КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
ЛПК - синтезаторы
|
|
|
|
Линейное предиктивное кодирование (ЛПК - метод) основано на использовании математического аппарата – уравнений преобразования закодированной речи в её спектр исходных частот.
Главный принцип, положенный в основу ЛПК - метода сводится к тому, что поступающие выборки речевых сигналов могут рассматриваться как линейные комбинации прошлых выборок речевого сигнала.
Физически это означает, что характер речевого сигнала сравнительно мало изменяется при произнесении какого-либо одного звука, а изменение характера этого сигнала происходит значительно реже (по отношению к частоте квантования – F кв) при переходе от одного звука к другому. Это отчётливо видно, если речевой сигнал записать на
какой либо носитель, а затем рассмотреть осциллограмму.
Существует большое сходство между ЛПК - методом и методом прямого кодирования-восстановления речевого сигнала. Сходство
заключается в том, что в основе обоих методов используется живая человеческая речь. Но в ЛПК - синтезаторах в память записываются коды слов. Затем на основе этих кодов производится анализ кодированной речи с целью образовать так называемые кадры ЛПК - данных, которые содержат информацию о высоте основного тона, о формантных частотах, об амплитуде и интонации речи и т.п. – всего около 12 параметров речи, которые формируются в кадры, управляющие собственно синтезатором.
На рис. 15 приведена структура модели системы синтеза речи с использованием ЛПК - метода (модель несколько упрощена).
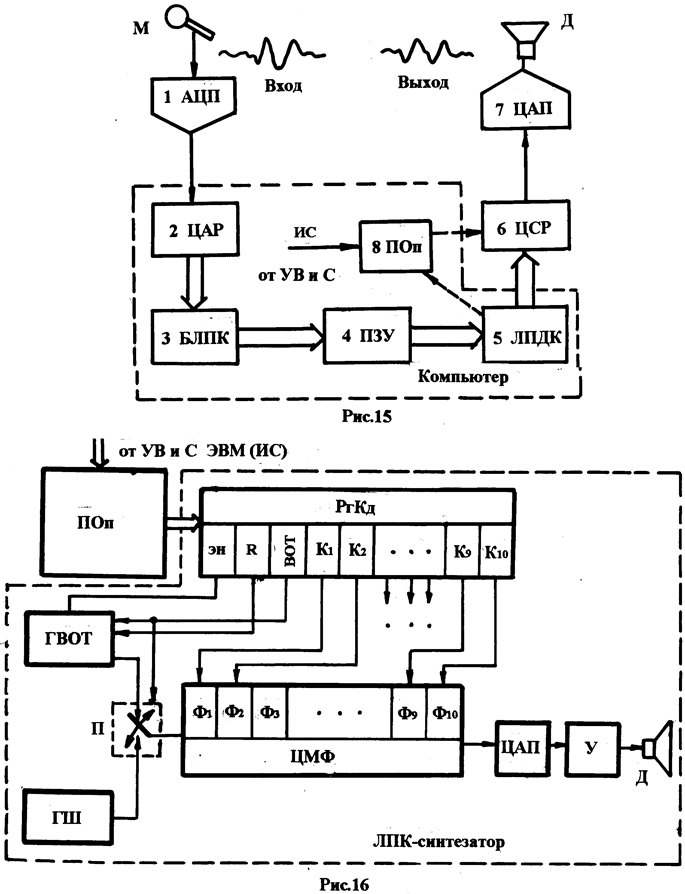
В модель системы входят:
- Микрофон (М) для ввода в модель
речевых фрагментов и слов с помощью живой человеческой речи.
1. Аналого-цифровой преобразователь. 2. Цифровой анализатор речи (ЦАР).
3. Блок образования линейных
предикторных коэффициентов (БЛПК).
4. Постоянное запоминающее устройство.
5. Блок линейного предиктивного
декодирования (ЛПДК).
6. Собственно цифровой синтезатор
речи (ЦСР).
7. Цифроаналоговый
преобразователь (ЦАП).
8. Память описаний (ПОп).
- Громкоговоритель (Д).
Следует заметить, что блоки 2 –5 модели реализуются средствами компьютера и являются его программно-аппаратными частями.
Рассмотрим функции отдельных блоков модели и их взаимодействие.
Цифровой анализатор речи (ЦАР) – программа, которая анализирует выборки речевых сигналов, поступающих с выхода АЦП, и образует данные о спектральном составе речи, формантных характеристиках речи, данные об амплитуде и интонации речи – всего 12 параметров.
Блок образования линейных предикторных коэффициентов (БЛПК) – программный блок вычисления предикторных коэффициентов,
описывающих речевой фрагмент (слово, фразу). Этот блок, по сути, является устройством краткосрочного прогнозирования, то есть своеобразным «предсказателем» последующего речевого сигнала. Выходные данные этого блока управляют параметрами и определяют числовые коэффициенты, которые используются для линейной предиктивной генерации речи.
Постоянное запоминающее устройство (ПЗУ) хранит данные из блока БЛПК. Эти данные в дальнейшем служат для регенерации речи, формируемой системой ЛПК - синтезатора.
