КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Границы энтропии для кода Хаффмена
|
|
|
|
Напомним, что сформулированная ранее теорема Шеннона для канала без помех определяет верхнюю границу степени сжатия для любых кодов через энтропию вектора X. Найдем верхнюю и нижнюю границы степени сжатия для кода Хаффмена.
Пусть R(X) - скорость сжатия, определяемая как отношение
R = k/n, (2.7)
измеряемая в битах (числе двоичных символов) на букву и получаемая при кодировании вектора данных X с использованием кода Хаффмена. Необходимо найти границы для R(X), выраженные через энтропию вектора X.
Пусть X - вектор данных длиной n и (F1, F2,..., Fk) - вектор частот символов в X. Энтропия H(X) определяется как
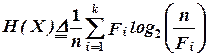 . (2.8)
. (2.8)
Попытаемся связать энтропию H(X) со степенью (скоростью) сжатия R(X) следующим образом:
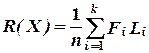 , (2.9)
, (2.9)
где (L1, L2,..., Lk) - точный вектор Крафта кода Хаффмена для X.
Кривая 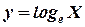 - выпуклая, то есть она всегда располагается ниже любой собственной касательной линии, исключая точку касания. В частности, она находится ниже прямой линии y = x - 1, за исключением x = 1, так как эта прямая линия - касательная к кривой в точке x = 1. Таким образом, можно записать неравенство
- выпуклая, то есть она всегда располагается ниже любой собственной касательной линии, исключая точку касания. В частности, она находится ниже прямой линии y = x - 1, за исключением x = 1, так как эта прямая линия - касательная к кривой в точке x = 1. Таким образом, можно записать неравенство
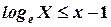 , x > 0, x
, x > 0, x 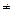 1. (2.10)
1. (2.10)
Подставим 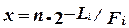 в (2.10) и, умножая обе стороны на Fi/n, получим
в (2.10) и, умножая обе стороны на Fi/n, получим
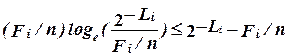 . (2.11)
. (2.11)
Просуммируем обе части неравенства по i. Сумма в правой части будет равна нулю, поскольку и сумма 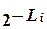 и сумма Fi/n дают единицу.
и сумма Fi/n дают единицу.
Следовательно,
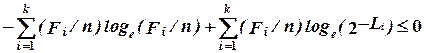 . (2.12)
. (2.12)
Наконец, приведя логарифм по основанию e к основанию 2, получим
H(X) ≤ R(X). (2.13)
Рассмотрим вектор Крафта (L1*, L2*,..., Lk*), в котором длины кодовых слов Li * связаны с частотами символов следующим образом:
Li*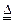 [ - log2 (Fi / n) ]. (2.14)
[ - log2 (Fi / n) ]. (2.14)
Тогда
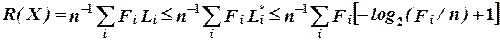 , (2.15)
, (2.15)
где учтено, что [ u ] 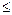 u + 1. Правая часть неравенства - это H(X) + 1.
u + 1. Правая часть неравенства - это H(X) + 1.
И окончательно, объединяя все вышеполученное вместе,
H(X) R(X) H(X) + 1. (2.16)
Недостатки метода Хаффмена
Самой большой сложностью с кодами Хаффмена, как следует из предыдущего обсуждения, является необходимость иметь таблицы вероятностей для каждого типа сжимаемых данных. Это не представляет проблемы, если известно, что сжимается английский или русский текст; мы просто предоставляем кодеру и декодеру подходящее для английского или русского текста кодовое дерево. В общем же случае, когда вероятность символов для входных данных неизвестна, статические коды Хаффмена работают неэффективно.
Решением этой проблемы является статистический анализ кодируемых данных, выполняемый в ходе первого прохода по данным, и составление на его основе кодового дерева. Собственно кодирование при этом выполняется вторым проходом.
Существует, правда, динамическая версия сжатия Хаффмена, которая может строить дерево Хаффмена "на лету" во время чтения и активного сжатия. Дерево постоянно обновляется, чтобы отражать изменения вероятностей входных данных. Однако и она на практике обладает серьезными ограничениями и недостатками и, кроме того, обеспечивает меньшую эффективность сжатия.
Еще один недостаток кодов Хаффмена - это то, что минимальная длина кодового слова для них не может быть меньше единицы, тогда как энтропия сообщения вполне может составлять и 0,1, и 0,01 бит/букву. В этом случае код Хаффмена становится существенно избыточным. Проблема решается применением алгоритма к блокам символов, но тогда усложняется процедура кодирования/декодирования и значительно расширяется кодовое дерево, которое нужно в конечном итоге сохранять вместе с кодом.
Наконец, код Хаффмена обеспечивает среднюю длину кода, совпадающую с энтропией, только в том случае, когда вероятности символов источника являются целыми отрицательными степенями двойки: 1/2 = 0,5; 1/4 = 0,25; 1/8 = 0,125; 1/16 = 0,0625 и т.д. На практике же такая ситуация встречается очень редко или может быть создана блокированием символов со всеми вытекающими отсюда последствиями.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 614; Нарушение авторских прав?; Мы поможем в написании вашей работы!