної може бути зміненим; але не тільки безпосередньо програмою, а також і зовнішнім впливом (наприклад, програмою обробки переривань, або, якщо змінна відповідає порту введення/виведення, обміном із зовнішнім пристроєм). Оголошення об'єкта з модифікатором volatile попереджує компілятор мови Сі, чого не слід робити
Можливим також є одночасне використання в оголошенні модифікаторів const і volatile. Це означає, що значення змінної не може модифікуватися програмою, але піддається зовнішньому впливу.
Якщо з модифікатором const або volatile оголошується змінна складеного типу, то дія модифікатора розповсюджується на всі його складові елементи.
Примітка. При відсутності в оголошенні специфікації типу і присутності модифікатора const або volatile мається на увазі тип int.
Приклади:
float const pi=3.14159265;
const maxint=32767;
char *const str= "Деякий рядок."; /* покажчик-константа */
char const *str2= "Рядок";/* покажчик на константний рядок */
Із врахуванням наведених вище оголошень наступні оператори неприпустимими.
pi=3.0; /* присвоювання значення константі */
i=maxint--; /* зменшення константи */
str="Other string"; /* присвоювання значення константі-покажчику */
Однак виклик функції strcpy(str,"String"); припустимий, так як в даному випадку здійснюється посимвольне копіювання рядка в область пам'яті, на яку вказує покажчик.
Аналогічно, якщо покажчик на тип const присвоїти покажчику на тип, відмінний від const, то через отриманий покажчик можна здійснювати присвоювання.
1.17.3 Модифікатори cdecl і pascal
Результатом роботи компілятора мови Сі є файл, що містить об'єктний код програми. Файли з об'єктним кодом, що отримуються в результаті компіляції всіх файлів програми, компоновщик об'єднує в один файл виконання.
При компіляції всі глобальні ідентифікатори програми, тобто імена функцій і глобальних змінних, зберігаються в об'єктному коді і використовуються компоновщиком в процесі роботи. По замовчуванню ці ідентифікатори зберігаються в своєму початковому вигляді. Крім того, в якості першого символу кожного ідентифікатора компілятор мови Сі додає символ підкреслення.
Компоновщик по замовчуванню розрізняє великі та малі літери, тому ідентифікатори, що використовуються в різних файлах програми для іменування одного і того самого об'єкта, повинні повністю співпадати з точки зору як орфографії, так і регістрів літер. Для здійснення співпадіння ідентифікаторів, що використовуються в різномовних файлах, використовуються модифікатори pascal і cdecl.
Використання модифікатора pascal до ідентифікатора призводить до того, що ідентифікатор перетворюється до верхнього регістру і до нього не додається символ підкреслення. Цей ідентифікатор не може використовуватися для іменування в програмі на мові Сі глобального об'єкта, який використовується також в програмі на мові Паскаль. В об'єктному коді, що згенерований компілятором мови Сі, і в об'єктному коді, що згенерований компілятором мови Паскаль, ідентифікатор буде представлений ідентично.
Якщо модифікатор pascal застосовується до ідентифікатора функції, то він здійснює вплив також і на передачу аргументів функції. Засилання аргументів у стек здійснюється в цьому випадку не в оберненому порядку, як прийнято в компіляторах мови Сі, а в прямому - першим засилається в стек перший аргумент.
Функція типу pascal не може мати змінне число параметрів, як, наприклад, функція printf ().
Існує ще один модифікатор, яка присвоює всім функціям і покажчикам на функції тип pascal. Це означає, що вони будуть використовувати послідовність виклику, що прийнята в мові Паскаль, а їх ідентифікатори будуть можливими для виклику з програми на Паскалі. При цьому можна сказати, що деякі функції і покажчики на функції використовують викликаючу послідовність, прийняту в мові Сі, а їх ідентифікатори мають традиційний вигляд для ідентифікаторів мови Сі. Для цього їх оголошення повинні містити модифікатор cdecl.
1.17.4 Модифікатори near, far, huge
Ці модифікатори здійснюють вплив на роботу з адресами об'єктів.
Компілятор мови Сі дозволяє використовувати при компіляції одну з декількох моделей пам'яті.