После того, как на этапе настройки синтезатора параметры записаны в ПЗУ системы, можно приступать к синтезу речи. Процесс синтеза речи начинается в блоке ЛПКД.
Блок линейного предиктивного декодированияиз данных, записанных в ПЗУ, формирует управляющие кадры, которые подаютсяна блок ЦСР – цифровой синтезатор речи, который принимает управляющие кадры. Каждая ячейка управляющего кадра (УК) представляет собой код – элемент двоичной информации, который передаётся в синтезатор и управляет синтезом речи.
Ячейки управляющего кадра (рис. 16) имеют следующий функциональный смысл:
Ячейка ЭН (энергия) – всегда присутствует в кадре. Её значение – либо 1111, либо 0000. Эта ячейка кадра служит для непрерывного управления амплитудой произносимой речи.
Ячейка R (повторение кадра) – если R=1, то повтора кадра нет, в противном случае кадр повторяется (длинный звук).
Ячейка ВОТ (высота основного тона): при ВОТ=0 – глухой звук, при ВОТ=1 – звонкий звук.
К1 – К10 – (3-5 бит), управляющие биты, задающие предикторные коэффициенты, вычисленные на этапе цифрового анализа речи (ЦАР) и образования предикторных коэффициентов (БЛПК – ПЗУ – ЛПДК).
Система ЛПК - синтеза работает в двух режимах.
РЕЖИМ 1. Режим подготовки системы к генерации речи (рис. 15).
В этом режиме, при использовании реальной человеческой речи в памяти описаний необходимо создать массив управляющих кадров для генерации сегмента речи. В этом случае работают блоки: АЦП, ЦАР, БЛПК, ПЗУ, ЛПДК, ПОп. Оператор через микрофон передаёт в систему речевые сегменты (фразы, слова),
которые оцифровываются и поступают в БЛПК. Этот блок образует линейные предикторные коэффициенты, которые записываются в ПЗУ, а затем передаются в блок линейного предиктивного декодирования (ЛПДК). Блок формирует из этих данных управляющие кадры (УК). Управляющим кадрам, соответствующим одному фрагменту речи, присваивается идентификатор сообщения (ИС). Управляющие кадры со своим идентификатором записываются в память описаний. Аналогичные операции совершаются со всеми речевыми фрагментами, которые вводятся в синтезатор.
РЕЖИМ 2. Этот режим является основным режимом – режимом собственно синтеза речи. Он реализуется следующим образом.
Идентификатор (имя) сообщения из ЭВМ верхнего уровня (центральной ЭВМ) передаётся в узел управления выборкой и синхронизации (УВ и С). Этот узел осуществляет поиск описания выводимого речевого сообщения в памяти описания (ПОп). Описание речевого сообщения представляет собой последовательность управляющих кадров, поступающих в синтезатор каждые 20 мс, в течение которых предикторные коэффициенты остаются постоянными. Структурная схема синтезатора описанного типа приведена на рис. 16.
В структуре использованы следующие обозначения:
ГВОТ – генератор высоты основного тона;
ГШ – генератор шума;
РгКд – регистр управляющего кадра (УК);
Эн – ячейка «энергия» регистра кадра (РгКд);
R – ячейка «повторить кадр регистра кадра (РгКд);
ВОТ – ячейка «высота основного тона регистра кадра (РгКд);
К1 – К10 – ячейки управляющих битов регистра кадра (РгКд);
ПОп – память описаний;
УВиС – устройствоуправление выборкой и синхронизацией
ИС – идентификатор сообщения;
ЦМФ – цифровой многозвенный фильтр;
Ф1 – Ф10 – элементы цифрового многозвенного фильтра;
П – электронный переключатель;
ЦАП – цифро-аналоговый преобразователь;
У – усилитель;
Д – динамик;
Работа синтезатора кратко заключается в следующем.
Синтезатор подготовлен к работе, если в режиме 1 в память описаний введена информация в виде речевых сообщений. Из ЭВМ верхнего уровня в устройство УВиС (на рис. 16 не приведено) поступает идентификатор сообщения (ИС). Устройство УВиС осуществляет в памяти описаний (ПОп) поиск начального кадра из числа кадров, которые управляют синтезатором при выводе сообщения, заданного ЭВМ.
Управляющие сообщения последовательно записываются в регистр кадров и управляют всеми компонентами синтезатора, которые подключены к регистру управляющего кадра. Когда последний управляющий кадр из последовательности кадров реализует свои функции, синтез прекращается.
При формировании речи по образцам (компилятивными методами) количество возможных речевых сообщений ограничено теми сообщениями, описание которых составлены заранее и хранятся непосредственно в памяти описаний или составляются в процессе вывода путём слияния нескольких элементарных сообщений, также хранящихся в памяти.
Составление описаний более сложных сообщений выполняется с использованием программных средств. Например, сообщение «Температура воздуха в Москве в ХХ часов была YY градусов» может быть составлено из 5 элементарных сообщений:
1. Температура воздуха в Москве
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 383; Нарушение авторских прав?; Мы поможем в написании вашей работы!