КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Синтезаторы с непосредственным
|
|
|
|
Синтезаторы третьего типа используют метод цифрового моделирования голосового тракта человека.
Аналоговые методы синтеза формантных частот.
Выше было дано определение формантной частоты речевого сигнала. Для удовлетворительного распознавания и синтеза речи достаточно использовать 3 из 6-и старших формант. Тем не менее, использование формантных частот даёт
неестественное звучание речи, что объясняется особенностью источника речи. В устройствах этого типа естественная речь человека не используется, так как синтез речи основан на электронном моделировании голосового тракта человека, поэтому синтезатор «говорит» голосом робота. Кратко процесс синтеза заключается в следующем.
Орфографический текст разбивается на фонемы, которые преобразуются в фонетическое описание текста, затем формируются последовательности управляющих слов, которые используются для управления собственно синтезатором.
Отличительной особенностью этого метода является принципиальная возможность создания синтезатора с неограниченным словарём, так как в основу его положена элементарная частица речи – фонема. Возможность неограниченного словаря никакому другому типу синтезаторов недоступна. Это в значительной степени искупает основной недостаток синтезатора – неестественное звучание речи.
Наиболее распространённая реализация этого метода известна под названием Линейного Предиктивного Кодирования (ЛПК), а синтезаторы называют ЛПК - синтезаторами (термин «предиктивный» означает предсказательный).
ЛПК синтезаторы обладают по сравнению с другими типами синтезаторов преимуществами, связанными с относительной простотой их реализации в виде цифровых микросхем, меньшей стоимостью их производства и меньшей эквивалентной скоростью передачи информации. Словарь в ЛПК - синтезаторе создаётся (как и в синтезаторах первой группы) с участием говорящего человека. Закодированная таким образом человеческая речь на этапе синтеза не подвергается прямому восстановлению. Она обрабатывается специальным цифровым анализатором, и в результате такого анализа образуются так называемые предикторные коэффициенты – параметры, которые используются непосредственно для управления собственно синтезатором. Предикторные коэффициенты представляют собой частотные и голосовые коэффициенты речи. Такой подход позволяет значительно снизить объём необходимой памяти.
кодированием/восстановлением человеческой речи.
Синтезаторы этого типа используют компилятивный метод синтеза. Это означает, что в основу построения синтезатора положен принцип работы по образцам. В качестве образца берётся живая человеческая речь, которая предварительно кодируется, то есть преобразуется в цифровую форму и сохраняется в памяти компьютера.
Принцип кодирования речевого сигнала иллюстрирует рис. 9, а.
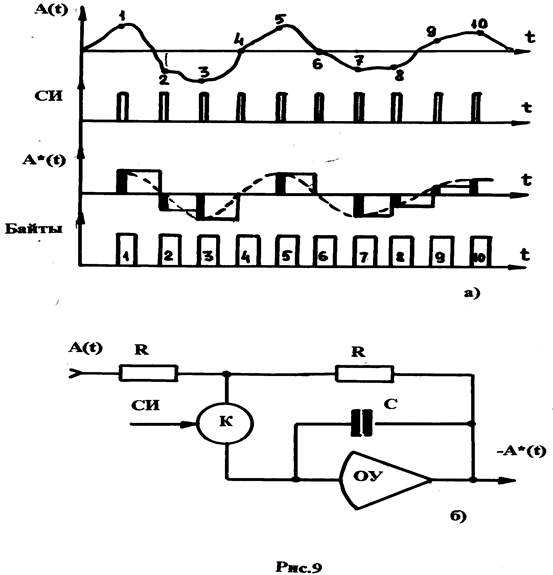
На верхнем рисунке приведён фрагмент речевого сигнала А(t). Этот сигнал с помощью устройства, называемого схемой выборки, квантуется с частотой синхроимпульсов (СИ), и на выходе схемы выборки образуются отдельные значения речевого сигнала А*(t). Амплитуда этих сигналов соответствует величине сигнала А(t) в момент выборки, то есть в момент поступления СИ на схему выборки.
Затем, отдельные выборки произнесённого в микрофон слова или фразы преобразуются в код и записываются в память. Массиву байтов, соответствующих слову (фразе), присваивается идентификатор (имя), по которому на этапе синтеза речи можно обратиться к области памяти, где хранится это слово, (фраза). Как видно на рис. 9, а, десяти выборкам речевого сигнала соответствуют 10 байтов, записанных в память компьютера.
