КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование данных
|
|
|
|
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления — для этого обычно используется прием кодирования, т. е. выражение данных одного типа через данные другого типа. Примерами кодирования являются естественные человеческие языки (системы кодирования понятий для выражения мыслей посредством речи), азбуки (системы кодирования компонентов языка посредством графических символов) и др.
Компьютеры предпочитают работать с цифровыми данными из-за удобства их хранения и обработки. В вычислительной технике применяется двоичная система кодирования — она основана на представлении данных последовательностью всего двух знаков: 0 и 1, т. е. двоичной системы счисления. Эти знаки называют двоичными цифрами, т. е. битами. Одним битом могут быть выражены всего два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия: 00, 01, 10, 11. Тремя битами можно закодировать восемь различных значений: 000, 001, 010, 011, 100, 101, 110, 111. Увеличивая на единицу количество разрядов в системе двоичного кодирования, увеличивают в два раза количество значений, которое может быть выражено в данной системе.
Бит — очень удобная, но очень маленькая единица для хранения и обработки информации в компьютере. Работать с каждым битом малопроизводительно. Поэтому в современных компьютерах осуществляется параллельная обработка нескольких битов одновременно. Один из первых персональных компьютеров мог параллельно обрабатывать 8 битов информации. Поэтому появилась новая единица измерения информации — байт, группа из восьми битов. С помощью одного байта можно выразить 256 (от 0 до 255) различных единиц информации.
Компьютеры работают с информацией по принципу — «разделяй и властвуй». Если это книга, то она делится на главы, разделы, абзацы, предложения, слова и буквы (символы). Компьютер отдельно работает с каждым символом. Если это рисунок, то компьютер работает с каждой точкой этого рисунка отдельно. До каких же пор можно делить информацию? Буква — это самая маленькая часть информации? Нет, так как существует много различных букв и для того, чтобы компьютер мог их различать буквы необходимо кодировать.
Любые закодированные данные существуют в виде последовательности байтов. Но обработка кодов чисел, текста, графики и т. д. совершенно разная (рис. 22). Поэтому необходимо перед последовательностью байтов размещать заголовок, т. е. хранимые данные должны иметь строго определенный формат.
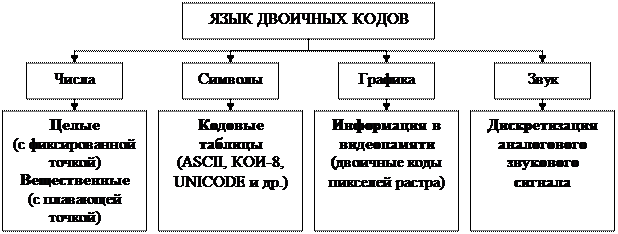
Рис. 22 Кодирование информации
Кодирование числовой информации
Все числовые данные хранятся в компьютере в двоичном виде, т. е. в виде последовательности нулей и единиц. Однако формы хранения целых и действительных чисел различны.
Целые числа хранятся в форме с фиксированной запятой (естественный вид), действительные (вещественные) числа хранятся в форме с плавающей запятой (в нормализованном виде).
В естественной форме число представляется целой и дробной частями.
В нормализованной форме число представляется в виде  , где
, где 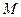 — мантисса числа,
— мантисса числа, 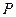 — основание системы счисления,
— основание системы счисления, 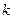 — порядок числа.
— порядок числа.
Необходимость различного представления целых и вещественных чисел вызвана тем, что скорость выполнения операций обработки над числами с плавающей запятой существенно ниже скорости выполнения этих же операций над числами с фиксированной запятой. Но в форме с фиксированной запятой диапазон чисел при заданной разрядности кода существенно меньше, чем в случае плавающей запятой. Существует большой класс задач, в которых не используются вещественные числа. Например, задачи экономического характера. Текстовые, графические и звуковые данные также кодируются с помощью целых чисел.
