КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Компиляторы. Формальные языки и грамматики
|
|
|
|
Трансляторы, компиляторы и интерпретаторы.
Интерпретатор-программа, которая не выдает результирующей программы.
Целью компилятора является трансляция программы, написанной на языке высокого уровня в машинные коды некоторого компьютера. Большинство ЯВУ построено так, чтобы быть относительно независимыми от тех машин на которых будут использоваться. Это означает что процесс анализа синтаксиса программ написанных на этих языках д.б. также машинно независимым. Но процесс генерации кода является машинно- зависимым поскольку необходимо знать систему команд компьютера для которого этот код генерируется
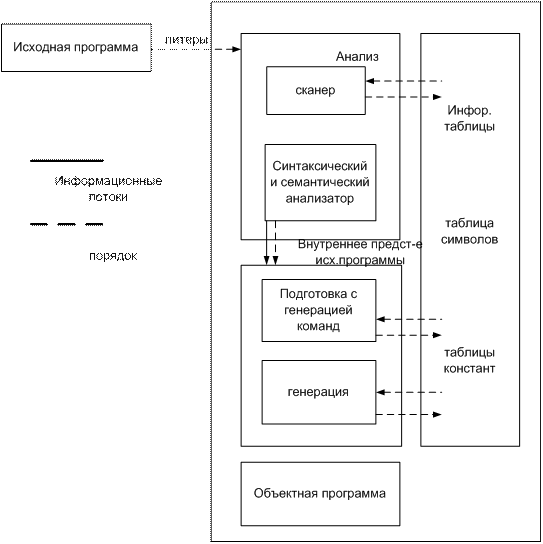
Компилятор должен выполнять анализ исходной программы, а затем синтез объектной программы. Сначала исх. программа разлагается на ее составляющие части. Затем из них строятся ее составные части. Затем из них части эквивалентной объектной программы. Для этого на этапе анализа компилятор строит несколько таблиц, которые затем используются как при анализе, так и при синтезе. Для облегчения построения компиляторов ЯВУ обычно описываются в терминах некоторой грамматики. Эта грамматика определяет форму или синтаксис допустимых предложений может быть сформулирована как проблема поиска соответствия, программистом предложений, строкам, определенным грамматикой и генерацией кода для каждого предложения Наиболее существенная часть для любого процесса компиляции это выделение в исходной программе элементарных составляющих, идентификаторов, ограничителей, операторов, чисел и так далее, которые называются лексемами. Предложения исходной программы удобнее представить в виде последовательности таких лексем. Просмотр исходной программы удобнее представить в виде последовательности таких лексем. Просмотр исходной программы распознавания и классификации различных лексем называются лексическим анализом. Часть компилятора, которая выполняет эту функцию называют лексическим анализатором или сканером. Обычно сканер последовательно читает строки исх. программы разбивает их на лексемы и создает несколько таблиц, используемых на дальнейших этапах.
1) Таблица терминальных символов - таблица каждой строке, которой соответствует информация об одном из терминальных символов. Терминальные символы: арифметические операщии, ключевые слова и так далее
2) Таблица переменных, т.е таблица каждой строке которой сооответвтвует информация о каждой переменной, имеющихся в программе, либо созданных компилятором в процессе выполнения на этапе синтаксического анализа.
3) Таблица констант.
Как только лексемы выделены, каждое предложение программы м.б. распознано как некоторая конструкция языка. Процесс называемый синтаксическим анализом осуществляется той частью компилятора, которая называется синтаксическим анализатором. Здесь лексемы полученные на стадии лексического анализа используется для идентификации более крупных программных структур. Синтаксический анализ обычно чередуется с семантическим. Сначала синтаксический анализатор идентифицирует последовательность лексем, формируя синтаксическую единицу, а затем вызывается синтаксическую единицу, а затем вызывается семантический анализатор. Процесс распознавания предложений исходной программы рассматривают как постр-е дерева грамматического разбора для этих предложений. Последним шагом базов. Схемы процесса трансляции является генерация объектного кода.
Алфавит - это конечное множество символов, которое в дальнейшем будем обозначать V. Предполагается, что термин "символ" имеет достаточно ясный интуитивный смысл и не нуждается в дальнейшем уточнении.
Цепочкой символов в алфавите V называется любая конечная последовательность символов этого алфавита. Далее цепочки символов будем обозначать греческими буквами: , , , …
Цепочка, которая не содержит ни одного символа, называется пустой цепочкой. Для ее обозначения будем использовать символ .
Более формально цепочка символов в алфавите V определяется следующим образом:
(1) - цепочка в алфавите V;
(2) если - цепочка в алфавите V и a - символ этого алфавита, то a - цепочка в алфавите V;
(3) - цепочка в алфавите V тогда и только тогда, когда она является таковой в силу (1) и (2).
Длиной цепочки называется число составляющих ее символов. Например, если = abcdefg, то длина равна 7. Длину цепочки будем обозначать | |. Длина равна 0.
