КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
If OpenDialog1.Execute then 10 страница
|
|
|
|
Активизировав вкладку «Поля» (Margins) (рис. 95), пользователь может установить правый (Right), левый (Left), верхний (Тор) и нижний (Bottom) отступы от края бумаги.
Рис. 95. Окно «Параметры страницы» с активной вкладкой «Поля»
В группе «Центрировать на странице» (Center on page) при установке флажков в позиции «Горизонтально» (Horizontally) и «Вертикально» (Vertically) происходит центрирование при распечатке относительно верхнего и нижнего поля, правого и левого поля.
Вкладка «Колонтитулы» (Header / Footer) (рис. 96) позволяет создать верхний и нижний колонтитулы.
По умолчанию в качестве верхнего колонтитула задается название текущего листа «Лист 1» (Sheet 1), а в качестве нижнего колонтитула – номер текущей страницы «Страница 1» (Page 1). Для создания верхнего колонтитула необходимо выбрать одну из строк в списке «Верхний колонтитул» (Header) и нажать кнопку «Создать верхний колонтитул» (Custom header). Колонтитул будет скопирован в диалоговое окно «Верхний колонтитул» (Header) (см. рис. 96).
В окне расположены семь кнопок редактирования и форматирования и три поля установки колонтитула: «Слева» (Left section), «В центре» (Center section), «Справа» (Right section). Работа с колонтитулами начинается с выбора мышью одного из полей установки. Далее, щелчком мыши активизируется одна из семи кнопок, например, вторая слева, которая задает номер страницы. Затем номер щелчком мыши помещается в правое поле установки. Аналогично, в любом поле может быть задано общее количество страниц (третья кнопка слева), текущая дата (четвертая кнопка слева) и т.д.
Рис. 96. Окно «Параметры страницы» с активной вкладкой «Колонтитулы»
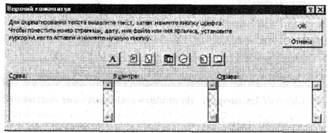
Рис. 97. Окно диалога «Верхний колонтитул»
Активизировав вкладку «Лист» (Sheet), пользователь получает доступ к диалоговому окну (рис. 98). В поле «Выводить на печать диапазон» (Print area) можно внести диапазон ячеек для печати. Для несмежных диапазонов предусмотрена печать на разных страницах.
В процессе печати нередко требуется выводить одни и те же строки или столбцы на каждой странице, использовав их в качестве заголовка. Для установки режима печати одинаковых строк и столбцов применяют поле группы «Печатать на каждой странице» (Print titles):
• для повторения печати строки указывают мышью на поле «Сквозные строки» (Rows to repeat at top), временно свертывают диалоговое окно кнопкой справа от поля, выделяют в рабочей таблице ячейки и восстанавливают диалоговое окно.
• для повторения печати столбцов аналогичные операции осуществляются в поле «Сквозные столбцы» (Columns to repeat at left).
В группе «Печать» (Print) можно выбрать режим печати с сеткой рабочей таблицы (установка флажка в позицию «Сетка» (Gridlines)), а также оптимизацию печати для черно-белых принтеров (Флажок в позиции «Черно-белая» (Black & White)) и сокращение времени печати (флажок в позиции «Черновая» (Draft quality)).
И, наконец, в диалоговом окне имеется переключатель «Последовательность вывода страниц» (Page order), задающий два метода печати данных, не помещающихся на одну страницу – «Вниз, затем вправо» (Down, then over) и «Вправо, затем вниз» (Over, then down).
Для печати документа выполняется команда «Файл» (File) / «Печать» (Print) и на экране появляется диалоговое окно «Печать» (Print), аналогичное окну для печати документов текстового процессора Word. Отличие окна для печати электронных таблиц Excel состоит в создании дополнительной группы «Вывести на печать» (Print what) с полями печати: «Выделенного диапазона» (Selection), «Выделенных листов» (Active sheets), «Всей книги» (Entire workbook). Кроме того, предусматривается масштабирование рабочего листа и просмотр с помощью кнопки «Просмотр» (Preview).