В современных технических средствах обработки информации (например, персональных компьютерах) процессоры выполняют операции только над целыми числами в форме с фиксированной запятой. Для выполнения операций над числами с плавающей запятой предусматриваются сопроцессор или заменяющие его специальные подпрограммы.
Для кодирования целых чисел от 0 до 255 достаточно одного байта двоичного кода. Двумя байтами двоичного кода можно закодировать числа от 0 до 65535. Соответственно для трех байтов двоичного кода (24 бит) — 16,5 миллионов различных значений.
Чтобы получить внутреннее представление целого положительного числа 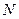 с фиксированной точкой, необходимо его перевести в двоичную систему счисления и и полученный результат дополнить слева незначащими нулями до заданного числа байт.
с фиксированной точкой, необходимо его перевести в двоичную систему счисления и и полученный результат дополнить слева незначащими нулями до заданного числа байт.
! Пример: Число 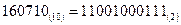 имеет внутреннее представление в машинном слове
имеет внутреннее представление в машинном слове 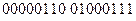 , а в двойном машинном слове —
, а в двойном машинном слове — 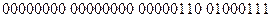 .
.
Двоичные разряды в машинном слове нумеруются от 0 до 15 справа налево, Старший 15-й разряд в машинном представлении является знаковым. Поэтому для положительного числа он всегда равен нулю. Максимальное число в такой форме равно 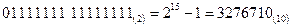 .
.
Для записи внутреннего представления целого отрицательного числа , необходимо получить внутреннее представление положительного числа 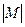 , получить обратный код этого числа заменой 0 на 1 и 1 на 0 и к полученному числу прибавить 1.
, получить обратный код этого числа заменой 0 на 1 и 1 на 0 и к полученному числу прибавить 1.
Описанный способ представления целого отрицательного числа называют дополнительным кодом. Старший разряд любого целого числа указывает на знак числа. Поэтому его называют знаковым.
Алгоритм получения дополнительного кода:
1. Дополнительный код положительного числа равен прямому коду этого числа.
2. В прямом коде отрицательного числа заменить все нули на единицы и все единицы на нули, исключая самую младшую единицу кода и следующие за ней нули.
! Пример: Число 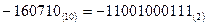 имеет внутренне представление в машинном слове (дополнительный код)
имеет внутренне представление в машинном слове (дополнительный код) 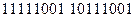 .
.
Применение дополнительного кода для внутреннего представления отрицательных чисел дает возможность заменить операцию вычитания операцией сложения с отрицательным числом.
Перевод в дополнительный код в средствах обработки информации — компьютерах происходит автоматически при вводе чисел. В таком виде числа хранятся в памяти и затем участвуют в операциях обработки.
При обработке данных возможен выход двоичных знаков за границу ячейки памяти, отведенной для хранения числа. Эта ситуация называется переполнением разрядной сетки. Для целых чисел такая ситуация не фиксируется, а для вещественных чисел она является аварийной — прерывание по переполнению.
Для кодирования действительных (вещественных) чисел может использоваться 80-ти разрядное (10 байт) кодирование. При этом число представляют в нормализованном виде, например, 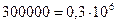 ,
, 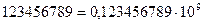 . Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы вместе со знаком, а некоторое фиксированное число разрядов отводят для хранения характеристики вместе со знаком.
. Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы вместе со знаком, а некоторое фиксированное число разрядов отводят для хранения характеристики вместе со знаком.
На математической числовой оси вещественные числа образуют непрерывное множество, т. е. два числа могут сколь угодно близко находиться друг к другу, и на любом отрезке находиться бесконечное множество значений чисел. В машинном же представлении количество возможных значений чисел конечно; для двоичной системы счисления оно определяется как 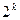 , где — количество двоичных разрядов в представлении мантиссы. Таким образом, в техническом устройстве непрерывный континуум вещественных чисел заменяется машинными кодами, образующими конечное дискретное множество — каждый код оказывается представителем целого интервала значений континуума (рис. 23).
