КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Последовательные файлы
|
|
|
|
Этап 5.2. Выбор файловой структуры
Цель -Определение наиболее эффективного файлового представления для каждой из таблиц базы данных.
Целью выполнения данного этапа является выбор оптимальной файловой организации для каждой из таблиц. Рекомендации по выбору файловой организации даются исходя из следующих вариантов типов файлов:
• последовательные файлы (heap);
• хешированные файлы (hash);
• индексно-последовательные файлы (ISAM);
• двоичные деревья (В+Тгее).
Структура последовательных файлов обсуждается во втором разделе приложения Б. Последовательный файл, или куча, является наиболее удобной структурой для хранения данных в следующих случаях.
1. Данные загружаются в таблицу крупными блоками. Например, при заполнении вновь созданной таблицы, в нее одновременно может загружаться большое количество данных. Если последовательная организация была выбрана для вновь созданной таблицы как исходный тип файловой организации, то реструктуризация файла таблицы после загрузки основного объема данных может оказать заметное влияние на эффективность ее использования.
2. Весь файл таблицы занимает несколько страниц. В этом случае время поиска любой записи будет невелико, даже при последовательном просмотре всех строк таблицы.
3. При каждом обращении к таблице выборке подлежат все ее кортежи (в любом порядке). Пример — выборка адресов всех сдаваемых в аренду объектов.
4. Таблица имеет дополнительные структуры поиска - например, индекс по ключу. В этом случае использование файлов последовательной организации позволяет достичь экономии дискового пространства.
Файлы последовательной организации неэффективны в случаях, если доступ необходим только к некоторым кортежам таблицы.
Хешированные файлы
Структура хешированных файлов обсуждается в четвертом разделе приложения Б. Применение хёшированного файла в качестве структуры организации памяти для таблицы целесообразно в тех случаях, когда выбор кортежей осуществляется по точному совпадению поля, использованного для хеширования. Например, если выполнить перемешивание таблицы Property_for_Rent по атрибуту Pno, выборка данных по принципу "Значение Pno равно SG37" будет эффективной. Хешированные файлы не рекомендуется использовать в следующих случаях.
1. Выборка кортежей из таблицы осуществляется по шаблонам подстановки, в которые входит и значение поля перемешивания. Например, выборка сведений обо всех сдаваемых в аренду объектах, шифр которых начинается с символов SG.
2. Выборка кортежей из таблицы осуществляется по заданному диапазону значения поля, которое входит в значение поля перемешивания. Например, выборка сведений обо всех сдаваемых в аренду объектах с арендной платой от 300 до 500 фунтов стерлингов.
3. Выборка кортежей из таблицы осуществляется по значению поля, отличного от поля перемешивания. Например, если выполнить перемешивание таблицы Staff по полю Sno, то полученный файл нельзя будет использовать для поиска кортежей по значению атрибута LName. В этом случае для доступа к кортежу потребуется провести линейный поиск, либо создать для поля LMame вторичный индекс (этап 5.3).
4. Доступ к кортежам необходимо выполнять только по части поля перемешивания. Например, если перемешать таблицу Property for Rent по значениям атрибутов Rooms и Rent, то механизм хеширования нельзя будет использовать для поиска кортежей по значению только атрибута Rooms. В этом случае требуемый кортеж может быть найден только в результате выполнения линейного поиска.
Индексно-последовательные файлы
Структура файлов с индексно-последовательной организацией обсуждается в пятом разделе приложения Б. По сравнению с хешированием, метод ISAM представляет собой более гибкую структуру хранения данных. Он поддерживает выборку данных по точному совпадению значения ключа, по шаблону подстановки, по диапазону значений и по части основного ключа. Однако структура индекса ISAM-файла статична и создается в момент создания самого файла. Поэтому производительность доступа к данным ISAM-файла снижается по мере обновления его данных. Обновления также могут вызывать нарушение последовательности ключей ISAM-файла, поэтому выборка данных в порядке ключа все больше и больше замедляется. Две последние проблемы устраняются при использовании файлов, организованных по принципу двоичного дерева. Однако, в отличие от двоичных деревьев, конкурентный доступ к индексу ISAM-файла легко регулируется, поскольку его индекс статичен.