Використання моделі пам'яті визначає розміщення програми і даних в ОП, а також внутрішній формат покажчиків. Однак при використанні будь-якої моделі пам'яті можна оголосити покажчик з форматом, що відрізняється від прийнятого по замовчуванню. Це здійснюється за допомогою модифікаторів near, far і huge.
Покажчик типу near - 16-бітовий; для визначення адреси об'єкта він використовує зсув відносно поточного вмісту сегментного регістру. Для покажчика типу near доступна пам'ять обмежена розміром поточного 64-кілобайтного сегмента даних.
Покажчик типу far - 32-бітовий; він містить як адресу сегменту, так і зсув. При використанні покажчиків типу far припустимі звернення до пам'яті в межах 1-мегабайтного адресного простору, однак значення покажчика типу far циклічно змінюється в межах 64-кілобайтного сегменту.
Покажчик типу huge - 32-бітовий; він також містить адресу сегменту і зсув. Значення покажчика типу huge може бути змінене в межах 1-мегабайтного адресного простору. В ТС покажчик huge завжди зберігається в нормалізованому форматі.
1.18.1 Директива #include
Синтаксис:
#include "ім'я_файла"
#include <ім'я_файла>
Директива #include використовується для включення копії вказаного файла в те місце програми, де знаходиться ця директива.
Різниця між двома формами директиви полягає в методі пошуку пре процесором файла, що включається. Якщо ім'я файла розміщене в "кутових" дужках < >, то послідовність пошуку препроцесором заданого файла в каталогах визначається встановленими каталогами включення (include directories). Якщо ж ім'я файла заключне в лапки, то препроцесор шукає в першу чергу файл у поточній директорії, а потім вже у каталогах включення.
Робота директиви #include зводиться практично до того, що директива #include прибирається, а на її місце заноситься копія вказаного файла.
Текст файла, що включається може містити директиви препроцессора, і директиву #include зокрема. Це означає, що директива #include може бути вкладеною. Допустимий рівень вкладеності директиви #include залежить від конкретної реалізації компілятора.
#include <stdio.h> /* приклад 1*/
#include "defs.h" /* приклад 2*/
В першому прикладі у головний файл включається файл з ім'ям stdio.h. Кутові дужки повідомляють компілятору, що пошук файла необхідно здійснювати в директоріях, вказаних в командному рядку компіляції, а потім в стандартних директоріях.
В другому прикладі в головний файл включається файл з ім'ям defs.h. Подвійні лапки означають, що при пошуку файла спочатку повинна бути переглянута директорія, що містить поточний файл.
В ТС є також можливість задавати ім'я шляху в директиві #include за допомогою іменованої константи. Якщо за словом include слідує ідентифікатор, то препроцесор перевіряє, чи не іменує він константу або макровизначення. Якщо ж за словом include слідує рядок, що заключений в лапки або в кутові дужки, то ТС не буде шукати в ній ім'я константи.
#define myincl "c:\test\my.h"
#include myincl
1.18.2 Директива #define
Синтаксис:
#define ідентифікатор текст
#define ідентифікатор (список_параметрів) текст
Директива #define заміняє всі входження ідентифікатора у програмі на текст, що слідує в директиві за ідентифікатором. Цей процес називається макропідстановкою. Ідентифікатор замінюється лише в тому випадку, якщо він представляє собою окрему лексему. Наприклад, якщо ідентифікатор є частиною рядка або більш довгого ідентифікатора, він не замінюється. Якщо за ідентифікатором слідує список параметрів, то директива визначає макровизначення з параметрами.
Текст представляє собою набір лексем, таких як ключові слова, константи, ідентифікатори або вирази. Один або більше пробільних символів повинні відділяти текст від ідентифікатора (або заключених в дужки параметрів). Якщо текст не вміщується в рядку, то він може бути продовжений на наступному рядку; для цього слід набрати в кінці рядка символ обернений слеш \ і зразу за ним натиснути клавішу Enter.
Текст може бути опущений. В такому разі всі екземпляри ідентифікатора будуть вилучені з тексту програми. Але сам ідентифікатор розглядається як визначений і при перевірці директива # if дає значення 1.
Список параметрів, якщо він заданий, містить один або більше ідентифікаторів, розділених комами. Ідентифікатори в рядку параметрів повинні відрізнятися один від одного. Їх область дії обмежена макровизначенням. Список параметрів повинен бути заключений в круглі дужки. Імена формальних параметрів у тексті відмічають позиції, в які повинні бути підставлені фактичні аргументи макровиклику. Кожне ім'я формального параметра може з'явитися в тексті довільне число разів.
