КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Языки параллельного программирования
|
|
|
|
Основные классы современных параллельных компьютеров.
Классификация Хендлера
В основу классификации В.Хендлер закладывает явное описание
возможностепараллельнои конвейернообработки информации
вычислительно системо. При этом он намеренно не рассматривает различные способы связи между процессорами и блоками памяти и считает, что коммуникационная сеть может быть нужным образом сконфигурирована и будет способна выдержать предполагаемую нагрузку.
Предложенная классификация базируется на различии между тремя уровнями обработки данных в процессе выполнения программ:
• уровень выполнения программы - опираясь на счетчик команд и некоторые другие регистры, устройство управления (УУ) производит выборку и дешифрацию команд программы;
• уровень выполнения команд - арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему устройством управления;
• уровень битовой обработки - все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые для выполнения операций над одним двоичным разрядом.
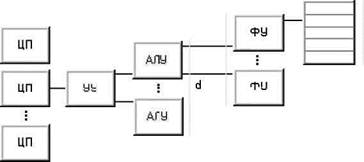
Таким образом, подобная схема выделения уровне предполагает, что вычислительная система включает какое-то число процессоров кажды со своим устроством управления. Каждое устроство управления связано с несколькими арифметико-логическими устроствами, исполняющими одну и ту же операцию в каждый конкретны момент времени. Наконец, каждое АЛУ объединяет несколько элементарных логических схем, ассоциированных с обработко одного двоичного разряда (число ЭЛС есть ничто иное, как длина машинного слова). Если на какое-то время не рассматривать возможность конвееризации, то число устройств управления к, число арифметико-логических устройств d в каждом устройстве управления и число элементарных логических схем w в каждом АЛУ составят тройку для описания данно вычислительно системы С:
t(C) = (k, d, w)
В таких обозначениях описания некоторых хорошо известных вычислительных систем будут выглядеть следующим образом:
t(MINIMA) = (1,1,1);
t(IBM 701) = (1,1,36);
t(SOLOMON) = (1,1024,1);
t(ILLIAC IV) = (1,64,64);
t(STARAN) = (1,8192,1) - в полно конфигурации;
t(C.mmp) = (16,1,16) - основной режим работы;
t(PRIME) = (5,1,16);
t(BBN Butterfly GP1000) = (256,-1,-32).
Несмотря на то, что перечисленным системам присущ параллелизм разного рода, он без особого труда может быть отнесен к одному из трех выделенных уровне.
на каждой ступени слово из w бит
|
| а" ФУ могут быть сцеплены |
w' ступеней конвейера
к' ЦП из к могут fjaOuiaib ы макршк-жьейери
Рис. 4.3. Уровни обработки данных в процессе выполнения программы
Теперь можно расширить возможности описания, допустив возможность конвейерно обработки на каждом из уровне (рис. 4.3). Конвейерность на самом нижнем уровне (т.е. на уровне ЭЛС) это конвейерность функциональных устройств. Если функциональное устройство обрабатывает w-разрядные слова на каждо из w' ступене конвеера, то для характеристики параллелизма данного уровня естественно рассмотреть произведение wxw'. Знак умножения х используется на каждом уровне чтобы отделить число, представляющее степень параллелизма, от числа ступене в конвейере. Компьютер TI ASC имеет четыре конвейерных устройства по восемь ступене в каждом для обработки 64-х разрядных слов, следовательно, он может быть описан так:
t(TI ASC) = (1,4,64x8)
Следующий уровень конвейерно обработки - это конвееризация на уровне команд. Предполагается, что в вычислительно системе есть несколько функциональных устройств, которые могут работать одновременно в рамках одного потока команд (в настоящее время используется специальны термин для
обозначения данно возможности - сцепление функциональных устройств). Классическим примером этому могут служить компьютеры фирмы Cray Research. А исторически перво является машина CDC 6600, содержащая десять независимых последовательных функциональных устройств, способных подавать результат свое работы на вход другим функциональным устройствам, образуя едины поток команд:
t(CDC 6600) = (1,1x10,-64)
(описан только центральны процессор без учета управляющих и периферийных подсистем).