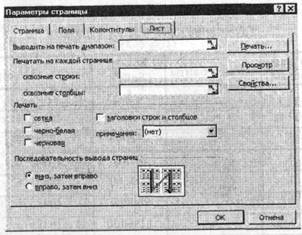
Рис. 98. Окно «Параметры страницы» с активной вкладкой «Лист»
В качестве примера использования электронных таблиц Excel можно привести расчёт минимально необходимой видеопамяти при соответствующем разрешении (пикселей), количестве оттенков цветов (в форме разрядности – бит). Сводная таблица (табл. 30) была рассчитана с помощью Excel следующим образом.
Умножив первый и второй столбец, получим отображаемое количество точек на экране. Для того, чтобы отобразить в каждой из них требуемое количество оттенков цветов, умножаем полученное количество точек на столбец 3 (переводим оттенки в биты). Делим результат на столбец 4 – для перевода в байты и получаем столбец 5. Для более привычного представления информации в столбце 7 переходим к Мбайтам, разделив результат столбца 5 на константу столбца 6, так как в 1 Мбайте 1048576 байт (столбец 6). Можно было бы также представить результат в Кбайтах, поделив данные столбца 5 на 1024 – количество байт в килобайте.
Таблица 30
Требования к размеру видеопамяти
| разрешение | разрядность | биты → байты | объем (байт) | байты → Мбайты | объем (Мбайт) | |
| 0,146 | ||||||
| 0,229 | ||||||
| 0,375 | ||||||
| 0,625 | ||||||
| 0,916 | ||||||
| 1,236 | ||||||
| 0,293 | ||||||
| 0,458 | ||||||
| 0,750 | ||||||
| 1,250 | ||||||
| 1,831 | ||||||
| 2,472 | ||||||
| 0,586 | ||||||
| 0,916 | ||||||
| 1,500 | ||||||
| 2,500 | ||||||
| 3,662 | ||||||
| 4,944 | ||||||
| 0,879 | ||||||
| 1,373 | ||||||
| 2,250 | ||||||
| 3,750 | ||||||
| 5,493 | ||||||
| 7,416 |
Технологии использования систем управления базами данных (СУБД)
Базы данных в экономических системах
На ранних этапах развития компьютерной техники любая прикладная программа сопровождалась набором специфических данных, что увеличивало ее размер и замедляло работу. В период системного развития ЭВМ, с середины 70-х гг. положение стало существенно улучшаться.
Согласно системному подходу, задачи, решаемые на ЭВМ, имеют какую-либо общую цель. Для достижения этой цели необходим определенный набор первичных данных. Образуясь по мере функционирования или развития предметной области, эти данные представляют собой бесполезную информационную совокупность, формируемую из обрывочных сведений, в которых не установлена внутренняя структура и характер взаимосвязей. Однако, в случае применения методологии объединения первичных данных на общих правилах описания, хранения и обработки, они превращаются в систематизированные и структурированные информационные массивы описания предметной области – базы данных (БД).
Базы данных представляют собой качественно новый этап в организации данных. До возникновения технологии баз данных преобладал позадачный подход. При нем приходилось, как говорилось выше, каждый раз повторять операции ввода и вывода информации, потому что каждая программа использовала свои данные, изолированные от других задач.
Действительно, при решении вопросов экономики и управления предприятием значительно меньше времени будет затрачено на ввод требуемой информации единожды. Любая информация, к примеру о сотрудниках предприятия, может быть сформирована один раз и быть доступной для всех информационных подсистем (кадровый учет, планирование, финансовое управление и многие другие). Наряду со снижением трудоемкости возникает другое преимущество использования баз данных – возможность независимости сбора и актуализации данных. Актуализация данных – обновление собранных данных на определенную дату. Данное преимущество обосновывается тремя подходами. Во-первых, появляется возможность разновременной актуализации без опасения по поводу возникновения глобальных ошибок. Во-вторых, появляется возможность модернизировать пакеты прикладных программ, работающие с базой данных, не нарушая функционирование самой базы и программ других подразделений. В третьих, возможность отделения базы данных от прикладных программ позволяет ускорить внедрение или модернизацию средств информационных технологий при разделении работы между группами внедрения или поддержки.
Процедуры актуализации занимают важное место в программном обеспечении баз данных. Если система является совокупностью баз данных отдельных пользователей, то актуализация возлагается на них, и соответствующие программные механизмы применять нет необходимости. В случае, когда база данных используется для системных применений, используется система актуализации. Административное и программное обеспечение последней возлагается на администратора.