В макровиклику вслід за ідентифікатором записується в круглих дужках список фактичних аргументів, що відповідають формальних параметрам із списку параметрів. Текст модифікується шляхом заміни кожного формального параметра на відповідний фактичний параметр. Списки фактичних параметрів і формальних параметрів повинні мастити одне і те ж число елементів.
Примітка. Не слід плутати підстановку аргументів в макровизначеннях з передачею параметрів у функціях. Підстановка в препроцесорі носить чисто текстовий характер. Ніяких обчислень при перетворенні типу при цьому не виконується.
Вище вже говорилося, що макровизначення може містити більше одного входження даного формального параметра. Якщо формальний параметр представлений виразом з "побічним ефектом" і цей вираз буде обчислюватися більше одного разу, разом з ним кожний раз буде виникати і "побічний ефект". Результат виконання в цьому випадку може бути помилковим.
Всередині тексту в директиві # define можуть знаходитися вкладені імена інших макровизначень або констант.
Після того, як виконана макропідстановка, отриманий рядок знову переглядається для пошуку інших імен констант і макровизначень. При повторному перегляді не розглядається ім'я раніше проведеної макропідстановки. Тому директива
#define a a
не призведе до за циклювання препроцесора.
Приклад 1:
#define WIDTH 80
#define LENGTH (WIDTH+10)
В даному прикладі ідентифікатор WIDTH визначається як ціла константа із значенням 80, а ідентифікатор LENGTH - як текст (WIDTH+10). Кожне входження ідентифікатора LENGTH у програму буде замінено на текст (WIDTH+10), який після розширення ідентифікатора WIDTH перетвориться на вираз (80+10). Дужки дозволяють уникнути помилок в операторах, подібних наступному:
val=LENGTH*20;
Після обробки програми препроцесором текст набуде вигляду:
val=(80+10)*20;
Значення, яке буде присвоєно змінній val рівне 1800. При відсутності дужок значення val буде рівне 280.
val=80+10*20;
Приклад 2:
#define MAX(x,y) ((x)>(y))?(x):(y)
В даному прикладі визначається макровизначення MAX. Кожне входження ідентифікатора MAX в тексті програми буде замінено на вираз ((x)>(y))?(x):(y), в якому замість формальних параметрів x та y підставляються фактичні. Наприклад, макровиклик:
MAX(1,2)
заміниться на вираз ((1)>(2))?(1):(2).
1.18.3 Директива #undef
Синтаксис:
#undef ідентифікатор
Визначення символічних констант і макросів можуть бути анульовані за допомогою директиви препроцесора #undef. Таким чином, область дії символічної константи або макросу починається з місця їх визначення і закінчується явним їх анулюванням директивою #undef або кінцем файла.
Після анулювання ідентифікатор може бути знову використаний директивою #define.
Приклад:
#define WIDTH 80
/* … */
#undef WIDTH
/* … */
#define WIDTH 20
1.19 Динамічні структури даних
Незважаючи на те, що терміни тип даних та структура даних звучать дещо схоже, проте вони мають різний підтекст.
Як говорилося раніше, тип даних - це множина значень, які може приймати змінна деякого типу. А структури даних представляють собою набір даних, можливо різних типів, що об'єднані певним чином.
Базовим елементом структури даних є елемент (вузол), який призначений для зберігання певного типу даних. Якщо елементи зв'язані між собою за допомогою покажчиків, то такий спосіб організації даних називається динамічними структурами даних, так як їх розмір динамічно змінюється під час виконання програми.
З динамічних структур даних найчастіше використовуються лінійні списки, стеки, черги та бінарні дерева.
1.19.1 Лінійні списки
Лінійний список - це скінченна послідовність однотипних елементів (вузлів). Кількість елементів у цій послідовності називається довжиною списку. Наприклад:
F=(1,2,3,4,5,6) - лінійний список, його довжина 6.
При роботі зі списками дуже часто доводиться виконувати такі операції:
• додавання елемента в початок списку;
• вилучення елемента з початку списку;
• додавання елемента в будь-яке місце списку;
• вилучення елемента з будь-якого місця списку;
• перевірку, чи порожній список;
• очистку списку;
• друк списку.