На рисунке 9, б приведена простейшая схема выборки, реализованная на базе операционного усилителя (ОУ) с емкостью в цепи отрицательной обратной связи (С). Когда электронный ключ (К) закрыт ёмкость хранит напряжение, равное величине напряжения А(t) в момент закрытия ключа К. На выходе операционного усилителя (ОУ) при этом образуется напряжение -А*(t) равное А(t) (при равенстве резисторов R). С приходом очередного импульса СИ ключ открывается и ёмкость разряжается до напряжения А(t), действующего на входе. С прекращением импульса СИ ключ К закрывается и ёмкость хранит напряжение, поступившее на вход в момент закрытия ключа (с обратным знаком). Работу схемы выборки описывает временная диаграмма, приведённая на рис. 9, а.
Структура синтезатора приведена на рис. 10.
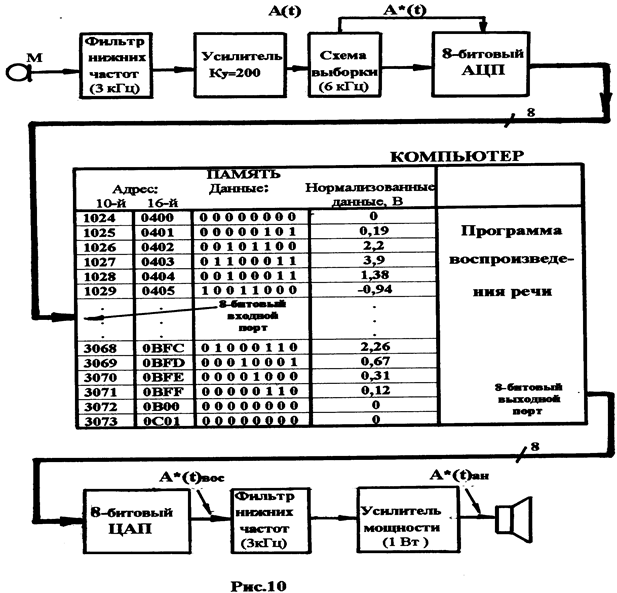
В приведённой структуре можно выделить 3 основных узла:
1. Входной узел синтезатора, состоящий из микрофона (М), фильтра нижних частот (ФНЧ), усилителя (У), схемы выборки и 8-битового АЦП.
2. Компьютер.
3. Выходной узел синтезатора, включающий в себя 8-битный ЦАП, фильтр нижних частот (ФНЧ), усилитель мощности и динамик (Д).
Работа входного узла синтезатора описана выше и не требует особых комментариев. Следует лишь отметить, что фильтр нижних частот, используемый в этом узле, и настроенный на частоту фильтрации сигнала с микрофона (ниже 3 кГц), выполняет задачу подавления высокочастотных помех, приводящих к искажению речевого сигнала А(t). Усилитель (У) доводит амплитуду речевого сигнала до уровня, принятого в синтезаторе.
Схема выборки с частотой 6 кГц производит выборки речевого сигнала A*(t), а аналого-цифровой преобразователь (АЦП) преобразует выборки в цифровые коды (байты). При частоте выборки сигнала 6 кГц среднее количество выборок для слова длительностью 0,3 секунды составляет около 2000 байтов (включая короткие паузы в начале и в конце слова).
Компьютер имеет параллельный 8-битный порт ввода данных с АЦП и параллельный 8-битный порт вывода, откуда данные поступают на вход 8-битного цифро-аналогового преобразователя (ЦАП).
В процессе сбора данных компьютером его резидентная программа переносит информацию из 8-битного АЦП и последовательно записывает её в память.
После произнесения слова процесс выборки заканчивается, а в памяти оказывается записанным цифровое представление слова.
Выходной узел синтезатора представляет воспроизводящую часть синтезатора. Он содержит 8-битный цифро-аналоговый преобразователь, фильтр нижних частот (ФНЧ), который отфильтровывает нежелательные высокочастотные сигналы c выхода ЦАП – A(t)вос, возникающие в восстановленном сигнале. Отфильтрованный сигнал поступает на усилитель мощности, а затем в виде сигнала A*(t)вос на динамик-Д.
Программа воспроизведения речи, хранимая в памяти, – это простая индексирующая программа, которая последовательными шагами просматривает записанную ранее информацию и выводит её побайтно на 8-битный ЦАП.
Речь, которую услышит пользователь по своему звучанию, соответствует голосу говорящего и имеет модуляцию и тональность, как и входной речевой сигнал.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 283; Нарушение авторских прав?; Мы поможем в написании вашей работы!