Административное обеспечение представляет собой должностные инструкции о порядке ввода информации, сроках, формах актуализации, ответственных за это лицах. При больших размерах базы данных администрируются ее отдельные составные части.
Впервые базы данных появились в справочных системах. Различают фактографические и документальные автоматизированные информационные системы на основе баз данных.
Фактографические системы используют форматированные записи. Форматированной записью может быть даже листок по учету кадров. Определенную трудность здесь представляет полная формализация раздела «прежняя работа». Для этого потребовался бы полный классификатор предприятий и организаций.
Документальные системы отличаются от фактографических возможностью поиска документов по содержанию. Для упрощения поиска применяются ключевые слова, которые по мнению создателя конкретного документа способны наиболее полно его охарактеризовать. Такие ключевые слова образуют словарь дескрипторов.
Организация системы управления базами данных
Рассмотрим вопросы структурной организации баз данных. По своей сущности система управления базами данных (СУБД) является инструментом расширения возможностей операционной системы при работе с базами данных. Организацию баз данных (БД) можно анализировать с двух сторон: под углом зрения внемашинной логики взаимосвязи объектов и с точки зрения ее последующей внутрима-шинной, физической реализации [121; 104-119].
Логические представления о свойствах и отношениях объектов предметной области определяют построением внешней, информационно-логической модели, которая не зависит от способов физического размещения данных. В такой модели объекты представлены типами записей, свойства – полями записей, а отношения – связями между типами и полями записей. Наглядное изображение логической модели возможно двумя способами: графическим, когда схема строится в виде ориентированного графа с вершинами типов записей и дугами связей, и табличными, когда каждому типу записи (объекту) соответствует таблица с множеством полей записи (свойств).
Известны три разновидности информационно-логической модели:
1) иерархическая модель данных (ИМД) основана на графическом способе и предусматривает поиск данных по одной из ветвей «дерева», в котором каждая вершина имеет только одну связь с вершиной более высокого уровня. Для осуществления поиска необходимо указать полный путь к данным, начиная с корневого элемента;
2) сетевая модель данных (СМД) также основана на графическом способе, но допускает усложнение «дерева» без ограничения количества связей, входящих в вершину. Это позволяет строить сложные поисковые структуры;
3) в реляционной модели баз данных (РМД) реализуется табличный способ. В РМД таблица называется отношением, строка – кортежем, а столбцы – атрибутами. Область, в которой находится подмножество возможных значений атрибута, является областью определения атрибута – доменом. Характер таблицы (отношения) определяется не только количеством кортежей m, но и числом атрибутов n, которое определяет арность отношения. При наличии одного атрибута (n = 1) отношение называется унарным, двух атрибутов (n = 2) – бинарным, трех атрибутов (n = 3) – тернарным и т.д. Основное требование к отношению РМД состоит в том, что значения атрибутов должны быть элементарной, неделимой информационной единицей, что создает возможность применения в целях обработки математического аппарата реляционной алгебры. Следует также учитывать: во-первых, что фиксированный порядок следования атрибутов не играет особой роли и допустима любая последовательность их обработки, во-вторых, порядок следования картежей безразличен и, в-третьих, отношение не может иметь двух одинаковых кортежей. Работа с реляционной моделью часто включает удаление и добавление кортежей и атрибутов, что ведет к искажению информации и вызывает необходимость нормализации приведения отношений к нормальной форме (НФ) в соответствии с описанными ранее основными требованиями. Используются четыре нормальные формы: первая (1 НФ), вторая (2 НФ), третья (3 НФ), четвертая (4 НФ). Каждая из форм нормализации достигается проведением соответствующего этапа нормализации. Все отношения обязательно должны находиться в форме 1 НФ, что обеспечивается применением декомпозиции (разделения) отношения на эквивалентную совокупность отношений более низкого уровня.
Конкретные способы и средства размещения данных, описанные в логической модели, в физической среде хранения, определяют построение внутренней, физической модели организации баз данных. Физическая модель должна отвечать следующим требованиям:
• сохранению смыслового содержания логической модели;
• максимальной экономии внешней памяти;
• минимизации затрат по управлению данными;
• максимальному быстродействию при поиске и при обработке запросов.
