КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Синдром и обнаружение ошибок
|
|
|
|
Прежде чем говорить об обнаружении и исправлении ошибок корректирующими кодами, определим само понятие ошибки и методы их описания.
Пусть U = (U0 , U1 ,… Un ) является кодовым словом, переданным по каналу с помехами, а r = (r0 , r1 ,... rn ) - принятой последовательностью, возможно, отличающейся от переданного кодового слова U. Отличие r от U состоит в том, что некоторые символы ri принятой последовательности могут отличаться от соответствующих символов Ui переданного кодового слова. Например, U = (0 0 0 1 0 0 0), а r = (0 0 0 0 0 0 0), то есть произошла ошибка в четвертом символе кодового слова, 1 перешла в 0. Или другой пример: передано кодовое слово U = (0 0 1 1 1 1), а принятая последовательность имеет вид r = (1 0 1 1 1 1 1), то есть ошибка возникла в первом бите кодового слова, при этом 0 перешел в единицу.
Для описания возникающих в канале ошибок используют вектор ошибки, обычно обозначаемый как e и представляющий собой двоичную последовательность длиной n с единицами в тех позициях, в которых произошли ошибки.
Так, вектор ошибки e = (0 0 0 1 0 0 0) означает однократную ошибку в четвертой позиции (четвертом бите), вектор ошибки e = (1 1 0 0 0 0 0) - двойную ошибку в первом и втором битах и т.д.
Тогда при передаче кодового слова U по каналу с ошибками принятая последовательность r будет иметь вид
r = U + e, (3.21)
например: U = (0 0 0 1 0 0 0),
e = (0 0 0 1 0 0 0), (3.22)
r = (0 0 0 0 0 0 0).
Приняв вектор r, декодер сначала должен определить, имеются ли в принятой последовательности ошибки. Если ошибки есть, то он должен выполнить действия по их исправлению.
Чтобы проверить, является ли принятый вектор кодовым словом, декодер вычисляет (n-k)-последовательность, определяемую следующим образом:
S = (S0 , S1 , …, Sn-k-1) = r × H T. (3.23)
При этом r является кодовым словом тогда, и только тогда, когда S=(00..0), и не является кодовым словом данного кода, если S ¹ 0. Следовательно, S используется для обнаружения ошибок, ненулевое значение S служит признаком наличия ошибок в принятой последовательности. Поэтому вектор S называется синдромом принятого вектора r.
Некоторые сочетания ошибок, используя синдром, обнаружить невозможно. Например, если переданное кодовое слово U под влиянием помех превратилось в другое действительное кодовое слово V этого же кода, то синдром S = V * H T = 0. В этом случае декодер ошибки не обнаружит и, естественно, не попытается ее исправить.
Сочетания ошибок такого типа называются необнаруживаемыми. При построении кодов необходимо стремиться к тому, чтобы они обнаруживали наиболее вероятные сочетания ошибок.
Для рассматриваемого в качестве примера линейного блочного систематического (7,4)-кода Хемминга синдром определяется следующим образом:
пусть принят вектор r = (r0 , r1 , r2 , r3 , r4 , r5 , r6), тогда
| 1 0 1 1 1 0 0 | T | |
| S= r* H (7,4)T = (r0, r1, r2, r3, r4, r5, r6) * | 1 1 1 0 0 1 0 | = |
| 0 1 1 1 0 0 1 |
= (r0 + r2 + r3 + r4 ), (r0 + r1 + r2 + r5), (r1 + r2 + r2 + r6 ), (3.23)
или
S0 = r0 + r2 + r3 + r4 ,
S1 = r0 + r1 + r2 + r5 , (3.24)
S2 = r1 + r2 + r2 + r6 .
Основываясь на полученных соотношениях, можно легко организовать схему для вычисления синдрома. Для (7,4)-кода Хемминга она приведена на рис. 3.5.
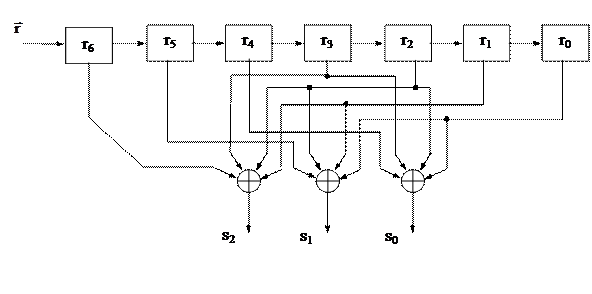
Рис. 3.5
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 3937; Нарушение авторских прав?; Мы поможем в написании вашей работы!