КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Компиляторы. Синтаксический анализ. Метод восходящего разбора
|
|
|
|
Компиляторы. Лексический анализ. Таблица сверток и диаграмма состояний.
Для того, чтобы при лексическом разборе быстрее находить правило с подходящей правой частью, фиксируют все возможные свертки в описании грамматики (это определяется только грамматикой и не зависит от вида анализируемой цепочки).
Это можно сделать в виде таблицы, строки которой помечены нетерминальными символами грамматики, столбцы - терминальными. Значение каждого элемента таблицы - это нетерминальный символ, к которому можно свернуть пару "нетерминал-терминал", которыми помечены соответствующие строка и столбец.
Например, для грамматики G = ({a, b, #}, {S, A, B, C}, P, S), такая таблица будет выглядеть следующим образом:
P: S C#
C Ab | Ba
A a | Ca B b | Cb

Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет.
Чаще информацию о возможных свертках представляют в виде диаграммы состояний - неупорядоченного ориентированного помеченного графа, который строится следующим образом:
(1) строят вершины графа, помеченные нетерминалами грамматики (для каждого нетерминала - одну вершину), и еще одну вершину, помеченную символом, отличным от нетерминальных, - H. Эти вершины будем называть состояниями. H - начальное состояние.
(2) соединяем эти состояния дугами по следующим правилам:
a) для каждого правила грамматики вида W t соединяем дугой состояния H и W (от H к W) и помечаем дугу символом t;
б) для каждого правила W Vt соединяем дугой состояния V и W (от V к W) и помечаем дугу символом t.
Диаграмма состояний для грамматики G (см. пример выше):
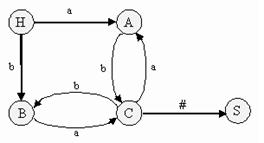
Тогда для диаграммы состояний применим следующий алгоритм разбора:
(1) объявляем текущим состояние H;
(2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: считываем очередной символ исходной цепочки и переходим из текущего состояния в другое состояние по дуге, помеченной этим символом. Состояние, в которое мы при этом попадаем, становится текущим.
При работе этого алгоритма возможны следующие ситуации (аналогичные ситуациям, которые возникают при разборе непосредственно по регулярной грамматике):
(1) прочитана вся цепочка; на каждом шаге находилась единственная дуга, помеченная очередным символом анализируемой цепочки; в результате последнего перехода оказались в состоянии S. Это означает, что исходная цепочка принадлежит L(G).
(2) прочитана вся цепочка; на каждом шаге находилась единственная "нужная" дуга; в результате последнего шага оказались в состоянии, отличном от S. Это означает, что исходная цепочка не принадлежит L(G).
(3) на некотором шаге не нашлось дуги, выходящей из текущего состояния и помеченной очередным анализируемым символом. Это означает, что исходная цепочка не принадлежит L(G).
(4) на некотором шаге работы алгоритма оказалось, что есть несколько дуг, выходящих из текущего состояния, помеченных очередным анализируемым символом, но ведущих в разные состояния. Это говорит о недетерминированности разбора. Анализ этой ситуации будет приведен далее.
Синтаксический анализ – во время синтаксического анализа предложения исходной программы распознаются как языковые конструкции описываемые используемые грамматикой. Можно рассматривать этот процесс как построение дерева грамматического разбора для транслируемых предложений.
Методы грамматического разбора можно разбить на 2 больших класса: восходящие и нисходящие в соответствии с порядком построения дерева грамматического разбора. Нисходящие методы начинают с правила грамматики, определяющие конечную цель анализа с корня дерева грамматического разбора и пытаются так его наращивать чтобы последующие узлы дерева соответствовали синтаксису анализируемого предложения.
Восходящие методы начинают с конечных узлов дерева грамматического разбора и пытаются объединить их построением узлов все более и более высокого уровня, до тех пор, пока не будет достигнут корень дерева. Восходящий метод грамматического разбора называют методом предшествования. Он основан на анализе пар последовательно расположенных операторов исходной программы и решений вопроса о том который из них должен выполняться первым.
При использовании метода грамматического разбора основанного на отношении операторного предшествования, анализируемое предложение рассматривается слева направо до тех пор, пока не будет найдено подвыражение операторы которого имеют более высокий уровень операторного предшествования, чем соседние операторы. Далее это подвыражение распознается в терминах правил перехода, используемой грамматики. Этот процесс продолжается до тех пор, пока не будет достигнут корень дерева, что и будет означать конец грамматического разбора. Первым шагом при разработке процессора грамматического разбора, основанного на методе предшествования д.б установление отношений предшествования между операторами грамматики.
| begin | read | Id | ( | ) | |
| Begin | < | < | |||
| Read | = | ||||
| Id | > | ||||
| ( | < | = | |||
| ) |
Знак = означает что обе лексемы имеют одинаковый уровень предшествования и должна рассматривается грамматическим процессором в качестве одной конструкции языка. Если для пар отношение предшествования не существует это означает что они не могут находиться рядом ни в каком грамматически правильном предложении. Если подобные комбинации лексем встречаются в процессе грамматического разбора то она должна рассматриваться как синтаксическая ошибка. Существуют алгоритмы автономного построения матриц предшествования на основе формального описания грамматики. Для применимости метода операторного предшествования необходимо чтобы отношения предшествования были заданы однозначно.
Процесс сканирования слева направо продолжается на каждом шаге грамматического разбора лишь до тех пор пока не определится очередной фрагмент предложения для грамматического распознавания, т.е. первый фрагмент ограниченный угловыми скобками. Как только подобный фрагмент выделен он интерпретируется как некоторый очередной терминальный символ в соответствии с каким либо правилом грамматики. Этот процесс продолжается до тех пор пока предложение не будет распознано целиком, следует обратить внимание на то что каждый фрагмент дерева грамматического разбора строится начиная с конечных узлов вверх в сторону корня дерева. Для метода операторного предшествования имена нетерминальных символов не существенны т.о. вся информация о грамматике и синтаксических правилах языка содержатся в матрице операторного предшествования.
Другой метод грамматического разбора:
На этапе синтаксического анализа нужно учитывать имеет ли цепочка лексем структуру заданного синтаксисом языка и зафиксировать эту структуру. Следовательно снова надо решать эту задачу разбора. Дана цепочка лексем и надо определить выводима ли она в грамматике определяющей синтаксис языка. Однако структура таких конструкций как выражение, опис-е, оп-р более сложнее чем структура идентификаторов и чисел. Поэтому для описания синтаксисов языков программирования нужны более мощные грамматики чем регулярные. Обычно для этого использует укорачивающие КС грамматики. Грамматики этого класса с одной стороны позволяют доступно полно описать синтаксическую структуру реальных языков программирования, с другой стороны для разных укорачивающих КС грамматик существуют достаточно эффективные алгоритмы разбора.
Существует алгоритм который по любой допустимой КС грамматике и данной цепочке символов выясняет принадлежит ли цепочка языку порождаемому этой грамматикой. Но время работы такого алгоритма экспоненциально зависит от длины цепочки что с практической точки зрения совершенно неприемлемо. Алгоритмы анализа расходующего на обработку входной цепочки линейное время приемлемы только некоторым подклассам КС грамматик.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 966; Нарушение авторских прав?; Мы поможем в написании вашей работы!