КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Реализация операций над связными линейными списками
|
|
|
|
Ниже рассматриваются некоторые простые операции над линейными списками. Выполнение операций иллюстрируется в общем случае рисунками со схемами изменения связей и программными примерами.
На всех рисунках сплошными линиями показаны связи, имевшиеся до выполнения и сохранившиеся после выполнения операции. Пунктиром показаны связи, установленные при выполнении операции. Значком 'x' отмечены связи, разорванные при выполнении операции. Во всех операциях чрезвычайно важна последовательность коррекции указателей, которая обеспечивает корректное изменение списка, не затрагивающее другие элементы. При неправильном порядке коррекции легко потерять часть списка. Поэтому на рисунках рядом с устанавливаемыми связями в скобках показаны шаги, на которых эти связи устанавливаются.
В программных примерах подразумеваются определенными следующие типы данных:
* любая структура информационной части списка:
typedef … data;
typedef struct SllNode* link; // указатель в односвязном списке
struct SllNode // - элемент односвязного списка (sill - single linked list):
{
data inf; // информационная часть
link next; // указатель на следующий элемент
};
* элемент двухсвязного списка (dll - double linked list):
typedef … data;
typedef struct DllNode* link; // указатель в двуносвязном списке
struct DllNode // - элемент двусвязного списка
{
data inf; // информационная часть
link next; // указатель на следующий элемент
link prev; // указатель на предыдущий элемент
};
Словесные описания алгоритмов даны в виде комментариев к программным примерам.
В общем случае примеры должны были бы показать реализацию каждой операции для списков: односвязного линейного, односвязного кольцевого, двухсвязного линейного, двухсвязного кольцевого. Объем нашего издания не позволяет привести полный набор примеров, разработку недостающих примеров мы предоставляем читателю.
Перебор элементов списка. Эта операция, возможно, чаще других выполняется над линейными списками. При ее выполнении осуществляется последовательный доступ к элементам списка - ко всем до конца списка или до нахождения искомого элемента.
Алгоритм перебора для односвязного списка представляется программным примером 1.4.
{==== Программный пример 1.4 ====}
// Перебор 1-связного списка
void LookSll(link head) // head - указатель на начало списка
{
link curr = head; // 1-й элемент списка назначается текущим
while(curr)
{ // < обработка c^.inf >
// обрабатывается информационная часть того эл-та, на который
//указывает cur. Обработка может состоять в:
// - печати содержимого инф.части;
// - модификации полей инф.части;
// - сравнении полей инф.части с образцом при поиске по ключу;
// - подсчете итераций цикла при поиске по номеру;
// - и т.д., и т.п.
curr = curr->next;
// из текущего эл-та выбирается указатель на след.
// эл-т и для следующей итерации следующий эл-т становится текущим;
// если текущий эл-т был последний, то его поле next содержит пустой
// указатель и, т. обр. в cur запишется NULL, что приведет к выходу из
// цикла при проверке условия while
}
}
В двухсвязном списке возможен перебор как в прямом направлении (он выглядит точно так же, как и перебор в односвязном списке), так и в обратном. В последнем случае параметром процедуры должен быть tail - указатель на конец списка, и переход к следующему элементу должен осуществляться по указателю назад:
curr = curr->prev;
В кольцевом списке окончание перебора должно происходить не по признаку последнего элемента - такой признак отсутствует, а по достижению элемента, с которого начался перебор. Алгоритмы перебора для двусвязного и кольцевого списка мы оставляем читателю на самостоятельную разработку.
Вставка элемента в список. Вставка элемента в середину односвязного списка показана на рис.1.6 и в примере 1.5.
{==== Программный пример 1.5 ====}
// Вставка элемента в середину 1-связного списка
void InsertSll(link& prev, data inf)
{ // prev - адрес предыдущего эл-та; inf - данные нового эл-та
if(prev) // проверка на корректность указателя на пред. элемент
{ // выделение памяти для нового эл-та и запись в его инф.часть
link curr = new SllNode;
curr->inf = inf;
curr->next = prev->next; // эл-т, следовавший за предыдущим теперь
// будет следовать за новым
prev->next = curr; // новый эл-т следует за предыдущим
}
}
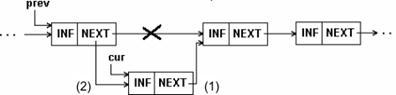
Рис.1.6. Вставка элемента в середину 1-связного списка
На рис 1.7 представлена вставка элемента в двухсвязный список.
