КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Коллективный обмен
|
|
|
|
Участниками коллективного обмена являются более двух процессов.
Широковещательная рассылка
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERR)
Параметры этой процедуры одновременно являются входными и выходными:
- buffer - адрес буфера;
- count - количество элементов данных в сообщении;
- datatype - тип данных MPI;
- root - ранг главного процесса, выполняющего широковещательную рассылку;
- comm - коммуникатор.
Схема распределения данных представлена на рис. 3.4.
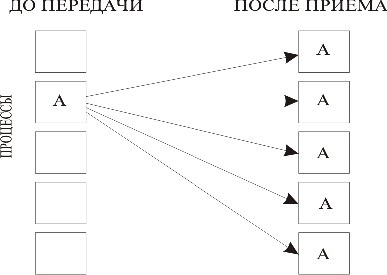
Рис. 3.4. Распределение данных при широковещательной рассылке
Синхронизация с помощью "барьера" (рис. 3.5)
int MPI_Barrier(MPI_Comm comm)
MPI_BARRIER(COMM, IERR)
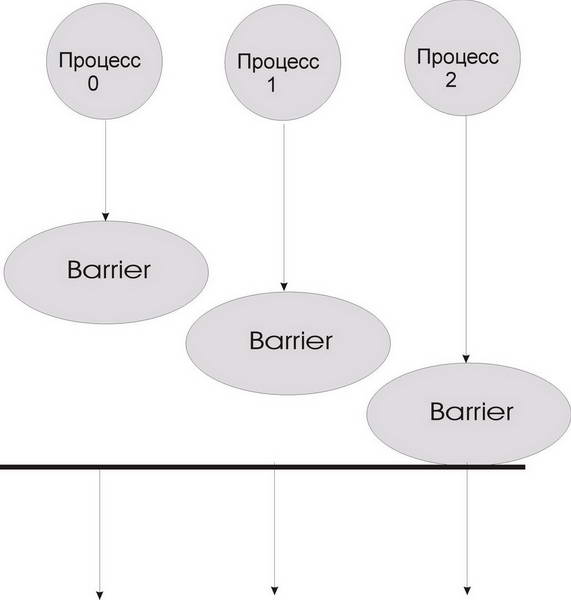
Рис. 3.5. Синхронизация с "барьером"
При синхронизации с барьером выполнение каждого процесса из данного коммуникатора приостанавливается до тех пор, пока все процессы не выполнят вызов процедуры синхронизации MPI_Barrier.
Распределение данных
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount,
MPI_Datatype rcvtype, int root, MPI_Comm comm)
MPI_SCATTER(SENDBUF,SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT,
RCVTYPE, ROOT, COMM, IERR)
Входные параметры:
- sendbuf - адрес буфера передачи;
- sendcount - количество элементов, пересылаемых каждому процессу (но не суммарное количество пересылаемых элементов);
- sendtype - тип передаваемых данных;
- rcvcount - количество элементов в буфере приема;
- rcvtype - тип принимаемых данных;
- root - ранг передающего процесса;
- comm - коммуникатор.
Выходной параметр:
- rcvbuf - адрес буфера приема.
Процесс с рангом root распределяет содержимое буфера передачи sendbuf среди всех процессов (рис. 3.6). Содержимое буфера передачи разбивается на несколько фрагментов, каждый из которых содержит sendcount элементов. Первый фрагмент передается процессу 0, второй процессу 1 и т. д. Аргументы sendимеют значение только на стороне процесса root.
