КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Код с проверкой на четность
Самым простым линейным блочным кодом является (n,n-1)-код, построенный с помощью одной общей проверки на четность. Например, кодовое слово (4,3)-кода можно записать в виде вектора-столбца:
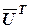 = (m0, m1, m2, m0+m1+m2), (3.1)
= (m0, m1, m2, m0+m1+m2), (3.1)
где mi - символы информационной последовательности, принимающие значения 0 и 1, а суммирование производится по модулю 2 (mod2).
Поясним основную идею проверки на четность.
Пусть информационная последовательность источника имеет вид
m = (1 0 1). (3.2)
Тогда соответствующая ей кодовая последовательность будет выглядеть следующим образом:
U = (U0, U1, U2, U3) = (1 0 1 0), (3.3)
где проверочный символ U3 формируется путем суммирования по mod2 символов информационной последовательности m:
U3 = m0 + m1 + m2 . (3.4)
Нетрудно заметить, что если число единиц в последовательности m четно, то результатом суммирования будет 0, если нечетно — 1, то есть проверочный символ дополняет кодовую последовательность таким образом, чтобы количество единиц в ней было четным.
При передаче по каналам связи в принятой последовательности возможно появление ошибок, то есть символы принятой последовательности могут отличаться от соответствующих символов переданной кодовой последовательности (нуль переходит в единицу, а 1 − в 0).
Если ошибки в символах имеют одинаковую вероятность и независимы, то вероятность того, что в n -позиционном коде произойдет только одна ошибка, составит
P1 = n× Pош × (1- Pош)n-1 (3.5)
(то есть в одном бите ошибка есть, а во всех остальных n - 1 битах ошибки нет).
Вероятность того, что произойдет две ошибки, определяется уже числом возможных сочетаний ошибок по две (в двух произвольных битах ошибка есть, а во всех остальных n - 2 битах ошибки нет):
P2 = Cn2 × Pош × (1- Pош)n-2 , (3.6)
и аналогично для ошибок более высокой кратности.
Если считать, что вероятность ошибки на символ принятой последовательности Pош достаточно мала (Pош<<1), а в противном случае передача информации не имеет смысла, то вероятность выпадения ровно l ошибок составит Pl @ Pошl.
Отсюда видно, что наиболее вероятными являются одиночные ошибки, менее вероятными — двойные, еще меньшую вероятность будут иметь трехкратные ошибки и т. д.
Если при передаче рассматриваемого (4,3)-кода произошла одна ошибка, причем неважно, в какой его позиции, то общее число единиц в принятой последовательности r уже не будет четным.
Таким образом, признаком отсутствия ошибки в принятой последовательности может служить четность числа единиц. Поэтому такие коды и называются кодами с проверкой на четность.
Правда, если в принятой последовательности r произошло две ошибки, то общее число единиц в ней снова станет четным и ошибка обнаружена не будет. Однако вероятность двойной ошибки значительно меньше вероятности одиночной, поэтому наиболее вероятные одиночные ошибки таким кодом обнаруживаться все же будут.
На основании общей идеи проверки на четность и проверочного уравнения (1.4) легко организовать схему кодирования - декодирования для произвольного кода с простой проверкой на четность.
Схема кодирования может выглядеть следующим образом (рис. 3.2):
 |
Рис. 3.2
Декодирующее устройство для кода с проверкой на четность изображено на рис. 3.3.
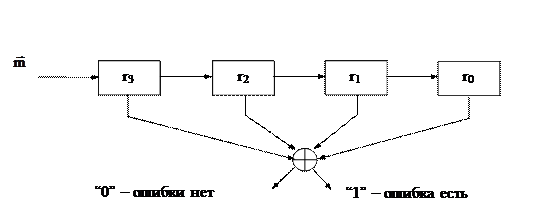
Рис. 3.3
Декодер, как это видно из рис. 3.3, проверяет на четность общее число единиц в принятой последовательности и выдает на своем выходе нуль или единицу в зависимости от того, выполнилась проверка или нет.
Отметим следующий момент. Если посимвольно сложить два кодовых слова, принадлежащих рассматриваемому (4, 3)-коду:
a = (a0, a1, a2, a0 + a1 + a2), и b = (b0, b1, b2, b0 + b1 + b2), (3.7)
то получим
с = (a0+b0, a1+b1, a2+b2, a0+b0+a1+b1+a2+b2) = (c0, c1, c2, c0+c1+c2), (3.8)
то есть проверочный символ в новом слове с определяется по тому же правилу, что и в слагаемых. Поэтому с также является кодовым словом данного кода.
Этот пример отражает важное свойство линейных блочных кодов — замкнутость, означающее, что сумма двух кодовых слов данного кода также является кодовым словом.
Несмотря на свою простоту и не очень высокую эффективность, коды с проверкой на четность широко используются в системах передачи и хранения информации. Они ценятся за невысокую избыточность: достаточно добавить к передаваемой последовательности всего один избыточный символ − и можно узнать, есть ли в принятой последовательности ошибка. Правда, определить место этой ошибки и, следовательно, исправить ее, пока нельзя. Можно лишь повторить передачу слова, в котором была допущена ошибка, и тем самым ее исправить.
|
|
Дата добавления: 2014-01-07; Просмотров: 2057; Нарушение авторских прав?; Мы поможем в написании вашей работы!