Физическое моделирование осуществляется средствами СУБД: языком описания данных (ЯОД), языком манипулирования данными (ЯМД), структурами хранения и поиска. Создаваемые модели могут базироваться на структуре хранения данных или сочетать структуру хранения с поисковыми структурами. В последнем случае после завершения этапа физического моделирования в памяти ЭВМ появляются файл базы данных и файлы поисковых структур. К поисковым структурам относят:
• Линейный список. Файл базы данных рассматривается как строго определенная последовательность записей, поиск которых происходит с помощью алгоритма вычисления адреса. Этот способ обеспечивает наиболее экономное использование памяти, но не отличается быстродействием.
• Цепной список. В конце каждой записи файла, в дополнительном поле указывается адрес связи (АС) для перехода к другой записи, что позволяет задавать любую последовательность выборки. Для начала поиска в цепной структуре необходимо войти в запись заголовка или фиксатор списка (ФС), где хранится адрес начала списка (АНС). В дополнительном поле последней читаемой записи указывается адрес конца списка (КС). Список можно сделать кольцевым (цепным), если поместить в дополнительное поле последней записи адрес фиксатора списка. Кроме того, в запись может быть добавлено любое количество адресов, что обеспечивает множество вариантов выборки.
• Инвертированный файл, в котором записи упорядочены по неключевому полю. Создание инвертированного файла заключается в изменении порядка следования записей основного файла в соответствии со значениями неключевого поля. Полное инвертирование основного файла происходит при создании инвертированных структур для каждого из неключевых полей. С помощью инвертирования достигается наиболее быстрый поиск информации, но многократное дублирование информации ведет к перерасходу памяти;
• Индексный файл, который представляет собой инвертированный файл адресов записей основного файла. Замена инвертирования самих записей инвертированием адресов позволяет осуществить поисковые операции с меньшими ресурсами памяти.
СУБД обеспечивает не только создание, но и процесс использования баз данных. Необходимость применения СУБД как самостоятельной программной системы диктуется следующими обстоятельствами:
• операционные системы и языки программирования не ориентированы на специфические параметры логической и физической организации баз данных;
• для описания баз данных недостаточно стандартных прикладных программ, а требуется специальное программное обеспечение, создаваемое и обрабатываемое с помощью программных средств (языки программирования СУБД);
• доступ к данным требует разработки специальных алгоритмов и управляющих программ;
• в операционных системах и языках программирования не разработаны вопросы специальной обработки баз данных (целостность и непротиворечивость данных, декомпозиция запросов, параллельное выполнение транзакций и т.д.), не предусмотрены операции реляционной алгебры, которые необходимы в реляционных базах данных.
Для создания, ведения и корректировки баз данных используются пакеты систем управления базами данных (СУБД), которые включают:
• языковые средства (трансляторы с языков описания данных, языков манипулирования данными, языков программирования, редакторов и отладчиков);
• прикладные программные пакеты управления процессами обработки данных (обслуживание задач, поддержка запросов, пополнение и корректировка данных, взаимодействие программ обработки с операционной системой, регулирование доступа и т.д.).
СУБД выполняет три группы функций: управляющую, обрабатывающую (трансляция) и сервисную. Управление заключается в выполнении операций над файлами (открытие, закрытие, копирование, переименование и т.д.), записями (кортежами), полями записей (атрибутами). Обработка предусматривает отладку и выполнение прикладных программ операций с данными. Сервисная функция поддерживает ряд вспомогательных операций.
В соответствии с основными группами функций СУБД включает в себя взаимосвязанные управляющие, обрабатывающие и сервисные программы, которые взаимодействуют с операционной системой. После запуска СУБД происходит загрузка в память компьютера большинства управляющих программ, которые называют ядром системы, а подключение остальных модулей осуществляется по желанию пользователя.
СУБД классифицируют на основании внешней, информационно-логической модели на три вида: иерархические, сетевые, реляционные. Наиболее популярны реляционные СУБД dBase HI Plus, FoxBase, FoxPro, Clipper, dBase IV, Clarion, Paradox, Oracle и др.
При обеспечении обработки (трансляции) программ СУБД может работать в двух режимах:
• интерпретации, когда программа обрабатывается и выполняется последовательно с синтаксическим контролем, преобразованием и немедленным выполнением каждого оператора в виде сгенерированных машинных команд;
• компиляции, когда происходит синтаксический контроль всей программы, генерация объектного модуля с помощью компилятора и обработка объектного модуля редактором связей с созданием выполняемого файла с расширением *.ехе.