Основні методи зберігання лінійних списків поділяються на методи послідовного та зв'язаного зберігання.
Послідовне зберігання списків. Метод послідовного зберігання списків ґрунтується на використанні масиву елементів деякого типу та змінної, в якій зберігається поточна кількість елементів списку.
#define MAX 100 /* максимально можлива довжина списку */
typedef struct
{
int x; /* тут потрібно описати структуру елементів списку*/
} elementtype;
typedef struct
{
elementtype elements[MAX];
int count;
} listtype;
У вищенаведеному фрагменті програми описуються типи даних elementtype (визначає структуру елемента списку) та listtype (містить масив для зберігання елементів та змінну для зберігання поточного розміру списку).
Наводимо приклади реалізації функцій для виконання основних операцій над списками.
1. Ініціалізація списку (робить список порожнім).
void list_reset(listtype *list)
{
list->count=0;
};
2. Додавання нового елементу у кінець списку.
void list_add(listtype *list,elementtype element)
{
if (list->count==MAX) return;
list->elements[list->count++]=element;
};
3. Додавання нового елементу в позицію pos.
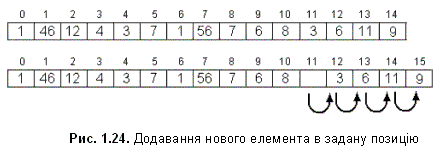
void list_insert(listtype *list,int pos,elementtype element)
{
int j;
if (pos<0||pos>list->count||pos>=MAX) return;
for (j=list->count;j>pos;j--)
{
list->elements[j]=list->elements[j-1];
};
list->elements[j]=element;
list->count++;
};
4. Вилучення елемента з номером pos.
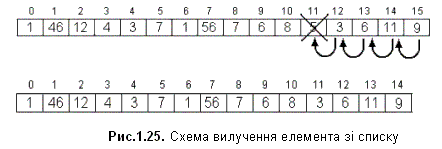
void list_delete(listtype *list,int pos)
{
int j;
if (pos<0||pos>list->count) return;
for (j=pos+1;j<list->count;j++)
{
list->elements[j-1]=list->elements[j];
};
list->count--;
};
5. Отримання елемента з номером pos.
int list_get(listtype *list,int pos,elementtype *element)
{
if (pos<0||pos>list->count)
{
return 0;
};
*element=list->elements[pos];
return 1;
};
При послідовному зберіганні списків за допомогою масивів елементи списку зберігаються в масиві. Така організація дозволяє легко переглядати вміст списку та додавати нові елементи в його кінець. Але такі операції, як вставка нового елемента в середину списку чи вилучення елементу з середини списку потребують зсуву всіх наступних елементів. При збільшенні елементів масиву кількість операцій, потрібна для впорядкування списку, стрімко зростає.
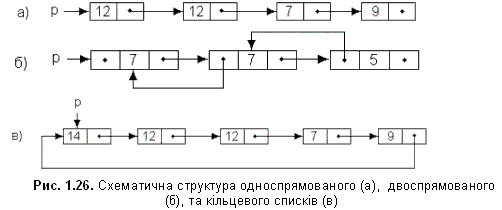
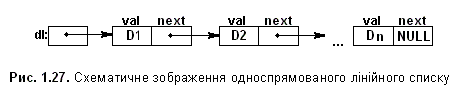
Зв'язане зберігання лінійних списків. Найпростіший спосіб зв'язати множину елементів - зробити так, щоб кожний елемент містив посилання на наступний. Такий список називається односпрямованим (однозв'язаним). Якщо додати в такий список ще й посилання на попередній елемент, то отримаємо двозв'язаний список. А список, перший та останній елементи якого зв'язані, називається кільцевим.
Структуру даних для зберігання односпрямованого лінійного списку можна описати таким чином:
typedef long elemtype;
typedef struct node
{
elemtype val;
struct node *next;
} list;
В даному фрагменті програми описуються декілька типів даних:
elemtype - визначає тип даних лінійного списку. Можна використовувати будь-який стандартний тип даних, включаючи структури.
list - визначає структуру елемента лінійного списку (val - значення, яке зберігається у вузлі, next - покажчик на наступний вузол).
Схематично лінійний односпрямований список виглядає так:
Реалізація основних операцій:
1. Включення елемента в початок списку.
