КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Динамическое программирование
|
|
|
|
Метод «Разделяй и властвуй» сводит решение задачи к разделению на несколько простых подзадач и их решению с объединением результатов. Часто не удается разделить задачу на подзадачи, либо в результате разделения получается Nm подзадач с многократным решением одних и тех же подзадач. В результате получается алгоритм с экспоненциальной сложностью.
С точки зрения реализации проще создать таблицу решений всех возможных подзадач. Таблица заполняется лишь однажды, независимо от того, нужна ли какая-либо подзадача для получения общего решения. При повторном обращении к таблице не нужно искать решение подзадач заново.
Метод поиска оптимального решения на основе таблиц, содержащих решения подзадач, называют динамическим программированием (ДП).
Виды алгоритмов ДП могут быть различными. Общей их частью является лишь заполняемая таблица и порядок заполнения ее элементов.
ДП называют процесс пошагового решения задач, где на каждом шаге выбирается единственное решение из множества допустимых, такое, которое оптимизирует заданную целевую функцию.
Здесь процесс решения сводится к пошаговому заполнению таблицы.
Алгоритм ДП вычисляет решения всех подзадач от малых к большим, и ответы запоминаются в таблице. Это не дает сокращения объема задачи, но алгоритм является простым и понятным. Выигрыш по времени достигается лишь за счет исключения повторного решения подзадач.
Алгоритм ДП в худшем случае имеет экспоненциальную сложность для задач со сложностью порядка O(n!).
В теории ДП выделяют 3 аспекта:
1 – теоретический (ДП используется для доказательства теорем существования сходимости и др.);
2 – прикладной (ДП используется для построения модели задач оптимизации);
3 – вычислительный (касается программной реализации).
Основные работы по ДП написаны Беллманом, Венцем и Вагнером.
В основе поиска оптимального решения в алгоритме ДП лежит принцип оптимальности Беллмана:
Оптимальное решение обладает тем свойством, что какими бы ни были начальное состояние и начальное решение, все последующие решения должны быть оптимальной последовательностью решений относительно текущего состояния.
Этот метод дает глобальное оптимальное решение, в отличие от эвристик или «жадного алгоритма». Для ДП решение на каждом шаге должно быть оптимальным с точки зрения процесса в целом.
Класс задач, решаемых алгоритмами ДП, обширен. Задачи различаются как по содержанию, так и по характеру моделей. Наиболее часто ДП используется в экономических задачах оптимизации производства и задачах принятия решений в экспертных системах.
Примеры задач:
1) Задачи оптимального распределения ресурсов.
2) Задачи оптимального управления запасами.
3) Задача реинженеринга (оптимальная стратегия модернизации).
4) Задача оптимального плана производства.
5) Задачи целочисленного линейного программирования.
6) Задачи маршрутизации (сетевые графики, транспортные перевозки).
Пример 1:
Задача коммивояжера.
Исходная задача сводится к набору подзадач. Многошаговый процесс поиска решения (минимизация стоимости тура) сводится к последовательности решений, выбор которых зависит от текущего состояния. Решением каждого шага является город, который нужно посетить следующим.
Целевая функция есть стоимость обхода графа. Применение принципа оптимальности Беллмана к решению этой задачи означает декомпозицию. В начале находится решение всех возможных подзадач, которые используются для отыскания решения более сложных подзадач и т. д. до нахождения решения всей задачи.
Определим параметр T(i; j1, j2, …, jk) как стоимость оптимального маршрута от вершины с индексом i в первую вершину, который проходит каждый город в точности один раз в любом порядке и не проходит через другие города, не принадлежащие подмножеству j. тогда принцип оптимальности приводит к следующей системе рекуррентных соотношений:
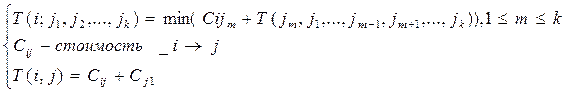
Данная система является рекуррентной, т. к. каждое частное решение рекурсии описывается как покрытие подмножества городов, то возможно 2n подмножеств из n покрытий.
Поэтому верхняя граница сложности 2n ® O(2n), т. е. гораздо лучше, чем алгоритм прямого перебора, сложность которого Oпр(n!).
При n=5 дерево рекурсии выглядит следующим образом:
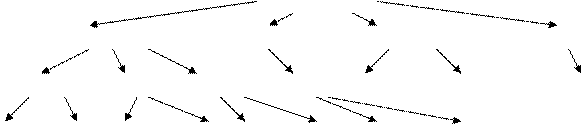 Т(1; 2, 3, 4, 5)
Т(1; 2, 3, 4, 5)
Т(2; 3, 4, 5) Т(3; 2, 4, 5) Т(4; 2, 3, 5) Т(5; 2, 3, 4)
Т(3; 4, 5) Т(4; 3, 5) Т(5; 3, 4) Т(2; 4, 5) Т(2; 3, 5) Т(3; 2, 5) все повторы
Т(4; 5) Т(5; 4) Т(3; 5) Т(5; 3) Т(3; 4) Т(4; 3) Т(4; 5) Т(5; 4)
Здесь заметно дублирование решений в листьях. Однако дублирование может появляться и в узлах при больших n. Чем раньше они появятся, тем лучше. При этом алгоритм «поиска с возвратом» не позволяет исключать дублирующие ветви и листья, в отличие от ДП.
Пример 2:
Вероятность победы в спортивном турнире.
Две команды (А и В) проводят серию игр до N побед любой из команд. Предполагается, что силы команд равны (Р=0,5). Ничья не допускается.
Пусть Р(i, j) – вероятность того, что для победы команде А нужно провести i матчей, а для победы команды В – j матчей.
Составляется рекуррентное соотношение:
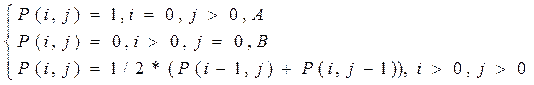
где P(i-1, j) – вероятность выигрыша команды А, если она победит в очередной игре;
P(i, j-1) – вероятность победы А в турнире, если в очередной игре она проиграет.
Для вычисления таблицы вероятностей требуется время £ O(2i+j).
Пусть i+j = n = const.
В этом случае получаем:
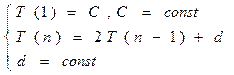
T(n) £ 2n-1*C+(2n-1-1)*d=O(2n) – верхняя граница сложности
i=j ® W(2n/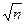 )
)
При этом для вычисления рекурсии нужно находить одно и то же значение P(i,j) несколько раз.
Например, при построении дерева при Р(2, 3) нужно вычислить предварительное значение
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 887; Нарушение авторских прав?; Мы поможем в написании вашей работы!