Конвееризация на самом верхнем уровне, известна как макро-конвейер. Поток данных, проходя через один процессор, поступает на вход другому, возможно через некоторую буферную память. Если независимо работают п процессоров, то в идеальной ситуации при отсутствии конфликтов и полно сбалансированности получаем ускорение в п раз по сравнению с использованием только одного процессора. Так компьютер РЕРЕ, имея фактически три независимых системы из 288-ми устроств, описывается следующим образом:
t(РЕРЕ) = (1x3,288,32)
После расширения трехуровнево модели параллелизма средствами описания потенциальных возможносте конвееризации каждая тройка
t(РЕРЕ) = (kxk',dxd',wxw')
интерпретируется так:
• к - число процессоров (каждый со своим УУ), работающих параллельно
• к1 - глубина макроконвейера из отдельных процессоров
• d - число АЛУ в каждом процессоре, работающих параллельно
• сГ - число функциональных устройств АЛУ в цепочке
• w - число разрядов в слове, обрабатываемых в АЛУ параллельно
• w' - число ступеней в конвейере функциональных устройств АЛУ
Очевидна связь между классификацие Фенга и классификацие Хендлера:
для получения максимально степени параллелизма в терминах Фенга надо найти произведение всех шести величин в описании Хендлера. Здесь же заметим, что заложив в основу свое схемы явное указание на присутствующи параллелизм и возможную конвееризацию, В.Хендлер сразу снимает массу вопросов, характерных для предшествующих схем Флинна и Фенга в плане описания векторно-конвейерных машин.
В дополнение к изложенному способу описания архитектур Хендлер предлагает использовать три операции, которые будучи примененными к тройкам, позволят описать:
• сложные структуры с подсистемами ввода-вывода, хост-компьютером или какими-то другими особенностями;
• возможные режимы функционирования вычислительных систем, поддерживаемые для оптимального соответствия структуре программ.
Первая операция (х) отражает конвейерный принцип обработки и предполагает последовательное прохождение данных сначала через первый ее аргумент-подсистему, а затем
через второй. Описание упомянутого выше компьютера CDC 6600 можно уточнить следующим образом:
t(CDC 6600) = (10,1,12) х (1,1x10,64),
где первый аргумент отражает существование десяти 12-ти разрядных периферийных процессоров и тот факт, что любая программа должна сначала быть обработана одним из них и лишь после этого передана центральному процессору для исполнения. Аналогично можно получить описание машины РЕРЕ, принимая во внимание, что в качестве хост-компьютера она использует CDC 7600:
t(РЕРЕ) = t(CDC 7600) х (1x3, 288, 32) = = (15, 1, 12) х (1, 1x9, 60) х (1x3, 288,
32)
Поток данных последовательно проходит через три подсистемы, что мы и отразили, соединив их знаком У. Все подсистемы последнего примера достаточно сложны и исходя только из данного описания могут представляться по-разному. Чтобы внести большую ясность, аналогично операции конвейерного исполнения, Хендлер вводит операцию параллельного исполнения (+), фиксирующую возможность независимого использования процессоров разными задачами:
t(n,d,w) = ri(l,d,w) +... + (l,d,w)l {праз}
В случае CDC 7600 уточненная запись вида:
(15, 1, 12) х (1, 1x9, 60) = [(1, 1, 12) +... +(1, 1, 12)]} {15раз} х (1, 1x9, 60)
говорит о том, что каждая задача может захватить сво периферийны процессор, а затем одна за одно они будут поступать в центральны процессор.
Третья операция - операция альтернативы (V), показывает возможные альтернативные режимы функционирования вычислительно системы. Чем больше для системы таких режимов, тем более гибко архитектуро, по мнению Хендлера, она обладает. Например, компьютер C.rnmp может быть запрограммирован для использования в трех принципиально разных режимах:
t(C.rnmp) = (16,1, 16) V (1x16, 1,1 6) V (1, 16, 16).