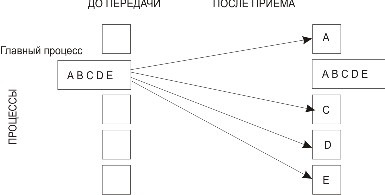
Рис. 3.6. Распределение данных при выполнении операции Scatter
Сбор сообщений от остальных процессов в буфер главной задачи
int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf,
int rcvcount, MPI_Datatype rcvtype, int root, MPI_Comm comm)
MPI_GATHER(SENDBUF, SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, ROOT, COMM, IERR)
Каждый процесс в коммуникаторе comm пересылает содержимое буфера передачи sendbuf процессу с рангом root. Процесс root "склеивает" полученные данные в буфере приема (рис. 3.7). Порядок склейки определяется рангами процессов, то есть в результирующем наборе после данных от процесса 0 следуют данные от процесса 1, затем данные от процесса 2 и т. д. Аргументы rcvbuf, rcvcount и rcvtype играют роль только на стороне главного процесса. Аргумент rcvcountуказывает количество элементов данных, полученных от каждого процесса (но не суммарное их количество). При вызове подпрограмм MPI_Scatter и MPI_Gatherиз разных процессов следует использовать общий главный процесс.
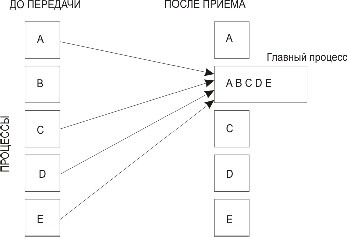
Рис. 3.7. Сбор данных при выполнении операции Gather
Векторная подпрограмма распределения данных
int MPI_Scatterv(void *sendbuf, int *sendcounts, int *displs,
MPI_Datatype sendtype, void *rcvbuf, int rcvcount,
MPI_Datatype rcvtype, int root, MPI_Comm comm)
MPI_SCATTERV(SENDBUF, SENDCOUNTS, DISPLS, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, ROOT, COMM, IERR)
Входные параметры:
- sendbuf - адрес буфера передачи;
- sendcounts - целочисленный одномерный массив, содержащий количество элементов, передаваемых каждому процессу (индекс равен рангу адресата). Его длина равна количеству процессов в коммуникаторе;
- displs - целочисленный массив, длина которого равна количеству процессов в коммуникаторе. Элемент с индексом i задает смещение относительно начала буфера передачи. Ранг адресата равен значению индекса i;
- sendtype - тип данных в буфере передачи;
- rcvcount - количество элементов в буфере приема;
- rcvtype - тип данных в буфере приема;
- root - ранг передающего процесса;
- comm - коммуникатор.
Выходной параметр:
- rcvbuf - адрес буфера приема.
Сбор данных от всех процессов в заданном коммуникаторе и запись их в буфер приема с указанным смещением
int MPI_Gatherv(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf,
int *recvcounts, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)
MPI_GATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNTS,
DISPLS, RECVTYPE, ROOT, COMM, IERR)
Список параметров у этой подпрограммы похож на список параметров подпрограммы MPI_Scatterv. В обменах, выполняемых подпрограммами MPI_Allgather иMPI_Alltoall, нет главного процесса. Детали отправки и приема важны для всех процессов, участвующих в обмене.
Сбор данных от всех процессов и распределение их всем процессам
int MPI_Allgather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf,
int rcvcount, MPI_Datatype rcvtype, MPI_Comm comm)
MPI_ALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, COMM, IERR)
Входные параметры:
- sendbuf - начальный адрес буфера передачи;
- sendcount - количество элементов в буфере передачи;
- sendtype - тип передаваемых данных;
- rcvcount - количество элементов, полученных от каждого процесса;
- rcvtype - тип данных в буфере приема;
- comm - коммуникатор.
Выходной параметр:
- rcvbuf - адрес буфера приема.
Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается в j-м блоке буфера приема recvbuf (рис. 3.8).