, где — количество двоичных разрядов в представлении мантиссы. Таким образом, в техническом устройстве непрерывный континуум вещественных чисел заменяется машинными кодами, образующими конечное дискретное множество — каждый код оказывается представителем целого интервала значений континуума (рис. 23).

Рис. 23 Дискретное представление вещественных чисел в ЭВМ
Из данного обстоятельства следует, что строгие отношения между числами континуума превращаются в нестрогие для их компьютерных представителей, т. е.:
– если 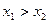 , то
, то 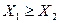 ;
;
– если 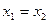 , то
, то 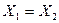 ;
;
– если 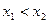 , то
, то 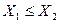 .
.
Поскольку код вещественного числа в компьютере является приблизительным представителем многих чисел из интервала, то и результаты вычислений также будут заведомо не точными, содержащими неизбежную погрешность — это главная особенность обработки вещественных чисел в компьютере — обработка всегда ведется с погрешностью. Некоторые числа компьютер просто не может отличить от нуля. Например, в типе Real языка PASСAL любое десятичное число, по модулю меньшее 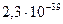 оказывается машинным нулем, т. е. считается равным нулю при сохранении и операциях с ним.
оказывается машинным нулем, т. е. считается равным нулю при сохранении и операциях с ним.
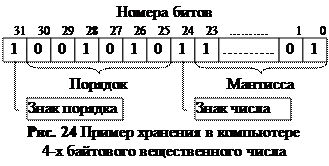 Записываться и храниться в памяти технического устройства должны все составляющие нормализованной формы числа (знак числа, мантисса, знак порядка, порядок), что требует нескольких ячеек памяти Например, на рис. 24 показано использование для хранения одного вещественного числа 4 байтов.
Записываться и храниться в памяти технического устройства должны все составляющие нормализованной формы числа (знак числа, мантисса, знак порядка, порядок), что требует нескольких ячеек памяти Например, на рис. 24 показано использование для хранения одного вещественного числа 4 байтов.
В ходе выполнения операций над вещественными числами отдельно обрабатываются мантиссы и порядки, при этом производится нормализация промежуточных данных и результата, состоящая в сдвиге мантиссы вправо или влево, с одновременным изменением порядка.
Различие правил работы с целыми и нормализованными числами приводит к необходимости точного описания типов переменных перед использованием их в программах обработки. В противном случае потребуется гораздо больший объем памяти для хранения целых чисел.
Кодирование символьной информации
С помощью двоичного кода можно кодировать и текстовую информацию, если каждому символу алфавита сопоставить определенное число. Разрядности одного байта достаточно для кодирования 256 различных символов. Этого вполне хватит, чтобы выразить различными байтами все символы английского и русского алфавитов, как строчные, так и прописные, а также знаки препинания, символы арифметических действий и некоторые специальные символы. Для стандартизации кодировки текстовой информации необходимы единые таблицы.
В настоящее время принята и действует следующая договоренность, в соответствии с которой таблицу кодов разделили на три части (ASCII таблица):
– символы с кодами от 0 до 31используются в качестве управляющих кодов производителями компьютеров;
– символы с кодами от 32 до 127 являются стандартной кодировкой ASCII, включающей коды символов английского алфавита, знаки препинания, цифры, знаки арифметических действий и некоторые вспомогательные символы;
– символы с кодами от 128 до 255 отданы для создания в каждой стране своего стандарта.
В России в настоящее время действуют несколько таблиц кодировки.
F Таблица кодировки — это стандарт, ставящий в соответствие каждому символу алфавита свой порядковый номер.
В однобайтных таблицах кодировки наименьшим номером символа является 0, а наибольшим — 255.
F Двоичный код символа — это его порядковый номер в двоичной системе счисления.
Таким образом, таблица кодировки устанавливает связь между внешними символьным алфавитом компьютера и внутренним двоичным представлением. Международным стандартом для персональных компьютеров стала первая половина кодовой таблицы ASCII, т. е. разряды с 0 по 127. Существуют следующие кодировки второй половины таблицы ASCII для России:
1. Кодировка Windows 1251 — введена для кодирования российского алфавита компанией Microsoft.