Основной операцией над цепочками символов является операция конкатенации - это дописывание второй цепочки в конец первой, т.е. если и - цепочки, то цепочка называется их конкатенацией. Например, если = ab и = cd, то = abcd. Для любой цепочки всегда = = .
Операция конкатенации не обладает свойством коммутативности, т.е. , но обладает ассоциативностью ()= ().
Обращением ( или реверсом) цепочки называется цепочка, символы которой записаны в обратном порядке. Обращение цепочки будем обозначать R.
Например, если = abcdef, то R = fedcba. Для пустой цепочки: = R.
Для операции обращения справедливо следующее равенство "a,b: (ab)R = bRaR.
N-ой степенью цепочки a (будем обозначать n) называется конкатенация n цепочек . 0 = ; n = n-1 = n-1.
В общем случае язык - это заданный набор символов и правил, устанавливающих способы комбинации этих символов между собой для записи осмысленных текстов. Основой любого естественного или искусственного языка является алфавит, определяющий набор допустимых символов языка.
Язык в алфавите V - это подмножество цепочек конечной длины из множества всех цепочек над алфавитом V. Из этого определения следует два вывода: во-первых, множество цепочек языка не обязано быть конечным; во-вторых, хотя каждая цепочка символов, входящих в язык, обязана иметь конечную длину, эта длина может быть сколь угодно большой и формально ничем не ограничена.
Все существующие языки попадают под это определение. Большинство реальных естественных и искусственных языков содержат бесконечное множество цепочек. Часто цепочку символов, принадлежащую заданному языку, называют предложением языка.
Обозначим через V* множество, содержащее все цепочки в алфавите V, включая пустую цепочку . Например, если V = {0,1}, то V* = {, 0, 1, 00, 11, 01, 10, 000, 001, 011,...}.
Обозначим через V+ множество, содержащее все цепочки в алфавите V, исключая пустую цепочку . Следовательно, верно равенство V* = V+ {}.
Известно несколько различных способов описания языков:
1. Перечислением всех допустимых цепочек языка.
2. Указанием способа порождения цепочек языка (заданием грамматики языка).
3. Определением метода распознавания языка.
Первый из методов является чисто формальным и на практике не применяется, т.к. большинство языков содержат бесконечное число допустимых цепочек и перечислить их просто невозможно.
Второй способ предусматривает некоторое описание правил, с помощью которых строятся цепочки языка. Тогда любая цепочка, построенная с помощью этих правил из символов алфавита языка, будет принадлежать заданному языку.
Более всего интересующий нас третий способ предусматривает построение некоторого логического устройства (распознавателя) - автомата, который на входе получает цепочку символов, а на выходе выдает ответ: принадлежит или нет эта цепочка заданному языку. Например, читая этот текст, вы сейчас в некотором роде выступаете в роли распознавателя (надеемся, что ответ о принадлежности текста русскому языку будет положительным).
Синтаксис языка - это набор правил, определяющий допустимые конструкции языка. Синтаксис определяет «форму языка» - задает набор цепочек символов, которые принадлежат языку. Чаще всего синтаксис языка можно задать в виде строгого набора правил, но полностью это утверждение справедливо только для чисто формальных языков.
Например, строка «3+2» является арифметическим выражением, «3 2 +» - не является.
Семантика языка - это раздел языка, определяющий значение предложений языка. Семантика определяет «содержание языка» - задает значение для всех допустимых цепочек языка.
Например, используя семантику алгебры мы можем сказать, что строка «3+2» есть сумма чисел 3 и 2, а также то, что «3+2 = 5» - это истинное выражение.
Лексика - это совокупность слов (словарный запас) языка. Слово или лексическая единица (лексема) языка - это конструкция, которая состоит из элементов алфавита языка и не содержит в себе других конструкций.
Грамматика - это описание способа построения предложений некоторого языка. Иными словами, грамматика - это математическая система, определяющая язык.
Формально порождающая грамматика G - это четверка G (VT, VN, P, S), где
VT - множество терминальных символов (терминалов),
VN - множество нетерминальных символов (нетерминалов), не пересекающееся с VT,
P - множество правил (продукций) грамматики вида , где V+, V*,
S - целевой (начальный) символ грамматики, S VN.
Для записи правил вывода с одинаковыми левыми частями
1 2 ... n
будем пользоваться сокращенной записью
1 | 2 |...| n.
Каждое i, i = 1, 2,...,n, будем называть альтернативой правила вывода из цепочки .
Такую форму записи правил грамматики называют формой Бэкуса-Наура. Она предусматривает также, что все нетерминальные символы берутся в <> скобки.
Пример: <число>::= <цифра>|<цифра><число>
<цифра>::= 0|1|2|3|4|5|6|7|8|9
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 675; Нарушение авторских прав?; Мы поможем в написании вашей работы!