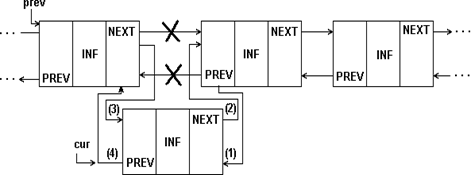
Рис.1.7. Вставка элемента в середину 2-связного списка
Приведенные примеры обеспечивают вставку в середину списка, но не могут быть применены для вставки в начало списка. При последней должен модифицироваться указатель на начало списка, как показано на рис.5.8.
Программный пример 1.6 представляет функцию, выполняющую вставку элемента в любое место односвязного списка.
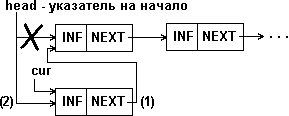
Рис.1.8. Вставка элемента в начало 1-связного списка
{==== Программный пример 1.6 ====}
// Вставка элемента в любое место 1-связного списка
void InsertSll(
link& head, // указатель на начало списка, может измениться в
// функцие, если head=NULL - список пустой
Link& prev, // указатель на эл-т, после к-ого делается, если prev-nil -
// вставка перед 1-м эл-том
data inf) // данные нового эл-та
{ // выделение памяти для нового эл-та и запись в его инф.часть
link curr = new SllNode;
curr->inf = inf;
if(prev) // если есть предыдущий эл-т - вставка в середину
// списка, см. прим.5.2
{
curr->next = prev->next;
prev->next = curr;
}
else // вставка в начало списка
{
curr->next=head;// новый эл-т указывает на бывш. 1-й эл-т списка;
// если head=NULL, то нов. эл-т будет и последним эл-том списка
head = curr; // новый эл-т становится 1-м в списке, указатель на
// начало теперь указывает на него
}
}
Удаление элемента из списка. Удаление элемента из односвязного списка показано на рис.1.9.
Очевидно, что процедуру удаления легко выполнить, если известен адрес элемента, предшествующего удаляемому (prev на рис.1.9,а). Мы, однако, на рис. 1.9 и в примере 1.7 приводим процедуру для случая, когда удаляемый элемент задается своим адресом (del на рис.1.9). Процедура обеспечивает удаление как из середины, так и из начала списка.
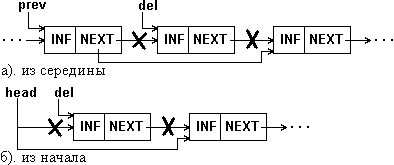
Рис.1.9. Удаление элемента из односвязного списка
{==== Программный пример 1.7 ====}
// Удаление элемента из любого места 1-связного списка
void DeleteSll(link& head, // указатель на начало списка, может
// измениться в функции
link del) // указатель на эл-т, который удаляется
{
if(head == NULL) return; // попытка удаления из пустого списка
if(del == head) // если удаляемый эл-т - 1-й в списке, то следующий за
// ним становится первым
{
head = del->next;
}
else // удаление из середины списка
{ // приходится искать эл-т, предшествующий удаляемому; поиск
// производится перебором списка с самого его начала, пока не будет
// найден эл-т, поле next которого совпадает с адресом удаляемого
// элемента
link prev = head;
while(prev->next && prev->next!= del) prev = prev->next;
if(prev->next == del)
{
prev->next = del->next; // предыдущий эл-т теперь указывает на // следующий за удаляемым
}
}
if(del) delete del; // элемент исключен из списка, теперь можно // освободить занимаемую им память
}
Удаление элемента из двухсвязного списка требует коррекции большего числа указателей, как показано на рис. 1.10.
Процедура удаления элемента из двухсвязного списка окажется даже проще, чем для односвязного, так как в ней не нужен поиск предыдущего элемента, он выбирается по указателю назад.
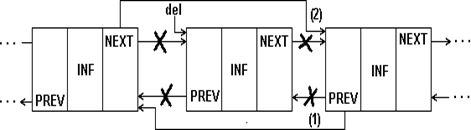
Рис.1.10. Удаление элемента из 2-связного списка
Перестановка элементов списка. Изменчивость динамических структур данных предполагает не только изменения размера структуры, но и изменения связей между элементами. Для связных структур изменение связей не требует пересылки данных в памяти, а только изменения указателей в элементах связной структуры. В качестве примера приведена перестановка двух соседних элементов списка. В алгоритме перестановки в односвязном списке (рис.1.11, пример 1.8) исходили из того, что известен адрес элемента, предшествующего паре, в которой производится перестановка. В приведенном алгоритме также не учитывается случай перестановки первого и второго элементов.