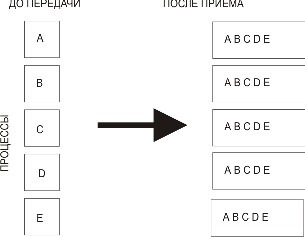
Рис. 3.8. Сбор и распределение данных при выполнении операции Allgather
Пересылка данных по схеме "каждый - всем"
int MPI_Alltoall(void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *rcvbuf, int rcvcount, MPI_Datatype rcvtype, MPI_Comm comm)
MPI_ALLTOALL(SENDBUF, SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNT, RCVTYPE, COMM, IERR)
Входные параметры:
- sendbuf - начальный адрес буфера передачи;
- sendcount - количество элементов данных, пересылаемых каждому процессу;
- sendtype - тип данных в буфере передачи;
- rcvcount - количество элементов данных, принимаемых от каждого процесса;
- rcvtype - тип принимаемых данных;
- comm - коммуникатор.
Выходной параметр:
- rcvbuf - адрес буфера приема.
Векторными версиями MPI_Allgather и MPI_Alltoall являются подпрограммы MPI_Allgatherv и MPI_Alltoallv.
Сбор данных от всех процессов и пересылка их всем процессам
int MPI_Allgatherv(void *sendbuf, int sendcount, MPI_Datatype sendtype,
void *rcvbuf, int *rcvcounts, int *displs, MPI_Datatype rcvtype, MPI_Comm comm)
MPI_ALLGATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RCVBUF, RCVCOUNTS, DISPLS, RCVTYPE, COMM, IERR)
Ее параметры совпадают с параметрами подпрограммы MPI_Allgather, за исключением дополнительного входного параметра displs. Это целочисленный одномерный массив, количество элементов в котором равно количеству процессов в коммуникаторе. Элемент массива с индексом i задает смещение относительно начала буфера приема recvbuf, в котором располагаются данные, принимаемые от процесса i. Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается в j-м блоке буфера приема.
Пересылка данных от всех процессов всем процессам со смещением
int MPI_Alltoallv(void *sendbuf, int *sendcounts, int *sdispls,
MPI_Datatype sendtype, void *rcvbuf, int *rcvcounts, int *rdispls,
MPI_Datatype rcvtype, MPI_Comm comm)
MPI_ALLTOALLV(SENDBUF, SENDCOUNTS, SDISPLS, SENDTYPE, RCVBUF, RCVCOUNTS, RDISPLS, RCVTYPE, COMM, IERR)
Ее параметры аналогичны параметрам подпрограммы MPI_Alltoall, кроме двух дополнительных параметров:
- sdispls - целочисленный массив, количество элементов в котором равно количеству процессов в коммуникаторе. Элемент j задает смещение относительно начала буфера, из которого данные передаются j -му процессу.
- rdispls - целочисленный массив, количество элементов в котором равно количеству процессов в коммуникаторе. Элемент i задает смещение относительно начала буфера, в который принимается сообщение от i -го процесса.
Операция приведения, результат которой передается одному процессу
int MPI_Reduce(void *buf, void *result, int count,
MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
MPI_REDUCE(BUF, RESULT, COUNT, DATATYPE, OP, ROOT, COMM, IERR)
Входные параметры:
- buf - адрес буфера передачи;
- count - количество элементов в буфере передачи;
- datatype - тип данных в буфере передачи;
- op - операция приведения;
- root - ранг главного процесса;
- comm - коммуникатор.
MPI_Reduce применяет операцию приведения к операндам из buf, а результат каждой операции помещается в буфер результата result (рис. 3.9). MPI_Reduceдолжна вызываться всеми процессами в коммуникаторе comm, а аргументы count, datatype и op в этих вызовах должны совпадать.
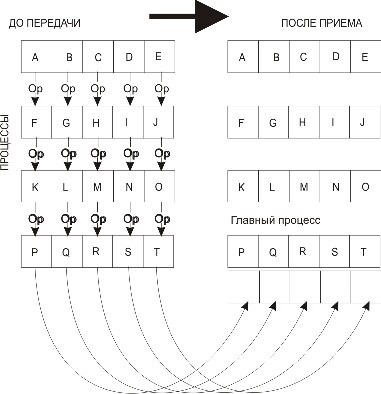
Рис. 3.9. Распределение данных при выполнении операции приведения
Предопределенные операции приведения приведены в табл. 3.3.
