КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Тема 6. Обобщенный метод наименьших квадратов. Теорема Айткена. Фиктивные переменные. Построение регрессионных моделей по неоднородным данным. Тест Чоу
|
|
|
|
При эконометрическом моделировании реальных экономических процессов предпосылки КЛММР нередко оказываются нарушенными: дисперсии остатков модели не одинаковы (гетероскедастичность остатков), или наблюдается корреляция между остатками в разные моменты времени (автокоррелированные остатки). Тогда предпосылка 3 запишется следующим образом:
3. М(εεТ)=Ω, где Ω – положительно определенная матрица.
Принимая, что дисперсии объясняющих переменных могут быть произвольными, мы получаем обобщенную линейную модель множественной регрессии (ОЛММР).
В этом случае оценка параметров модели методом наименьших квадратов даст неэффективную оценку, поэтому следует применять обобщенный метод наименьших квадратов (ОМНК).
Теорема Айткена. В классе линейных несмещенных оценок вектора β для обобщенной регрессионной модели оценка b* =(XТΩ-1X)-1XТΩ-1Y имеет наименьшую ковариационную матрицу.
Если модель гетероскедастична, то матрица Ω – диагональная. Тогда имеем:
b* =(XТΩX)-1XТΩY.
В этом случае обобщенный метод наименьших квадратов называется взвешенным методом наименьших квадратов, поскольку мы «взвешиваем» каждое наблюдение с помощью коэффициента 1/σi.
На практике, однако, значения σi почти никогда не бывают известны. Поэтому сначала находят оценку вектора параметров обычным методом наименьших квадратов. Затем находят регрессию квадратов остатков на квадратичные функции объясняющих переменных, т.е. уравнение
е2i =f(xi) + ui, i = 1, …, n,
где f(xi) – квадратичная функция.
Далее по полученному уравнению рассчитывают теоретические значения 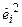 и определяют набор весов
и определяют набор весов 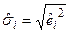 . Затем вводят новые переменные Y*i = Y/σi, X*ji = Xji/σi, (j = 1,…, m; i = 1,…, n) и находят уравнение
. Затем вводят новые переменные Y*i = Y/σi, X*ji = Xji/σi, (j = 1,…, m; i = 1,…, n) и находят уравнение 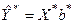 . Полученная оценка и есть оценка взвешенного метода наименьших квадратов.
. Полученная оценка и есть оценка взвешенного метода наименьших квадратов.
При изучении социально-экономических процессов и явлений может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровня, например, образование, пол, фактор сезонности. Качественные признаки могут существенно влиять на структуру линейных связей между переменными и приводить к скачкообразному изменению параметров регрессионной модели. В этом случае говорят об исследовании регрессионных моделей с переменной структурой или построении регрессионных моделей по неоднородным данным.
Оценить влияние значений количественных переменных и уровней качественных признаков с помощью одного уравнения регрессии можно путем введения фиктивных переменных.
В качестве фиктивных переменных обычно используются дихотомические (бинарные) переменные, которые принимают всего два значения: «0» и «1». Например, при исследовании зависимости заработной платы от уровня образования Z можно рассмотреть k=3 уровня: начальное образование, среднее и высшее. Обычно вводят (k-1) бинарную переменную. В нашем случае потребуется ввести две фиктивные переменные.
Тогда регрессионная модель запишется в виде:
y= b0 + b1∙x1 + … + bm∙xm + bm+1∙z1 + bm+2∙z2 +ε,
где 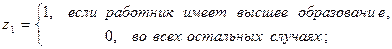
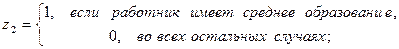
x1, …,∙ xm – экономические (количественные) переменные.
Наличие у работника начального образования будет отражено парой значений z1=0, z2=0.
Параметры при фиктивных переменных z1 и z2 представляют собой разность между средним уровнем результативного признака для соответствующей группы и базовой группы (в нашем примере это работники с начальным образованием).
При построении регрессионных моделей по неоднородным данным необходимо выяснить, действительно ли две выборки однородны в регрессионном смысле, можно ли объединить их в одну и рассматривать единую модель регрессии?
Для ответа на этот вопрос можно воспользоваться тестом Г.Чоу.
По каждой выборке строятся две линейные регрессионные модели:
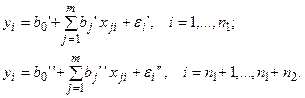
Проверяемая нулевая гипотеза имеет вид – H0: b ' =b ''; D(ε ' )= D(ε '' )= σ2.
Если нулевая гипотеза верна, то две регрессионные модели можно объединить в одну объема n = n1 + n2.
Согласно критерию Г.Чоу нулевая гипотеза H0 отвергается на уровне значимости α, если статистика
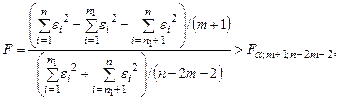
где 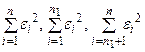 - остаточные суммы квадратов соответственно для объединенной, первой и второй выборок, n = n1 + n2.
- остаточные суммы квадратов соответственно для объединенной, первой и второй выборок, n = n1 + n2.
Для проверки гипотезы о структурной стабильности тенденции изучаемого временного ряда можно также использовать тест Д.Гуйарати.
Пример 4. Рассмотрим полученную в примере 1 модель зависимости балансовой прибыли предприятия торговли 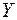 (тыс. руб.) от следующих переменных:
(тыс. руб.) от следующих переменных:
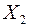 - фонд оплаты труда, тыс. руб.;
- фонд оплаты труда, тыс. руб.; 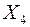 - объем продаж по безналичному расчету, тыс. руб.
- объем продаж по безналичному расчету, тыс. руб.
Известно, что первая выборка значений переменных объемом n1 =12 получена при одних условиях, а другая, объемом n2 =12, - при несколько измененных условиях.
Задание: Проверьте, адекватно ли предположение об однородности исходных данных в регрессионном смысле. Можно ли объединить две выборки в одну и рассматривать единую модель регрессии по 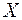 ?
?
Решение.
Для проверки предположения об однородности исходных данных в регрессионном смысле применим тест Чоу.
В соответствии со схемой теста построим уравнения регрессии по первым n1 =12 наблюдениям. Результаты представлены в таблице 8.
Таблица 8
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 1,02E+09 | 5,1E+08 | 11,9033 | 0,002967 | |
| Остаток | ESS1 = = 3,85E+08 | 4,3Е+07 | |||
| Итого | 1,40E+09 |
Результаты дисперсионного анализа модели, построенной по оставшимся n2 =12 наблюдениям, представлены в таблице 9.
Таблица 9
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 1,87Е+09 | 9,33E+08 | 57,1758 | 7,6549E-06 | |
| Остаток | ESS2 = = 1,47E+08 | 1,63Е+07 | |||
| Итого | 2,01E+09 |
Результаты регрессионного и дисперсионного анализа модели, построенной по всем n = n1 + n2 = 24 наблюдениям, представлены в таблице 3 (ESS = 6,39Е+08):
Рассчитаем статистику F по формуле:
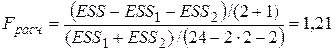 .
.
Находим табличное значение Fтабл = FРАСПОБР(0,05;3;18) = 3,15.
Так как, Fрасч < Fтабл, то справедлива гипотеза 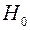 , т.е. надо использовать единую модель по всем наблюдениям. ¨
, т.е. надо использовать единую модель по всем наблюдениям. ¨
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1418; Нарушение авторских прав?; Мы поможем в написании вашей работы!