4. Архитектура параллельных вычислительных систем
Основным параметром классификации параллельных компьютеров является наличие общей (SMP) или распределенной памяти (МРР). Среднее между SMP и МРР представляют собой NUMA -архитектуры, где память физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом МРР. При поддержке команд обработки векторных данных говорят о векторно-конвейерных процессорах, которые, в свою очередь могут объединяться в PVP -системы с использованием общей или распределенной памяти. Все большую популярность приобретают идеи комбинирования различных архитектур в одной системе и построения неоднородных систем.
Массивно-параллельные системы (МРР)
Архитектура
Система состоит из однородных вычислительных узлов, включающих:
• один или несколько центральных процессоров (обычно RISC),
• локальную память (прямой доступ к памяти других узлов невозможен),
• коммуникационный процессор или сетевой адаптер
• иногда - жесткие диски и/или другие устройства В/В
системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т.п.)
Примеры
IBM RS/6000 SP2, Intel PARAGON/ASCI Red, SGI/CRAY T3E, Hitachi SR8000, транспьютерные системы Parsytec.
Масштабируемость
(Масштабируемость представляет собой возможность наращивания числа и мощности процессоров, объемов оперативной и внешней памяти и других ресурсов вычислительной системы. Масштабируемость должна обеспечиваться архитектурой и конструкцией компьютера, а также соответствующими средствами программного обеспечения.)
Общее число процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue Mountain).
Операционная система
Существуют два основных варианта:
• Полноценная ОС работает только на управляющей машине (front-end), на каждом узле работает сильно урезанный вариант ОС, обеспечивающие только работу расположенной в нем ветви параллельного приложения. Пример: Cray ТЗЕ.
• На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая отдельно на каждом узле.
Модель программирования
Программирование в рамках модели передачи сообщений (MPI, PVM, BSPlib)
Симметричные мультипроцессорные системы (SMP)
Архитектура
Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти
либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей.
Примеры
HP 9000 V-class, N-class; SMP-сервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.).
Масштабируемость
Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры.
Операционная система
Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка
Модель программирования
Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания.
Системы с неоднородным доступом к памяти (NUMA)
Архитектура
Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре c-NUMA (cache-coherent NUMA)
Примеры
HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600.
Масштабируемость
Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддержки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000).
Операционная система
Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000).
Модель программирования
Аналогично SMP.
Параллельные векторные системы (РУР) Архитектура
Основным признаком PVP-систем является наличие специальных векторно-
конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично МРР).
Примеры
NEC SX-4/ SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/ T90, CRAY SV1, серия Fujitsu VPP.
Модель программирования
Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
Кластерные системы
Архитектура
Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах.
Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку.
Примеры
NT-кластер в NCSA, Beowulf -кластеры.
Модель программирования
Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач. Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки.
1. В традиционных языках программирования использутся специальные комментарии, добавляющие "параллельну" специфику в изначально последовательные программы. Для простоты рассмотрения можно выбрать циклическую операцию. Итерации некоторого цикла программы независимы и, следовательно, его можно векторизовать, т. е. очень эффективно исполнить с помощью векторных команд на конвейерных функциональных устройствах. Если цикл простой, то компилятор и сам определит, возможность преобразования последовательного кода в параллельный. Если уверенности в высоком интеллекте
компилятора нет, то перед заголовком цикла лучше вставить явное указание на отсутствие зависимости и возможность векторизации. В частности, для языка Fortran это выглядит так:
CDIR$ NODEPCHK
По правилу языка Fortran, буква 'С в первой позиции говорит о том, что вся строка является комментарием, последовательность 'DIR$' указывает на то, что это спецкомментарий для компилятора, а часть 'NODEPCHK' как раз и говорит об отсутствии информационной зависимости между итерациями последующего цикла.
Следует отметить, что использование спецкомментариев не только добавляет возможность параллельного исполнения, но и полностью сохраняет исходный вариант программы. На практике это очень удобно — если компилятор ничего не знает о параллелизме, то все спецкомментарии он просто пропустит, взяв за основу последовательную семантику программы.
