КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Стандарт MPI
|
|
|
|
ЛЕКЦИЯ 14.
Наиболее распространенной библиотекой параллельного программирования в модели передачи сообщений является MPI (Message Passing Interface). Рекомендуемой бесплатной реализацией MPI является пакет MPICH, разработанный в Аргоннской национальной лаборатории.
MPI является библиотекой функций межпроцессорного обмена сообще-
ниями и содержит около 300 функций, которые делятся на следующие классы:
операции точка-точка, операции коллективного обмена, топологические опера-
ции, системные и вспомогательные операции. Поскольку MPI является стан-
дартизованной библиотекой функций, то написанная с применением MPI про-
грамма без переделок выполняется на различных параллельных ЭВМ. Принци-
пиально для написания подавляющего большинства программ достаточно не-
скольких функций, которые приведены ниже.
Функция MPI_Send является операцией точка-точка и используется для посылки данных в конкретный процесс.
Функция MPI_Recv также является точечной операцией и используется для приема данных от конкретного процесса.
Для рассылки одинаковых данных всем другим процессам используется коллективная операция MPI_BCAST, которую выполняют все процессы, как посылающий, так и принимающие.
Функция коллективного обмена MPI_REDUCE объединяет элементы входного буфера каждого процесса в группе, используя операцию op, и возвращает объединенное значение в выходной буфер процесса с номером root.
MPI_Send(address, сount, datatype, destination, tag, comm),
аddress – адрес посылаемых данных в буфере отправителя
сount – длина сообщения
datatype – тип посылаемых данных
destination – имя процесса-получателя
tag – для вспомогательной информации
comm – имя коммуникатора
MPI_Recv(address, count, datatype, source, tag, comm, status)
address – адрес получаемых данных в буфере получателя
count– длина сообщения
datatype– тип получаемых данных
source – имя посылающего процесса процесса
tag -для вспомогательной информации
comm– имя коммуникатора
status -для вспомогательной информации
MPI_BCAST (address, сount, datatype, root, comm)
root – номер рассылающего (корневого)процесса
MPI_REDUCE(sendbuf, recvbuf, count, datatype, op, root, comm)
sendbuf -адрес посылающего буфера
recvbuf -адрес принимающего буфера
count -количество элементов в посылающем буфере
datatype – тип данных
op -операция редукции
root -номер главного процесса
Кроме этого, используется несколько организующих функций.
MPI_INIT ()
MPI_COMM_SIZE (MPI_COMM_WORLD, numprocs)
MPI_COMM_RANK (MPI_COMM_WORLD, myid)
MPI_FINALIZE ()
Обращение к MPI_INIT присутствует в каждой MPI программе и должно
быть первым MPI – обращением. При этом в каждом выполнении программы
может выполняться только один вызов После выполнения этого оператора все
процессы параллельной программы выполняются параллельно. MPI_INIT.
MPI_COMM_WORLD является начальным (и в большинстве случаев единственным) коммуникатором и определяет коммуникационный контекст и связанную группу процессов.
Обращение MPI_COMM_SIZE возвращает число процессов numprocs, запущенных в этой программе пользователем.
Вызывая MPI_COMM_RANK, каждый процесс определяет свой номер в группе процессов с некоторым именем.
Строка MPI_FINALIZE () должно быть выполнена каждым процессом программы. Вследствие этого никакие MPI – операторы больше выполняться не будут. Перемсенная COM_WORLD определяет перечень процессов, назначенных для выполнения программы.
MPI программа для вычисления числа π на языке С.
Для первой параллельной программы удобна программа вычисления числа π, поскольку в ней нет загрузки данных и легко проверить ответ. Вычисления сводятся к вычислению интеграла по следующей формуле:
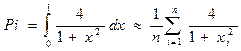
где xi = (i- 1/2 ) / n. Программа:
#include "mpi.h"
#include <math.h>
int main (int argc, char *argv[])
{
int n, myid, numprocs, i; /* число ординат, имя и число процессов*/
double PI25DT = 3.141592653589793238462643; /* используется для оценки
точности вычислений */
double mypi, pi, h, sum, x; /* mypi – частное значение π отдельного процесса, pi –
полное значение π */
MPI_Init(&argc, &argv); /* задаются системой*/
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (1)
{
if (myid == 0) {
printf ("Enter the number of intervals: (0 quits) "); /*ввод числа ординат*/
scanf ("%d", &n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0) /* задание условия выхода из программы */
break;
else {
h = 1.0/ (double) n; /* вычисление частного значения π некоторого процесса */
sum = 0.0;
for (i = myid +1; i <= n; i+= numprocs) {
x = h * ((double)i - 0.5);
sum += (4.0 / (1.0 + x*x));
}
mypi = h * sum; /* вычисление частного значения π некоторого процесса */
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD); /* сборка полного значения π */
if (myid == 0) /* оценка погрешности вычислений */
printf ("pi is approximately %.16f. Error is
%.16f\n", pi, fabs(pi - PI25DT));
}
}
MPI_Finalize(); /* выход из MPI */
return 0;
}
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 691; Нарушение авторских прав?; Мы поможем в написании вашей работы!