Двоичные деревья
Структура файлов, организованных в виде двоичного дерева (В^Тгее), обсуждается в пятом разделе приложения Б. По сравнению с хешированными файлами, двоичные деревья также представляют собой значительно более гибкие структуры хранения данных. Они позволяют выполнять выборку данных по точному совпадению ключевого значения, по шаблону подстановки, по диапазону значений и по частично заданному ключу. Индекс двоичных деревьев является динамическим, увеличивающимся по мере роста файла таблицы. Благодаря этому эффективность доступа в двоичных деревьях не снижается по мере обновления данных таблицы. Файлы структуры В+Тгее постоянно сохраняют упорядоченность доступа по ключу, даже при обновлении их данных. Поэтому скорость выборки строк в порядке значений ключа здесь выше, чем у ISAM-файлов, и является постоянной. Однако, если информация в таблице не подвергается постоянным изменениям, то использование структуры бинарного дерева может оказаться менее эффективным по сравнению с индексно-последовательными файлами. Дело в том, что ISAM-файлы имеют на один уровень индекса меньше, чем двоичные деревья, где в листовых узлах содержатся не данные, а лишь указатели на них.
документирование результатов выбора структуры файлов таблиц
Результаты выбора файловой структуры для всех таблиц должны быть тщательно зафиксированы в документации. В каждом случае следует указать причины сделанного выбора. В частности, обязательно указывайте причины выбора конкретного варианта, если существовал (один или больше) альтернативный вариант.
Этап 5.3. Определение вторичных индексов
Цель Определение того, будет ли добавление вторичных индексов способствовать повышению производительности системы.
Вторичные индексы представляют собой механизм определения в таблицах базы данных дополнительных ключей, которые предназначены для повышения эффективности выборки данных. Например, файл таблицы Property for Rent может быть перемешан по атрибуту номера сдаваемого в аренду объекта Рпо, в результате чего будет создан первичный индекс этой таблицы. Однако достаточно часто требуется иметь доступ к данным таблицы и по значению атрибута Rent. Поэтому для атрибута Rent следует создать вторичный индекс. Данная задача может быть решена с помощью следующего SQL-оператора:
CREATE INDEX property-rent-index ON property-for-rent(rent);
Однако поддержка актуальности вторичных индексов создает дополнительную нагрузку, поэтому их использование следует тщательно продумывать, стараясь найти приемлемый компромисс между требованиями общей производительности системы и эффективностью выборки данных. Дополнительная нагрузка создается по следующим причинам.
• При вставке в таблицу новой записи необходимо добавление новых записей в каждый ее вторичный индекс.
• При обновлении записи основной таблицы требуется обновление информации во вторичных индексах.
• Для размещения вторичных индексов требуется дополнительное дисковое пространство.
• Возможно некоторое снижение производительности процессов оптимизации запросов, поскольку оптимизатору, для того чтобы найти оптимальное решение, необходимо проанализировать результаты использования всех вторичных индексов.
При определении набора необходимых вторичных индексов предлагаем придерживаться таких рекомендаций.
1. Создавайте вторичный индекс по первичному ключу таблицы, если он не является ключом физической организации ее файла. Хотя в языке SQL2 предусмотрена специальная фраза определения первичных ключей (см. этап 4.1), тем не менее ее указание еще не служит гарантией создания индекса по первичному ключу.
2. Избегайте создания индексов для небольших таблиц. Лучше выполнить линейный поиск в этих таблицах (поместив их целиком в оперативную память), чем хранить на диске дополнительную индексную структуру.
3. Создавайте вторичный индекс для любого атрибута, интенсивно используемого в качестве вторичного ключа. (Например, для таблицы Property for Rent целесообразно создать вторичный индекс по атрибуту Rent, как уже упоминалось выше.)
4. Создавайте вторичный индекс для любого интенсивно используемого внешнего ключа. Например, таблица Property for Rent во многих случаях может соединяться с таблицей Owner, для чего используется атрибут Опо, содержащий идентификатор владельца. Поэтому для повышения эффективности этих Действий. Формально термин денормализация означает внесение в реляционную схему таких усовершенствований, при которых уровень нормализованности обработанных отношений по сравнению с уровнем нормализованности хотя бы одного из исходных отношений уменьшается. Здесь этот термин будет использоваться в несколько более широком понимании — для определения ситуации, когда объединяются два отношения в одно. В результате подобной операции новое отношение может сохранять прежний уровень нормализованности, однако будет содержать больше пустых значений, чем оба исходных отношения. Иногда процедуру денормализации называют оптимизацией использования.