Определение собственных глобальных операций
int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op)
MPI_OP_CREATE(FUNCTION, COMMUTE, OP, IERR)
Входные параметры:
- function - пользовательская функция;
- commute - флаг, которому присваивается значение "истина", если операция коммутативна (результат не зависит от порядка операндов).
Описание типа пользовательской функции выглядит следующим образом:
typedef void (MPI_User_function)(void *a, void *b, int *len, MPI_Datatype *dtype)
Здесь операция определяется так:
b[I] = a[I] op b[I]
для I = 0,..., len-1.
| Таблица 3.3. Предопределенные операции приведения MPI | |
| Операция | Описание |
| MPI_MAX | Определение максимальных значений элементов одномерных массивов целого или вещественного типа |
| MPI_MIN | Определение минимальных значений элементов одномерных массивов целого или вещественного типа |
| MPI_SUM | Вычисление суммы элементов одномерных массивов целого, вещественного или комплексного типа |
| MPI_PROD | Вычисление поэлементного произведения одномерных массивов целого, вещественного или комплексного типа |
| MPI_LAND | Логическое "И" |
| MPI_BAND | Битовое "И" |
| MPI_LOR | Логическое "ИЛИ" |
| MPI_BOR | Битовое "ИЛИ" |
| MPI_LXOR | Логическое исключающее "ИЛИ" |
| MPI_BXOR | Битовое исключающее "ИЛИ" |
| MPI_MAXLOC | Максимальные значения элементов одномерных массивов и их индексы |
| MPI_MINLOC | Минимальные значения элементов одномерных массивов и их индексы |
Удаление пользовательской функции
int MPI_Op_free(MPI_Op *op)
MPI_OP_FREE(OP, IERR)
После завершения вызова op присваивается значение MPI_OP_NULL.
Одновременные сбор и распределение данных
int MPI_Reduce_scatter(void *sendbuf, void *rcvbuf, int *rcvcounts,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_REDUCE_SCATTER(SENDBUF,RCVBUF,RCVCOUNTS,DATATYPE,OP,COMM, IERR)
Входные параметры:
- sendbuf - стартовый адрес буфера приема;
- rcvcounts - целочисленный одномерный массив, который задает количество элементов в результирующем массиве, распределяемом каждому процессу. Этот массив должен быть одинаковым во всех процессах, вызывающих данную подпрограмму;
- datatype - тип данных в буфере приема;
- op - операция;
- comm - коммуникатор.
Выходной параметр:
- rcvbuf - стартовый адрес буфера приема.
Каждая задача получает не весь результирующий массив, а его часть.
Сбор данных от всех процессов и сохранение результата операции приведения в результирующем буфере каждого процесса
int MPI_Allreduce(void *sendbuf, void *rcvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_ALLREDUCE(SENDBUF, RCVBUF, COUNT, DATATYPE, OP, COMM, IERR)
Входные параметры:
- sendbuf - начальный адрес буфера передачи;
- count - количество элементов в буфере передачи;
- datatype - тип передаваемых данных;
- op - операция приведения;
- comm - коммуникатор. Выходной параметр:
- rcvbuf - стартовый адрес буфера приема.
При аварийном завершении подпрограмма может возвращать код ошибки MPI_ERR_OP (некорректная операция). Это происходит, если применяется операция, которая не является предопределенной и которая не создана предшествующим вызовом подпрограммы MPI_Op_create.
Операции сканирования (частичной редукции)
int MPI_Scan(void *sendbuf, void *rcvbuf, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_SCAN(SENDBUF, RCVBUF, COUNT, DATATYPE, OP, COMM, IERR)
Входные параметры:
- sendbuf - начальный адрес буфера передачи;
- count - количество элементов во входном буфере;
- datatype - тип данных во входном буфере;
- op - операция;
- comm - коммуникатор.
