КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лексический анализ
|
|
|
|
Лексический анализ образует первый этап процесса компиляции. На этом этапе символы, составляющие исходную программу, считываются и группируются в отдельные лексические элементы, называемые лексемами. Лексический анализ важен для процесса компиляции по нескольким причинам. Наибольшее значение имеет, по-видимому, то, что замена в программе идентификаторов и констант лексемами делает представление программы удобнее для дальнейшей обработки. Далее, лексический анализ уменьшает длину программы, устраняя из исходного ее представления несущественные пробелы и комментарии. На следующих стадиях компиляции компилятор может несколько раз просматривать внутреннее представление программы. Поэтому, уменьшая с помощью лексического анализа длину этого представления, можно сократить общее время процесса компиляции.
Во многих ситуациях выбор конструкций, которые будут выделяться как лексемы, довольно произволен. Например, если в языке разрешены комплексные константы вида
<комплексная константа> 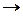 (< вещественное>,<вещественное>)
(< вещественное>,<вещественное>)
то возможны две стратегии. Можно трактовать <вещественное> как лексический элемент и отложить распознавание конструкции <вещественное>,<вещественное> как комплексной константы до фазы синтаксического анализа. Другая стратегия состоит в том, чтобы с помощью более сложного лексического анализатора распознать эту конструкцию как комплексную константу на лексическом уровне и передать тип лексемы синтаксическому анализатору. Важно также отметить, что если в вычислительном центре изменяется принятое в нем множество терминальных символов, то это отражается лишь на лексическом анализе.
Большую часть того, что происходит в течение лексического анализа, можно моделировать с помощью конечных преобразователей работающих последовательно или параллельно. Например, лексический анализатор может состоять из ряда последовательно соединенных конечных преобразователей. Первый преобразователь в этой цепи может устранять из исходной программу все несущественные пробелы, второй ликвидирует комментарии, третий ищет константы и т. д. Другая возможность — завести набор конечных преобразователей, каждый из которых ищет определенную лексическую конструкцию.
В этом разделе мы рассмотрим методы, которые можно использовать при построении эффективных лексических анализаторов. Лексические анализаторы бывают по существу двух видов – прямые и непрямые. Мы покажем, как по регулярным выражениям, описывающий соответствующие лексемы, строятся анализаторы обоих видов.
Определим два крайних подхода к лексическому анализу. Большинство известных способов основано на том или другом из этих подходов, а некоторые на их комбинации:
1. Говорят, что лексический анализатор работает прямо, если для данного входного текста (цепочки) и положения указателя в этом тексте анализатор определяет лексему, расположенную непосредственно справа от указываемого места, и сдвигает указатель вправо от части текста, образующей эту лексему.
2. Говорят, что лексический анализатор работает не прямо, если для данного текста, положения указателя в этом тексте и типа лексемы он определяет, образуют ли знаки, расположенные непосредственно справа от указателя, лексему этого типа. Если да, то указатель передвигается вправо от части текста, образующей эту лексему.
Вообще мы будем описывать алгоритмы синтаксического анализа в предположении, что лексический анализ прямой. В случае непрямого лексического анализа можно использовать «недетерминированные» алгоритмы или алгоритмы с возвратами.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 416; Нарушение авторских прав?; Мы поможем в написании вашей работы!