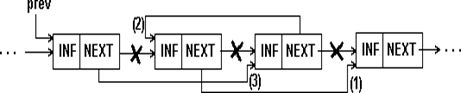
Рис.1.11. Перестановка соседних элементов 1-связного списка
{==== Программный пример 1.8 ====}
// Перестановка двух соседних элементов в 1-связном списке
void ExchangeSll(link& prev) // указатель на эл-т, предшествующий
// переставляемой паре
{
if(prev && prev->next && prev->next->next)
{
link p1 = prev->next; // указатель на 1-й эл-т пары
link p2 = p1->next; // указатель на 2-й эл-т пары
p1->next = p2->next; // 1-й элемент пары теперь указывает на
// следующий за парой
P2->next = p1; // 1-й эл-т пары теперь следует за 2-м
prev->next = p2; // 2-й эл-т пары теперь становится 1-м
}
}
В процедуре перестановки для двухсвязного списка (рис.1.12.) нетрудно учесть и перестановку в начале/конце списка.
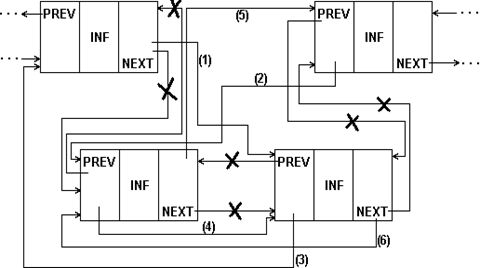
Рис.1.12. Перестановка соседних элементов 2-связного списка
Копирование части списка. При копировании старый список сохраняется в памяти и создается новый список. В информационных полях элементов нового списка содержатся те же данные, что и в элементах старого списка, но поля связок в новом списке совершенно другие, поскольку элементы нового списка расположены по другим адресам в памяти. Существенно, что операция копирования предполагает дублирование данных в памяти. Если после создания копии будут изменены данные в исходном списке, то изменение не будет отражено в копии, и наоборот. Копирование для односвязного списка показано в программном примере 1.9.
{==== Программный пример 1.9 ====}
/* Копирование части 1-связного списка. head - указатель на начало
копируемой части; num - число эл-тов.
Ф-ция возвращает указатель на список-копию */
link CopyList(link head, int num)
{
if(head == NULL) return NULL; // исходный список пуст - копия пуста
link first = NULL, last = NULL;
while(head && num>0) // перебор исходного списка до конца или по счетчику num
{ link curr = new SllNode; // выделение памяти для эл-та выходного
curr->next = NULL; // списка и запись в него информационной
curr->inf = head->inf; // части
if(first == NULL) // если 1-й эл-т выходного списка - запоминается // указатель на начало, иначе - записывается { // указатель в предыдущий элемент
first = curr;
last = first;
}
else
{
last->next = curr;
last = curr; // текущий эл-т становится предыдущим
}
head = head->next; // продвижение по исходному списку
num--; // подсчет эл-тов
}
last->next = NULL; // пустой указатель - в последний эл-т выходного списка
return first;
}
Слияние двух списков. Операция слияния заключается в формировании из двух списков одного - она аналогична операции сцепления строк. В случае односвязного списка, показанном в примере 1.10, слияние выполняется очень просто. Последний элемент первого списка содержит пустой указатель на следующий элемент, этот указатель служит признаком конца списка. Вместо этого пустого указателя в последний элемент первого списка заносится указатель на начало второго списка. Таким образом, второй список становится продолжением первого.
{==== Программный пример 1.10 ====}
/* Слияние двух списков. head1 и head2 - указатели на начала
списков. На результирующий список указывает head1 */
void Unit(link& Head1, link Head2)
{
if(Head2) // если 2-й список пустой – то нечего и делать
{ // если 1-й список пустой, выходным списком будет 2-й
if(Head1 == NULL) Head1 = Head2;
else
{
link curr = Head1; // перебор 1-го списка до последнего его эл-та
while(curr->next) curr = curr->next;
// последний эл-т 1-го списка указывает на начало 2-го
curr->next = Head2;
}
Head2 = NULL; // 2-й список аннулируется
}
}
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 1018; Нарушение авторских прав?; Мы поможем в написании вашей работы!