Выходной параметр:
- rcvbuf - стартовый адрес буфера приема.
Стандартный коммуникатор MPI_COMM_WORLD создается автоматически при запуске параллельной программы на выполнение. Напомним, что имеются также стандартные коммуникаторы:
- MPI_COMM_SELF - коммуникатор, содержащий только вызывающий процесс;
- MPI_COMM_NULL - пустой коммуникатор.
Получение доступа к группе group, связанной с коммуникатором comm
int MPI_Comm_group(MPI_Comm comm, MPI_Group *group)
MPI_COMM_GROUP(COMM, GROUP, IERR)
Выходной параметр - группа. Для выполнения операций с группой к ней сначала необходимо получить доступ.
Создание новой группы newgroup из n процессов, входящих в группу oldgroup
int MPI_Group_incl(MPI_Group oldgroup, int n, int *ranks, MPI_Group *newgroup)
MPI_GROUP_INCL(OLDGROUP, N, RANKS, NEWGROUP, IERR)
Ранги процессов содержатся в массиве ranks. В новую группу войдут процессы с рангами ranks[0], ranks[n - 1],причем рангу i в новой группе соответствует ранг ranks[i] в старой группе. При n = 0 создается пустая группа MPI_GROUP_EMPTY. С помощью данной подпрограммы можно не только создать новую группу, но и изменить порядок процессов в старой группе.
Создание группы newgroup исключением из исходной группы (group) процессы с рангами ranks[0]..., ranks[n - 1]
int MPI_Group_excl(MPI_Group oldgroup, int n, int *ranks, MPI_Group *newgroup)
MPI_GROUP_EXCL(OLDGROUP, N, RANKS, NEWGROUP, IERR)
При n = 0 новая группа тождественна старой.
Создание группы newgroup из группы group добавлением в нее n процессов, ранг которых указан в массиве ranks
int MPI_Group_range_incl(MPI_Group oldgroup, int n, int ranks[][3], MPI_Group *newgroup)
MPI_GROUP_RANGE_INCL(OLDGROUP, N, RANKS, NEWGROUP, IERR)
Массив ranks состоит из целочисленных триплетов вида (первый_1, последний_1, шаг_1),..., (первый_n, последний_n, шаг_n). В новую группу войдут процессы с рангами (по первой группе) первый_1, первый_1 + шаг_1,....
Создание группы newgroup из группы group исключением из нее n процессов, ранг которых указан в массиве ranks
int MPI_Group_range_excl(MPI_Group group, int n, int ranks[][3], MPI_Group *newgroup)
MPI_GROUP_RANGE_EXCL(GROUP, N, RANKS, NEWGROUP, IERR)
Массив ranks устроен так же, как аналогичный массив в подпрограмме MPI_Group_range_incl.
Создание новой группы (newgroup) из разности двух групп (group1) и (group2)
int MPI_Group_difference(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
MPI_GROUP_DIFFERENCE(GROUP1, GROUP2, NEWGROUP, IERR)
Создание новой группы (newgroup) из пересечения групп group1 и group2
int MPI_Group_intersection(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
MPI_GROUP_INTERSECTION(GROUP1, GROUP2, NEWGROUP, IERR)
Создание группы (newgroup) объединением групп group1 и group2
Int MPI_Group_union(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
MPI_GROUP_UNION(GROUP1, GROUP2, NEWGROUP, IERR)
Имеются и другие подпрограммы-конструкторы новых групп.
Уничтожение группы group
int MPI_Group_free(MPI_Group *group)
MPI_GROUP_FREE(GROUP, IERR)
Определение количества процессов (size) в группе (group)
MPI_GROUP_SIZE(GROUP, SIZE, IERR)
int MPI_Group_size(MPI_Group group, int *size)
Определение ранга (rank) процесса в группе group
int MPI_Group_rank(MPI_Group group, int *rank)
MPI_GROUP_RANK(GROUP, RANK, IERR)
Если процесс не входит в указанную группу, возвращается значение MPI_UNDEFINED.