На использование комментариев опирается и широко распространенный в настоящее время стандарт ОрепМР. Основная ориентация сделана на работу с общей памятью, нитями (threads) и явным описанием параллелизма. В Fortran признаком спецкомментария ОрепМР является префикс!$ОМР, а в языке С используют директиву "#pragma omp". В настоящее время практически все ведущие производители SMP-компьютеров поддерживают ОрепМР в компиляторах на своих платформах.
Кроме использования комментариев для получения параллельной программы, часто идут на 2. расширение существующих языков программирования. Вводятся дополнительные операторы и новые элементы описания переменных, позволяющие пользователю явно задавать параллельную структуру программы и в некоторых случаях управлять исполнением параллельной программы. Так, язык High Performance Fortran (HPF), помимо традиционных операторов Fortran и системы спецкомментариев, содержит новый оператор FORALL, введенный для описания параллельных циклов программы. Другим примером служит язык трС, разработанный в Институте системного программирования РАН как расширение ANSI С. Основное назначение трС - создание эффективных параллельных программ для неоднородных вычислительных систем.
3. Для более точного отображения специфики архитектуры параллельных систем, либо свойств какого-то класса задач некоторой предметной области используют специальные языки параллельного программирования. Для программирования транспьютерных систем был создан язык Occam, для программирования потоковых машин был спроектирован язык однократного присваивания Sisal. Очень интересной и оригинальной разработкой является декларативный язык НОРМА, созданный под руководством И. Б. Задыхайло для описания решения вычислительных задач сеточными методами.. Высокий уровень абстракции языка позволяет описывать задачи в нотации, близкой к исходной постановке проблемы математиком, что условно авторы языка называют программированием без программиста. Язык не содержит традиционных конструкций языков программирования, фиксирующих порядок вычисления и тем самым скрывающих естественный параллелизм алгоритма.
4. С появлением массивно-параллельных компьютеров широкое распространение получили библиотеки и интерфейсы, поддерживающие взаимодействие параллельных процессов. Типичным представителем данного направления является интерфейс Message Passing Interface (MPI), реализация
которого есть практически на каждой параллельной платформе, начиная от векторно-конвейерных супер-ЭВМ до кластеров и сетей персональных компьютеров. Программист сам явно определяет какие параллельные процессы приложения в каком месте программы и с какими процессами должны либо обмениваться данными, либо синхронизировать свою работу. Обычно адресные пространства параллельных процессов различны. В частности, такой идеологии следуют MPI и PVM. В других технологиях, например Shmem, допускается использование как локальных (private) переменных, так и общих (shared) переменных, доступных всем процессам приложения.
Также существует специализированная система Linda, добавляющая в любой последовательный язык лишь четыре дополнительные функции in, out, read и eval, что и позволяет создавать параллельные программы. сожалению, простота заложенной идеи оборачивается большими проблемами в реализации, что делает данную красивую технологию скорее объектом академического интереса, чем практическим инструментом.
Часто на практике прикладные программисты вообще не используют никаких явных параллельных конструкций, 5. обращение в критических по времени счета фрагментах к подпрограммам и функциям параллельных предметных библиотек. Весь параллелизм и вся оптимизация спрятаны в вызовах, а пользователю остается лишь написать внешнюю часть своей программы и грамотно воспользоваться стандартными блоками. Примерами подобных библиотек являются Lapack, ScaLapack, Cray Scientific Library, HP Mathematical Library, PETSc и многие другие.
Также часто параллелизм подразумевает 6. использование специализированных пакетов и программных комплексов. Как правило, в этом случае пользователю вообще не приходится программировать. Основная задача — это правильно указать все необходимые входные данные и правильно воспользоваться функциональностью пакета. Так, многие используют химики для выполнения квантово-химических расчетов на параллельных компьютерах пользуются пакетом GAMES S, не задумываясь о том, каким образом реализована параллельная обработка данных в самом пакете.
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 550; Нарушение авторских прав?; Мы поможем в написании вашей работы!