КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Порядок алгоритма
|
|
|
|
Критерием оценки эффективности алгоритма является его порядок. Порядком алгоритма называется функция O(n), позволяющая оценить зависимость времени выполнения алгоритма от объема обрабатываемых данных (n – количество элементов). Говорят, алгоритм принадлежит классу O(f(n)), где f(n) – некоторая функция от n. Такое обозначение читается как «О большое от f(n)» или менее строго «пропорционально f(n)». Например, алгоритм последовательного поиска принадлежит к классу O(n), а бинарный – к классу O(log(n)). Эффективность тем выше, чем меньше время его выполнения зависит от объема данных.
Поскольку для положительных чисел log(n) < n, можно сделать вывод, что бинарный поиск всегда быстрее последовательного. Предположим, экспериментально определено, что некоторый алгоритм принадлежит к классу O(n2+n). Следовательно, можно подобрать константу k, для которой:
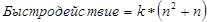
Отсюда видно, что умножение математической функции внутри скобок в О-нотации на константу не оказывает влияния на смысл нотации. Например, O(3*f(n)) эквивалентно O(f(n)), поскольку 3 можно вынести как коэффициент пропорциональности. Кроме того, если величина n достаточно велика при тестировании алгоритма, можно утверждать, что влияние члена «n» поглощается «n2». Поэтому алгоритм O(n2+n) эквивалентен O(n2). То же справедливо и для высших степеней, например, влияние «n2» будет поглощено «n3». В свою очередь, влияние log(n) будет поглощаться членом n.
Предположим, некоторый алгоритм выполняет несколько различных задач. Первая задача принадлежит к классу O(n), вторая – к классу O(n2), третья – к классу O(log(n)). Требуется определить быстродействие алгоритма в целом. Ответом будет O(n2), поскольку к этому классу принадлежит доминантная часть алгоритма.
Таким образом, значения О большого являются репрезентативными только для больших значений n. Для маленьких значений О-нотация не имеет смысла, а на общий результат оказывают влияние другие члены нотации.
Предположим, проводится тестирование двух алгоритмов. Эмпирическим путем выведены следующие зависимости:
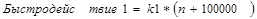
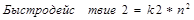
Константы k1 и k2 сравнимы по величине. Если следовать О-нотации, предпочтительнее будет первый алгоритм, поскольку он принадлежит к классу O(n). Однако, если известно, что в реальных условиях n не будет превышать 100, более эффективным окажется второй алгоритм. Следовательно, алгоритм нужно выбирать не только основываясь на O-нотации, но и исходя из условий его применения и статистических данных о времени его выполнения.
O-нотация относится к среднему случаю. Определенные условия выполнения алгоритма и исходных данных позволяют получить лучший и худший случай. Например, при последовательном поиске в массиве данных элемента, расположенного в самом начале, приведет к его обнаружению на первой же итерации цикла. Такая ситуация известна как лучший случай и ее можно представить как O(1) (выполнение алгоритма занимает одно и то же время независимо от количества элементов).
Если бы искомый элемент располагался бы всегда в конце массива, последовательный поиск был бы очень медленным и его порядок равен O(n). Такая ситуация известна как худший случай. Для бинарного алгоритма поиска лучший случай соответствует расположению искомого элемента точно посередине массива. Тем не менее, быстродействие бинарного поиска в худшем случае намного выше, чем для последовательного.
В общем случае при выборе алгоритма следует учитывать значения в О-нотации для среднего и худшего случаев. Лучшие случаи, как правило, не интересны, поскольку обычно обеспокоены граничными условиями, по которым судят о быстродействии.
Большинство алгоритмов с точки зрения порядка сводятся к трем основным типам: степенным O(na), линейным O(n) и логарифмическим O(logan). Эффективность степенных алгоритмов считается плохой, линейных – удовлетворительной, логарифмических – хорошей. Аналитическое определение порядка алгоритма сложно, но в большинстве случаев возможно. В реальных задачах имеются ограничения, определяемые как логикой задачи, так и свойствами конкретной вычислительной среды, которые могут помогать или мешать и существенно влиять на эффективность конкретной реализации алгоритма. Поэтому выбор того или иного алгоритма всегда остается за разработчиком.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1177; Нарушение авторских прав?; Мы поможем в написании вашей работы!