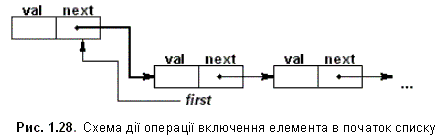
list *addbeg(list *first, elemtype x)
{
list *vsp;
vsp = (list *) malloc(sizeof(list));
vsp->val=x;
vsp->next=first;
first=vsp;
return first;
}
2. Видалення елемента з початку списку.
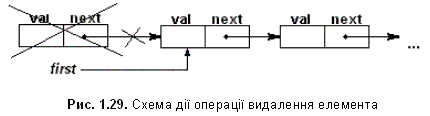
list *delbeg(list *first)
{
list *vsp;
vsp=first->next;
free(first);
return vsp;
}
3. Включення нового елемента у список.

list *add(list *pred, elemtype x)
{
list *vsp;
vsp = (list *) malloc(sizeof(list));
vsp->val=x;
vsp->next=pred->next;
pred->next=vsp;
return vsp;
}
4. Видалення елемента зі списку.

elemtype del(list *pred)
{
elemtype x;
list *vsp;
vsp=pred->next;
pred->next=pred->next->next;
x=vsp->val;
free(vsp);
return x;
}
5. Друк значень списку.
void print(list *first)
{
list *vsp;
vsp=first;
while (vsp)
{
printf("%i\n",vsp->val);
vsp=vsp->next;
}
}
6. Перевірка, чи порожній список
int pust(list *first)
{
return!first;
}
7. Знищення списку
list *kill(list *first)
{
while (!pust(first)) first=delbeg(first);
return first;
}
1.19.2 Стеки
Стек - динамічна структура даних, яка представляє собою впорядкований набір елементів, в якому додавання нових елементів і видалення існуючих проходить з одного кінця, який називається вершиною стека.
Стек реалізує принцип LIFO (last in - first out, останнім прийшов - першим пішов). Найбільш наглядним прикладом організації стеку може бути дитяча пірамідка, де додавання і знімання кілець здійснюється як раз відповідно до цього принципу.
Основні операції, які можна виконувати над стеками:
• додавання елемента в стек;
• вилучення елемента із стека;
• перевірка, чи порожній стек;
• перегляд елемента у вершині стека без видалення;
• очистка стека.
Стек створюється так само, як і лінійний список, так як стек є частковим випадком односпрямованого списку.
typedef long elemtype;
typedef struct node
{
elemtype val;
struct node *next;
} stack;
Реалізація основних операцій над стеками:
1. Початкове формування стеку
stack *first(elemtype d)
{
stack *pv=(stack*) calloc(1,sizeof(stack));
pv->val=d;
pv->next=NULL;
return pv;
};
2. Занесення значення в стек
void push(stack **top,elemtype d)
{
stack *pv=(stack*) calloc(1,sizeof(stack));
pv->val=d;
pv->next=*top;
*top=pv;
};
3. Вилучення елемента зі стека
elemtype pop(stack **top)
{
elemtype temp=(*top)->val;
stack *pv=*top;
*top=(*top)->next;
free(pv);
return temp;
};
1.19.3 Черги
Черга - це лінійний список, де елементи вилучаються з початку списку, а додаються в кінець (як звичайна черга в магазині).
Двостороння черга - це лінійний список, у якого операції додавання, вилучення і доступу до елементів можливі як спочатку так і в кінці списку. Таку чергу можна уявити як послідовність книг, що стоять на полиці так, що доступ до них можливий з обох кінців.
Черга є частковим випадком односпрямованого списку. Вона реалізує принцип FIFO (first in - first out, першим прийшов - першим пішов).