Преобразование ранга процесса в одной группе в его ранг относительно другой группы
int MPI_Group_translate_ranks(MPI_Group group1, int n,
int *ranks1, MPI_Group group2, int *ranks2)
MPI_GROUP_TRANSLATE_RANKS(GROUP1, N, RANKS1, GROUP2, RANKS2, IERR)
Сравнение групп group1 и group2
int MPI_Group_compare(MPI_Group group1, MPI_Group group2, int *result)
MPI_GROUP_COMPARE(GROUP1, GROUP2, RESULT, IERR)
Если группы полностью совпадают, возвращается значение MPI_IDENT. Если члены обеих групп одинаковы, но их ранги отличаются, результатом будет значениеMPI_SIMILAR. Если группы различны, результатом будет MPI_UNEQUAL.
Создание дубликата уже существующего коммуникатора oldcomm int
MPI_Comm_dup(MPI_Comm oldcomm, MPI_Comm *newcomm)
MPI_COMM_DUP(OLDCOMM, NEWCOMM, IERR)
В результате вызова данной подпрограммы создается новый коммуникатор (newcomm) с той же группой процессов, с теми же атрибутами, но с другим контекстом. Подпрограмма может применяться как к интра-, так и к интеркоммуникаторам.
Создание нового коммуникатора (newcomm) из подмножества процессов (group) другого коммуникатора (oldcomm)
int MPI_Comm_create(MPI_Comm oldcomm, MPI_Group group, MPI_Comm *newcomm)
MPI_COMM_CREATE(OLDCOMM, GROUP, NEWCOMM, IERR)
Вызов этой подпрограммы должны выполнить все процессы из старого коммуникатора, даже если они не входят в группу group, с одинаковыми аргументами. Если одновременно создаются несколько коммуникаторов, они должны создаваться в одной последовательности всеми процессами.
Создание нескольких коммуникаторов сразу методом расщепления
int MPI_Comm_split(MPI_Comm oldcomm, int split, int rank, MPI_Comm* newcomm)
MPI_COMM_SPLIT(OLDCOMM, SPLIT, RANK, NEWCOMM, IERR)
Группа процессов, связанных с коммуникатором oldcomm, разбивается на непересекающиеся подгруппы, по одной для каждого значения аргумента split. Процессы с одинаковым значением split образуют новую группу. Ранг в новой группе определяется значением rank. Если процессы A и B вызываютMPI_Comm_split с одинаковым значением split, а аргумент rank, переданный процессом A, меньше, чем аргумент, переданный процессом B, ранг A в группе, соответствующей новому коммуникатору, будет меньше ранга процесса B. Если же в вызовах используется одинаковое значение rank, система присвоит ранги произвольно. Для каждой подгруппы создается собственный коммуникатор newcomm.
MPI_Comm_split должны вызвать все процессы из старого коммуникатора, даже если они не войдут в новый коммуникатор. Для этого в качестве аргумента splitв подпрограмму передается предопределенная константа MPI_UNDEFINED. Соответствующие процессы вернут в качестве нового коммуникатора значениеMPI_COMM_NULL. Новые коммуникаторы, созданные подпрограммой MPI_Comm_split, не пересекаются, однако с помощью повторных вызовов подпрограммыMPI_Comm_split можно создавать и перекрывающиеся коммуникаторы.
Пометить коммуникатор comm для удаления
int MPI_Comm_free(MPI_Comm *comm)
MPI_COMM_FREE(COMM, IERR)
Обмены, связанные с этим коммуникатором, завершаются обычным образом, а сам коммуникатор удаляется только после того, как на него не будет активных ссылок. Данная операция может применяться к коммуникаторам интра- и интер-.