Ссылки на отношения в транзакциях
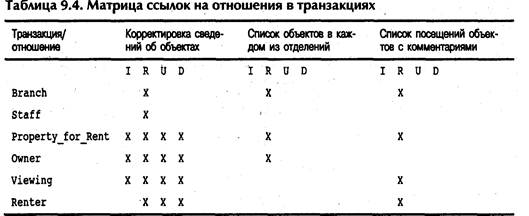
Практика показывает, что денормализация может быть использована как средство улучшения характеристик системы с недостаточной производительностью только в том случае, если уровень обновления данных в этой системе по сравнению с уровнем выполняемых запросов относительно невысок. В этом случае полезной может оказаться матрица ссылок на отношения в транзакциях. В матрице отмечаются все требуемые транзакции и используемые ими отношения. Пример подобной матрицы представлен в табл. 9.4. Матрица визуально обобщает схемы выполнения всех транзакций, которые должны поддерживаться системой. С ее помощью определяются отношения, являющиеся кандидатами на денормализацию, а также оценивается тот эффект, который выполнение денормализации произведет на оставшуюся часть модели данных. Чтобы повысить ценность матрицы, для транзакций следует указывать количество обращений к каждому отношению, осуществляемое за установленный интервал времени (за час, за день, за неделю). Однако в нашем примере мы не показали этой информации —из соображений упрощения вида матрицы.
В этом разделе мы рассмотрим следующие этапы денормализации.
• Этап 5.4.1. Анализ целесообразности использования производных данных.
• Этап 5.4.2. Анализ целесообразности дублирования атрибутов или объединения отношений.
В качестве примера будем использовать материал учебного проекта DreamHome, представленного в табл. 3.3 - 3.8.
Этап 5.4.1. Анализ целесообразности использования производных данных
Атрибуты, значения которых определяются на основании значений других атрибутов, называются производными (или вычисляемыми). Ниже приведено несколько примеров производных атрибутов. Формально термин денормализация означает внесение в реляционную схему таких усовершенствований, при которых уровень нормализованности обработанных отношений по сравнению с уровнем нормализованности хотя бы одного из исходных отношений уменьшается. Здесь этот термин будет использоваться в несколько более широком понимании — для определения ситуации, когда объединяются два отношения в одно. В результате подобной операции новое отношение может сохранять прежний уровень нормализованности, однако будет содержать больше пустых значений, чем оба исходных отношения. Иногда процедуру денормализации называют оптимизацией использования.
Ссылки на отношения в транзакциях
Практика показывает, что денормализация может быть использована как средство улучшения характеристик системы с недостаточной производительностью только в том случае, если уровень обновления данных в этой системе по сравнению с уровнем выполняемых запросов относительно невысок. В этом случае полезной может оказаться матрица ссылок на отношения в транзакциях. В матрице отмечаются все требуемые транзакции и используемые ими отношения. Пример подобной матрицы представлен в табл. 9.4. Матрица визуально обобщает схемы выполнения всех транзакций, которые должны поддерживаться системой. С ее помощью определяются отношения, являющиеся кандидатами на денормализацию, а также оценивается тот эффект, который выполнение денормализации произведет на оставшуюся часть модели данных. Чтобы повысить ценность матрицы, для транзакций следует указывать количество обращений к каждому отношению, осуществляемое за установленный интервал времени (за час, за день, за неделю). Однако в нашем примере мы не показали этой информации —из соображений упрощения вида матрицы.
| Таблица 9.4. Матрица ссылок на отношения в транзакциях | |||||||||||
| Транзакция/ отношение | Корректировка сведе- Список об ний об объектах дом из otj | ьектоев каж-^елений | Список посещений объектов с комментариями | ||||||||
| I | R | U | D | I R | U | D | I | R | U | D | |
| Branch | Х | Х | Х | ||||||||
| Staff | х | ' | |||||||||
| PropertyforRent | х | х | х | х | х | Х | |||||
| Owner | х | х | х | х | х | ||||||
| Viewing | х | х | х | х | Х | ||||||
| Renter | х | х | х | х |
В этом разделе мы рассмотрим следующие этапы денормализации.
• Этап 5.4.1. Анализ целесообразности использования производных данных.
• Этап 5.4.2. Анализ целесообразности дублирования атрибутов или объединения отношений.
В качестве примера будем использовать материал учебного проекта DreamHome, представленного в табл. 3.3 - 3.8.
Этап 5.4.1. Анализ целесообразности использования производных данных
Атрибуты, значения которых определяются на основании значений других атрибутов, называются производными (или вычисляемыми). Ниже приведено несколько примеров производных атрибутов.
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 557; Нарушение авторских прав?; Мы поможем в написании вашей работы!