В режиме интерпретации работают СУБД dBase III Plus, FoxBase, в режиме компиляции СУБД Clipper, в смешанном режиме – СУБД Clarion.
Языки программирования, используемые в СУБД, классифицируются по ряду признаков.
1) По степени открытости различают:
• открытые (включающие) языки, которые являются стандартными языками программирования, расширенными специальными средствами подъязыка данных (операторами манипулирования данными). При использовании открытого языка компиляция исходной программы протекает в два этапа: компиляция с подъязыка данных с преобразованием в операторы включающего языка и компиляция всей программы с получением объектного модуля;
• замкнутые (автономные) языки (dBase, Clipper, SQL, QBE и др.), которые являются специализированными средствами работы с базами данных. По сравнению с открытыми, замкнутые языки обладают более широкими возможностями манипулирования данными, но уступают по вычислительным параметрам.
2) По степени алгоритмизации:
• процедурные языки, например, dBase, ISBL требуют от пользователя полного описания алгоритма с ответом на вопросы о том, что и как необходимо получить;
• декларативные языки, например QBE, допускают только указание результата без описания конкретных шагов по его получению.
3) По используемому математическому аппарату языки можно разделить на три уровня. Языки нижнего уровня, которые обычно применяют в СУБД иерархических и сетевых баз данных, построены на манипулировании одиночными записями. Языки более высокого уровня, например ISBL фирмы IBM, используют аппарат реляционной алгебры и допускают манипулирование множеством записей. И, наконец, языки высшего уровня, например язык Альфа, характеризуются абсолютной непроцедурностью и основаны на исчислении отношений.
Вопросы разработки и внедрения баз данных
Наиболее частыми являются два подхода, используемые при проектировании баз данных: структурный и объектно-ориентированный.
Популярность получил объектный подход, так как это обосновано его преимуществами: возможностью разбить систему на совокупность независимых объектов и далее провести их независимую спецификацию, простотой системы за счет использования принципов наследования и полиморфизма, возможностью объектного моделирования системы. Последнее означает возможность получить представление о разработке с момента начала создания системы.
Объектная модель представления данных отлично подходит для применения при построении корпоративных информационных систем. В распоряжении разработчиков оказываются стандартизованные средства доступа к базам данных стандарта ODMG93.
Различные производители баз данных по-разному используют в своих продуктах достоинства и недостатки объектных баз данных. Даже производители реляционных СУБД, такие как IBM и Oracle, совершенствуют свои СУБД, добавляя объектную надстройку над реляционным ядром. Другой производитель – Informix приобрел РЯД конкурентов и усовершенствовал свою объектно-реляционную СУБД, ставшую универсальным сервером. А компания Computer Associates создала объектную базу Jasmine.
Рост спроса на объектные СУБД выше, чем на реляционные и объектно-реляционные. Если первые демонстрируют динамику роста до 50% в год, то вторые – около 30%. Общий объем продаж объектных СУБД к 2000 г. должен составлять около 1,5 млрд USD.
С точки зрения особенностей моделей данных можно выделить две основные группы: чисто объектные СУБД (pure ODBMS) и СУБД, основанные на модели сохраняемых объектов (persistent storage managers). Первые поддерживают механизмы распределенных баз данных (transparent distributed database capabilities), многопользовательского доступа к БД, имеют встроенные средства разработки и администрирования. СУБД, которые основаны на модели сохраняемых объектов, позволяют сохранять небольшие объекты с их идентификаторами, что ограничивает создание многопользовательских приложений и распределенных систем.
Во всем мире множество компаний разрабатывают и применяют базы данных (БД) в маркетинговых и сбытовых целях, анализа степени использования основных фондов и оборотных средств, управления товарными запасами и т.д. Вот лишь несколько примеров из самых разных областей деятельности [195,196].
Компания Claritas (США) проводит углубленные маркетинговые исследования и создает информационные продукты по многокритериальному описанию различных регионов США. Многочисленные клиенты Claritas, а это фирмы самого разного профиля, закупили лицензию на одну из основных разработок компании – настольную систему маркетингового анализа Compass for Windows. Для использования указанной системы необходимы частные базы данных, содержащие определенный набор демографической, маркетинговой, картографической информации, позволяющей провести рыночный анализ с учетом специфики деятельности фирмы-клиента. Работа по созданию и постоянному обновлению таких информационных продуктов потребовала от компании Claritas перехода к новым методам получения и обработки информации.