Черги створюються аналогічно до лінійних списків та стеків.
typedef long elemtype;
typedef struct node
{
elemtype val;
struct node *next;
} queue;
1. Початкове формування черги
queue *first (elemtype d)
{
queue *pv=(queue*) calloc(1,sizeof(queue));
pv->val=d;
pv->next=NULL;
return pv;
}
2. Додавання елемента в кінець
void add (queue **pend, elemtype d)
{
queue *pv=(queue*) calloc(1,sizeof(queue));
pv->val=d;
pv->next=NULL;
(*pend)->next=pv;
*pend=pv;
}
3. Вилучення елемента з кінця
elemtype del(queue **pbeg)
{
elemtype temp=(*pbeg)->val
queue *pv=*pbeg;
*pbeg=(*pbeg)->next;
free(pv)
return temp;
}
1.19.4 Двійкові дерева
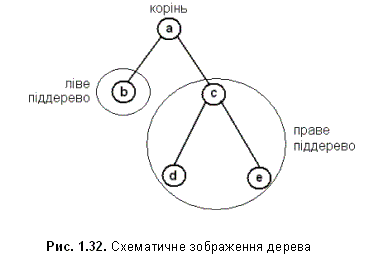
Бінарне дерево - це динамічна структура даних, що складається з вузлів (елементів), кожен з яких містить, окрім даних, не більше двох посилань на інші бінарні дерева. На кожен вузол припадає рівно одне посилання. Початковий вузол називається коренем дерева (рис 1.23.).
Якщо дерево організоване таким чином, що для кожного вузла всі ключі його лівого піддерева менші за ключ цього вузла, а всі ключі його правого піддерева - більші, воно називається деревом пошуку. Однакові ключі в деревах пошуку не допускаються.
В дереві пошуку можна знайти елемент за ключем, рухаючись від кореня і переходячи на ліве або праве піддерево в залежності від значення ключа в кожному вузлі. Такий спосіб набагато ефективніший пошуку по списку, так як час виконання операції пошуку визначається висотою дерева.
Дерево є рекурсивною структурою даних, так як кожне піддерево є також деревом. Дії з такими структурами даних простіше всього описувати за допомогою рекурсивних алгоритмів.
Наприклад, функцію обходу всіх вузлів дерева в загальному вигляді можна описати так:
function way(дерево)
{
way(ліве піддерево);
обробка кореня;
way(праве піддерево);
};
Можна обходити дерево і в іншому порядку, наприклад, спочатку корінь, а потім піддерева. Але наведена модель функції дозволяє отримати на виході відсортовану послідовність ключів, так як спочатку відвідуються вершини з меншими ключами, що розташовані в лівому піддереві.
Таким чином, дерева пошуку можна використовувати для сортування значень. При обході дерева вузли не видаляються.
Для бінарних дерев визначені наступні операції:
• включення вузла у дерево;
• пошук по дереву;
• обхід дерева;
• видалення вузла.
Для кожного рекурсивного алгоритму можна створити його нерекурсивний еквівалент.
Вузол бінарного дерева можна визначити як:
typedef struct sbtree
{
int val;
struct sbtree *left,*right;
} btree;
Реалізація деяких операцій з бінарними деревами.
1). Рекурсивний пошук в бінарному дереві. Функція повертає покажчик на знайдений вузол.:
btree *Search(btree *p, int v)
{
if (p==NULL) return(NULL); /* вітка порожня */
if (p->val == v) return(p); /* вершина знайдена */
if (p->val > v) /* порівняння з поточним вузлом */
return(Search(p->left,v)); /* ліве піддерево */
else
return(Search(p->right,v)); /* праве піддерево */
}
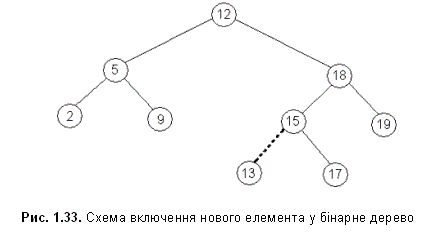
2). Включення значення в двійкове дерево (рис 1.33.):
btree *Insert(btree *pp, int v)
{
if (pp == NULL) /* знайдена порожня вітка */
{
btree *q = (btree*) calloc(1,sizeof(btree));
/* створити вершину дерева */
q->val = v; /* і повернути покажчик */
q->left = q->right = NULL;
return q;
}
if (pp->val == v) return pp;
if (pp->val > v) /* перейти в ліве піддерево */
pp->left=Insert(pp->left,v);
else
pp->right=Insert(pp->right,v);
/* перейти в праве піддерево*/
return pp;
}
3). Рекурсивний обхід двійкового дерева:
void Scan(btree *p)
{
if (p==NULL) return;
Scan(p->left);
printf("%i\n",p->val);
Scan(p->right);
}
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1169; Нарушение авторских прав?; Мы поможем в написании вашей работы!