КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Временная сложность алгоритмов
|
|
|
|
Временная сложность (ВС) – зависимость времени выполнения алгоритма от количества обрабатываемых входных данных. Здесь представляет интерес среднее и худшее время выполнения алгоритма. ВС можно установить с различной точностью. Наиболее точной оценкой является аналитическое выражение для функции: t=t(N), где t – время, N – количество входных данных (размерность). Данная функция называется функцией временной сложности (ФВС).
Например: t = 5N2 + 3*2N + 1. Такая оценка может быть сделана только для конкретной реализации алгоритма и на практике обычно не требуется. Часто бывает достаточно определить лишь порядок функции временной сложности t(N).
Две функции f1(N) и f2(N) — одного порядка, если
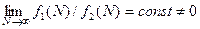
Иначе это записывается в виде: f1(N)= О (f2(N)) (Читается " О большое ").
Примеры определения порядка ВС для некоторых алгоритмов:
1) Алгоритм линейного поиска. Этот алгоритм может быть использован как для упорядоченного, так и для неупорядоченного массива ключей. Работа алгоритма заключается в том, что при просмотре всего массива, начиная с первого и до последнего элемента, ключ из массива сравнивается с искомым ключом. Если результат сравнения положительный – ключ найден. Если же ни одно сравнение не выполнилось с положительным результатом, то ключа в массиве нет.
ФВС для алгоритма линейного поиска: t л. п. = k1 * N = O (N). Действительно, для отыскания ключа в худшем случае придется просмотреть все элементы массива. При этом время проверки каждого элемента одинаково и не зависит от конкретной вычислительной системы.
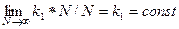
Оценим среднее время алгоритма, при этом будем исходить из следующего: пусть Pi – вероятность того, что будет осуществляться поиск элемента с ключом ki; при этом предположим, что 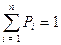 , т.е. ключ со значением ki не будет отсутствовать (в таблице обязательно есть элемент, поиск которого осуществляется). Среднее время (
, т.е. ключ со значением ki не будет отсутствовать (в таблице обязательно есть элемент, поиск которого осуществляется). Среднее время (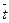 ), как следует из алгоритма, пропорционально среднему числу операций сравнения (
), как следует из алгоритма, пропорционально среднему числу операций сравнения (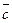 ) и равно ~=
) и равно ~=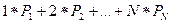 . Если ключи имеют одинаковую вероятность P1=P2=...PN=P, а также учитывая, что
. Если ключи имеют одинаковую вероятность P1=P2=...PN=P, а также учитывая, что , N*P=1, P=1/N, тогда
, N*P=1, P=1/N, тогда 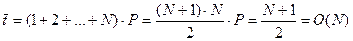 ,
,
т.е. при линейном поиске в среднем необходимо просмотреть половину массива.
Рассмотрим упорядоченную таблицу, у которой элементы упорядочены по частоте обращений (по вероятности). Если имеем такую таблицу, то время – худшее: = О (N).
Распределение осуществляется по закону Зипфа: Pi = c / i, i = 1, 2, …, N, тогда ~=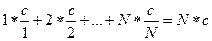 ,
,
причем 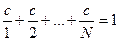 ,
, 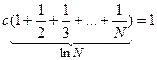 (N ® ¥)
(N ® ¥)
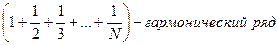 , ln N – постоянная Эйлера.
, ln N – постоянная Эйлера.
Исходя из этого получили: с = 1 / ln N.
2) Алгоритм бинарного (двоичного) поиска. В словесной форме алгоритм двоичного поиска можно записать следующим образом:
1. Определить середину массива.
2. Если ключ, находящийся в середине массива, совпадает с искомым, поиск завершен.
3. Если ключ из середины массива больше искомого, применить двоичный поиск к первой половине массива.
4. Если ключ из середины массива меньше искомого, двоичный поиск необходимо применить ко второй половине массива.
5. Пункт 1-4 повторять, пока размер области поиска не уменьшается до нуля. Если это произойдет, то ключа в массиве нет.
ФВС для алгоритма бинарного поиска: t б. п. = O (log 2 N). Это объясняется тем, что на каждом шаге поиска вдвое уменьшается область поиска. До того, как она станет равной одному элементу, произойдет не более log 2 N таких уменьшений, т.е. выполняется не более log 2 N шагов алгоритма.
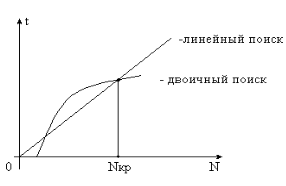
Изобразим графически функции ВС для линейного и двоичного поиска. Из графика видно, что для малых N нужно использовать линейный поиск, а для больших N — двоичный поиск.Nкр находятся в пределах 10.. 1000 в зависимости от характеристик используемого оборудования.
СД типа хеш-таблица.
СД типа хеш-таблица использует алгоритм поиска, основанный на идее хеширования. До сих пор, для поиска требуемой записи мы использовали организацию просмотра некоторого количества ключей. Очевидно, что эффективными алгоритмами поиска являются те, которые проходят это количество ключей при минимальном числе сравнений. В идеале хотелось бы иметь такую организацию таблицы, у которой не было бы ненужных сравнений, т.е. чтобы каждый ключ находился за одно сравнение, но в этом случае положение записи в таблице должно зависеть от значения ключа.
Операция включения элемента в таблицу.
Перед включением элемента в таблицу определяют его адрес с помощью хеш-функции: A = h(K), где K – ключ, а А – адрес элемента таблицы, причем 0 £ А £ N-1, т.е. хеш-функция – отображение множества ключей на множество адресов.
A = K mod N = (C1 * k + C2) mod N, где N – количество адресов в таблице.
“Хорошая” хеш-функция – это функция, которая быстро вычисляется и минимизирует количество коллизий. Коллизия – это ситуация, когда для разных ключей адрес один и тот же, т.е. h(ki) = h(kj), где i ¹ j. Минимизации можно добиться, если равномерно распределить элементы по адресному полю таблицы.
После вычисления адреса элемента таблицы есть две возможности размещения элемента:
1) поместить этот элемент по адресу, если адрес свободен;
2) если вычисленный адрес занят, то повторить хеширование, т.е. совершить рехеширование по следующей формуле: A1 = (A+C) mod N.
Таким образом, алгоритм включения элемента в таблицу будет иметь следующий вид:
1. Вычисление ключа с помощью хеш-функции. Если вычисленный адрес таблицы свободен, то помещаем в него элемент. Конец алгоритма.
2. Если вычисленный адрес таблицы занят, то перевычисляем адрес (проводим рехеширование) и переходим к п.1.
Чтобы процесс размещения элементов был равномерным, адресное поле таблицы делается больше множества ключей на 10-15%.
Операция исключения элемента из таблицы:
1. С помощью хеш-функции вычисляется предполагаемый адрес элемента таблицы.
2. Если по вычисленному адресу располагается искомый ключ, то запись найдена и ее удаляют. Конец алгоритма.
3. Если вычисленный адрес пуст, то элемента с заданным ключом в таблице нет. Конец алгоритма.
4. Если элемент таблицы содержит другой ключ, то перевычисляем (рехешируем) адрес и переходим к п.2.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 2708; Нарушение авторских прав?; Мы поможем в написании вашей работы!