КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритмы поиска по решетке
|
|
|
|
Характеристики сверточных кодов, как и любых других кодов, улучшаются по мере увеличения их размера, в данном случае - кодовой длины блока n. При этом, однако, декодер Витерби становится нереализуемо сложным. Так, при n = 10 он должен помнить уже не менее 210 = 1024 выживших путей.
Для уменьшения сложности декодера максимального правдоподобия при больших n была разработана стратегия, игнорирующая маловероятные пути поиска по решетке, как только они становятся маловероятными. Однако решение о том, чтобы окончательно отбросить данный путь, не принимается. Время от времени декодер возвращается назад и продолжает оставленный путь.
Подобные стратегии поиска наиболее вероятного пути по решетке известны под общим названием последовательного декодирования.
В отличие от оптимальной процедуры Витерби последовательный декодер, просмотрев первый кадр, переходит в очередной узел решетки с наименьшей на данный момент расходимостью. Из этого узла он анализирует следующий кадр, выбирая ребро, ближайшее к данному кадру, и переходит в следующий узел и так далее.
При отсутствии ошибок эта процедура работает очень хорошо, однако при возникновении ошибок на каком-либо шаге декодер может случайно выбрать неправильную ветвь. Если он продолжит следовать по неправильному пути, то очень скоро обнаружит, что происходит слишком много ошибок, и расходимость пути начнет быстро нарастать. Но это будут ошибки декодера, а не канала. Поэтому декодер возвращается на несколько кадров назад и начинает исследовать другие пути, пока не найдет наиболее правдоподобный. Затем он будет следовать вдоль этого нового пути.
Наиболее простым последовательным алгоритмом декодирования является алгоритм Фано. Для его реализации необходимо знать среднюю вероятность появления ошибок в канале связи Pош.
Пока декодер следует по правильному пути, вероятное число ошибок в первых l кадрах (это будет мерой расходимости пути за l кадров) примерно равно
dl = Pош × n0 × l. (4.11)
Если же ошибок становится намного больше, то декодер принимает решение, что он на ложном пути, и возвращается на несколько кадров назад.
Процедура декодирования последовательности r = (01000000..., содержащей ошибку во втором символе, показана на рис.4.9.
Пусть U = (00000000000000000 … и принята последовательность r = (0100000000000 …, то есть возникла ошибка во второй позиции кода. Проследим путь декодера Фано по решетке рис. 4.9.
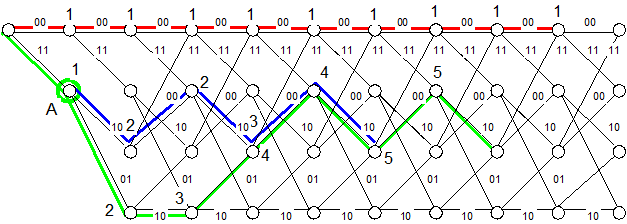 Рис. 4.9
Рис. 4.9
|
Видно, что если на первом шаге выбран верный путь, то расходимость не увеличивается и декодирование выполняется без ошибки. Однако на первом шаге мог быть выбран и неправильный путь (вниз), имеющий такую же метрику. При этом расходимость начинает быстро нарастать, что свидетельствует о неправильном выборе пути. Необходимо вернуться, но на сколько шагов? Предположим, что возвращение произошло в точку А и из нее осуществляется поиск по неисследованному пути. Очень быстро, однако, декодер убедится в неправильности выбора и снова должен вернуться. Но теперь уже не имеет смысла возвращаться в точку А, нужно сделать по крайней мере еще один шаг назад и снова пойти по неисследованному пути. В данном случае это будет правильный путь.
Декодер Фано гораздо проще в реализации, нежели декодер Витерби, и почти не уступает ему в вероятности ошибочного декодирования. Но он обладает и серьезным недостатком. Если вероятность ошибок в канале велика, то возрастает и вероятность принятия неправильных решений при переходе из одного узла решетки в другой, а следовательно, возрастает число возвратов к предыдущим узлам, что требует затрат времени. Входная последовательность при этом во избежание потери данных должна сохраняться в специальном накапливающем регистре. В конечном итоге могут произойти переполнение этого регистра и отказ декодера.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 649; Нарушение авторских прав?; Мы поможем в написании вашей работы!