До 1996 года база данных компании объемом 120 Гбайт находилась на мэйнфрейме фирмы IBM. При этом был необходим целый штат программистов для извлечения данных из базы, проверки их достоверности и обработки с целью получения новых или обновления существующих информационных продуктов. Обновление могло происходить не чаще одного раза в год и влекло за собой рост числа и объема документации. Для доставки продуктов клиентам осуществлялось ручное копирование данных из файлов хранения.
В 1996-1997 гг. была создана промышленная база данных на сервере Alpha Server 4100 корпорации Digital Equipment с программным обеспечением в виде СУБД Oracle версии 7.3. В дополнение компания Claritas разработала собственное программное средство – внутреннюю клиент-серверную утилиту Auto Trieve, которая позволяет автоматически обновлять информационные продукты. В результате применения новой технологии резко сократились сроки подготовки продуктов. Например, по расчетам специалистов компании, проект, предусматривающий создание 150 частных баз данных (информационных продуктов), может быть выполнен за три дня вместо четырех недель. Новая технология обеспечивает упрощенную поддержку качества данных, так как применены стандарты структур данных в виде метаданных для каждой из 6 млн ячеек информации. В течение 1998 года компания выпустила программный продукт Claritas Connect, который позволит клиентам работать со специализированными киосками данных, размещенными на Web-сервере Claritas.
Американская компания Source Informatics America специализируется на информационном обслуживании фирм-производителей лекарственных препаратов. Закупая информацию в 75% (35 000) аптек страны, компания составляет и предоставляет на платной основе аналитические отчеты о выписке врачебных рецептов при различных заболеваниях, что помогает фирмам-производителям лекарств правильно определять тенденции на рынке. Постоянное расширение рынка потребовало от компании обработки все возрастающих объемов информации, что повысило сроки составления отчетов (более месяца), их трудоемкость, обусловило высокую стоимость для клиентов. Были необходимы новые формы работы и в 1996 году компания Source Informatics приступила к осуществлению дорогостоящего (5 млн USD) проекта разработки специализированной базы данных на 1,5 Тбайт. Реализация аппаратной части проекта происходила с привлечением фирмы Sequent Computer Systems, которая предложила технологию неоднородного доступа к памяти NUMA (Non – Uniform Memory Access) с установкой соответствующей машины – сервера Sequent NUMA – Q2000. В качестве программного обеспечения использовалась система управления базами данных (СУБД) Oracle, а также программные пакеты поиска и обработки данных DDS Agent и DDS Architect фирмы MicroStrategy. Благодаря новой базе данных сроки составления отчетов сократились до нескольких дней. Кроме того, круг клиентов компании существенно расширился не только за счет снижения стоимости информационных услуг, но и потому, что клиенты получили возможность самостоятельного доступа к данным через телефонную сеть. Для пяти фирм-клиентов созданы индивидуальные киоски данных о продажах, расположенные на серверах Alpha корпорации Digital Equipment и связанные с данными основной базы через систему перекрестных ссылок. Недавно компания Source Informatics предложила клиентам услуги по прямому подключению к базе данных из Web-браузеров с помощью программного обеспечения онлайновой аналитической обработки DDS Web фирмы MicroStrategy.
Фирма Randalls Food Markets в 1995 году с большой осторожностью начинала создавать базу данных, сочетающую информацию о товарных запасах с демографическими данными о покупателях и их привязанностях (кто и что покупает). Не существовало четких критериев и оценок эффективности затрат на осуществление проекта. Многобайтная база данных для управления почти 600 категориями продуктов на 80 000 наименований создавалась 6 месяцев на основании СУБД фирмы Informix Software. После внедрения системы менеджеры категорий товаров получили возможность быстрого доступа с настольных персональных компьютеров к информации о наличии товаров и скорости и частоте продаж. За короткое время фирма улучшила состояние складского хозяйства и сумела увеличить сбыт товаров, получив значительную дополнительную прибыль. В фирмах розничной торговли США нарастает тенденция использования баз данных, содержащих информацию о товарных запасах и дополнительные сведения о клиентах.
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 674; Нарушение авторских прав?; Мы поможем в написании вашей работы!