2. Кодировка КОИ-8 (код обмена информацией, восьмиразрядный) — используется в компьютерных сетях на территории России, в некоторых службах российского сектора Интернета, де-факто является стандартной в сообщениях электронной почты и телеконференций.
3. ISO (International Standard Organization — международный институт стандартизации). На практике данная кодировка используется редко.
4. Кодировка ГОСТ-альтернативная — используется на компьютерах, работающих в операционных системах MS-DOS.
В настоящее время осуществляется постепенный переход на универсальную систему кодирования текстовых данных — UNICODE. Такая система, основанная на 16-разрядном кодировании (65536 различных кодовых комбинаций), позволяет разместить в одной таблице символы большинства языков планеты.
Кодирование графической информации
В настоящее время существует два подхода к решению проблемы представления данных в графическом виде (в виде изображений) на технических устройствах обработки информации (компьютере): растровый и векторный. Суть обоих методов в декомпозиции, т. е. разбиении изображения на части, которые легко описать.
F Растровый подход предполагает разбиение изображения на маленькие одноцветные элементы — видеопиксели, которые, сливаясь, дают общую картину.
Черно-белое графическое изображение состоит из мельчайших точек, образующих растр. Линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, а значит использовать двоичный код для представления графических данных. Общепринятым сегодня считается представление черно-белых изображений в виде комбинаций точек с 256 градациями серого цвета, т. е. для кодирования яркости любой точки достаточно восьми разрядного двоичного числа (одного байта).
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие, т. е. информация в коде каждого пикселя должна содержать сведения о том, какую интенсивность (яркость) имеет каждая составляющая в его цвете. На практике считается, что любой цвет можно получить смешением трех основных цветов — красного (Red, R), зеленого (Green, G), синего (Blue, B). Система получила название — RGB. Чувствительность человеческого глаза более 16 миллионов различных цветов. Поэтому для кодирования цвета точки необходимо использовать три байта (24 разряда двоичного кода). При использовании дополнительных цветов — голубого (Cyan, C), пурпурного (Magenta, M) и желтого (Yellow, Y), которые дополняют до белого основные цвета — красный, зеленый и синий соответственно, можно значительно улучшить качество изображения. Такое кодирование называется полноцветным (True Color). При использовании для кодирования каждой цветовой точки двух байтового кода (16 бит) сокращается объем хранимых данных, но ухудшается цветовая гамма. Такой режим называют High Color.
Индексный режим кодирования цветовой информации использует один байт кода, которым определяется номер цвета (индекс) в соответствии с некоторой справочной таблицей цветов, называемой палитрой, которая хранится в памяти кодирующего устройства. В этом случае видеоинформация представляет собой перечисление в определенном порядке цветов этих элементов, т. е. в видеопамяти хранится совокупность кодов цветов каждого пикселя экрана.
Для хранения одного кадра (одной страницы) изображения дисплея с разрешающей способностью 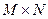 при разрядности кода цвета b минимально требуется
при разрядности кода цвета b минимально требуется 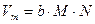 бит видеопамяти. Практически всегда в современных компьютерах в видеопамяти помещается одновременно несколько страниц изображения.
бит видеопамяти. Практически всегда в современных компьютерах в видеопамяти помещается одновременно несколько страниц изображения.
F При векторном подходе изображение рассматривается как совокупность простых элементов: прямых линий, дуг, окружностей, эллипсов, прямоугольников, закрасок и других, которые называются графическими примитивами.
Графическая информация в этом случае представляет собой данные, однозначно определяющие все графические примитивы, составляющие рисунок. Положение и форма графических примитивов задаются в системе графических координат, связанных с экраном. Например, отрезок прямой линии однозначно определяется указанием координат его концов; окружность — координатами центра и радиусом; многоугольник — координатами его углов; закрашенная область — граничной линией и цветом закраски и т. д. Для каждого элемента дополнительно указывается цвета линий, заливки и текста, тип и толщина линий, формат тени и другие эффекты.