Сравнение двух коммуникаторов (comm1) и (comm2)
int MPI_Comm_compare(MPI_Comm comm1, MPI_Comm comm2, int *result)
MPI_COMM_COMPARE(COMM1, COMM2, RESULT, IERR)
Выходной параметр:
- result - целое значение, которое равно MPI_IDENT, если контексты и группы коммуникаторов совпадают; MPI_CONGRUENT, если совпадают только группы;MPI_SIMILAR и MPI_UNEQUAL, если не совпадают ни группы, ни контексты.
В качестве аргументов нельзя использовать пустой коммуникатор MPI_COMM_NULL.
Присвоение коммуникатору comm строкового имени name
int MPI_Comm_set_name(MPI_Comm com, char *name)
MPI_COMM_SET_NAME(COM, NAME, IERR)
Определение имени коммуникатора
int MPI_Comm_get_name(MPI_Comm comm, char *name, int *reslen)
MPI_COMM_GET_NAME(COMM, NAME, RESLEN, IERR)
Выходной параметр:
- name - строковое имя коммуникатора comm.;
- reslen - длина имени.
Имя представляет собой массив символьных значений, длина которого должна быть не более MPI_MAX_NAME_STRING.
Проверка, является ли коммуникатор comm (входной параметр) интеркоммуникатором
int MPI_Comm_test_inter(MPI_Comm comm, int *flag)
MPI_COMM_TEST_INTER(COMM, FLAG, IERR)
Выходной параметр:
- flag - значение флага "истина", если аргументом является интеркоммуникатор.
Создание интракоммуникатора newcomm из интеркоммуникатора oldcomm
int MPI_Intercomm_merge(MPI_Comm oldcomm, int high, MPI_Comm *newcomm)
MPI_INTERCOMM_MERGE(OLDCOMM, HIGH, NEWCOMM, IERR)
Параметр high используется для упорядочения групп обоих интракоммуникаторов в comm при создании нового коммуникатора.
Получение доступа к удаленной группе, связанной с интеркоммуникатором comm int
MPI_Comm_remote_group(MPI_Comm comm, MPI_Group *group)
MPI_COMM_REMOTE_GROUP(COMM, GROUP, IERR)
Выходной параметр:
- group - удаленная группа.
Определение размера удаленной группы, связанной с интеркоммуникатором comm int
MPI_Comm_remote_size(MPI_Comm comm, int *size)
MPI_COMM_REMOTE_SIZE(COMM, SIZE, IERR)
Выходной параметр:
- size - количество процессов в области взаимодействия, связанной с коммуникатором comm.
Создание интеркоммуникатора
int MPI_Intercomm_create(MPI_Comm local_comm, int local_leader,
MPI_Comm peer_comm, int remote_leader, int tag, MPI_Comm *new_intercomm)
MPI_INTERCOMM_CREATE(LOCAL_COMM, LOCAL_LEADER, PEER_COMM, REMOTE_LEADER, TAG, NEW_INTERCOMM, IERR)
Входные параметры:
- local_comm - локальный интракоммуникатор;
- local_leader - ранг лидера в локальном коммуникаторе (обычно 0);
- peer_comm - удаленный коммуникатор;
- remote_leader - ранг лидера в удаленном коммуникаторе (обычно 0);
- tag - тег интеркоммуникатора, используемый лидерами обеих групп для обменов в контексте родительского коммуникатора.
Выходной параметр:
- new_intercomm - интеркоммуникатор.
"Джокеры" в качестве параметров использовать нельзя. Вызов этой подпрограммы должен выполняться в обеих группах процессов, которые должны быть связаны между собой. В каждом из этих вызовов используется локальный интракоммуникатор, соответствующий данной группе процессов. При работе сMPI_Intercomm_create локальная и удаленная группы процессов не должны пересекаться, иначе возможны "тупики".
|
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 380; Нарушение авторских прав?; Мы поможем в написании вашей работы!