Векторный формат изображения создается в результате использования графических редакторов векторного типа (например, CorelDraw), а растровые редакторы (например, Paint, Adobe Photoshop) образуют графические файлы растрового типа. Различие в представлении графической информации в растровом и векторном форматах существует лишь для программ их обработки и некоторых технических устройств. При выводе на экран монитора персонального компьютералюбого изображения, в видеопамяти формируется информация растрового типа, содержащая сведения о цвете каждого пикселя.
Кодирование звуковой информации
Современные компьютеры умеют сохранять и воспроизводить звук (речь, музыку и т. д.). Звук, как и любая другая информация, представляется в памяти ЭВМ в форме двоичного кода.
Основной принцип кодирования звука, как и кодирования изображения, выражается словом «дискретизация». При кодировании изображения дискретизация — это разбиение рисунка на конечное число одноцветных элементов — пикселей. Чем меньше эти элементы, тем меньше наше зрение замечает дискретность рисунка. Физическая природа звука — это колебания в определенном диапазоне частот, передаваемые звуковой волной через воздух (или другую упругую среду).
Процессы преобразования звуковых волн в двоичный код в памяти компьютера и его воспроизведение представлены на рис. 25.
F Аудиоадаптер (звуковая плата) — специальное устройство, подключаемое к компьютеру, предназначенное для преобразования электрических колебаний звуковой частоты в числовой двоичный код при вводе звука и для обратного преобразования (из числового кода в электрические колебания) при воспроизведении звука.
В процессе записи звука аудиоадаптер с определенным периодом измеряет амплитуду электрического тока и заносит в регистр двоичный код полученной величины. Затем полученный код из регистра переписывается в оперативную память компьютера. Качество компьютерного звука определяется характеристиками аудиоадаптера: частотой дискретизации и разрядностью.
F Частота дискретизации — это количество измерений входного сигнала за 1 секунду.
Частота измеряется в герцах (Гц). Одно измерение за 1 секунду соответствует частоте 1 Гц. 1000 измерений за 1 секунду — 1 килогерц (кГц). Характерные частоты дискретизации аудиоадаптеров: 11 кГц, 22 кГц, 44,1 кГц и др.
F Разрядность регистра — число бит в регистре аудиоадаптера.
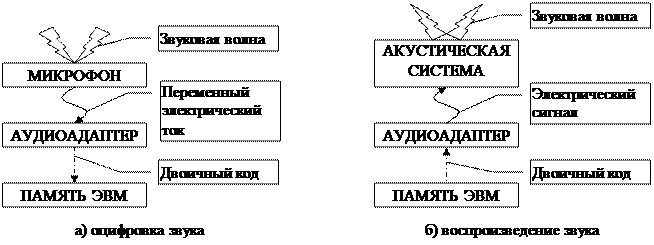
Рис. 25 Преобразование звуковых волн
Разрядность определяет точность измерения входного сигнала. Чем больше разрядность, тем меньше погрешность каждого отдельного преобразования величины электрического сигнала в число и обратно. Если разрядность равна 8 (16), то при измерении входного сигнала может быть получено 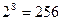 (
(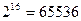 ) различных значений. Очевидно, 16-ти разрядный аудиоадаптер точнее кодирует и воспроизводит звук, чем 8-ми разрядный.
) различных значений. Очевидно, 16-ти разрядный аудиоадаптер точнее кодирует и воспроизводит звук, чем 8-ми разрядный.
F Звуковой файл — файл, хранящий звуковую информацию в числовой двоичной форме.
Размер памяти, необходимый для хранения звука без сжатия очень велик, он определяется для монофонического звучания путем произведение времени записи (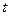 ) на частоту дискретизации (
) на частоту дискретизации (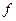 ) и разрядность регистра — разрешении (
) и разрядность регистра — разрешении (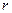 ):
): 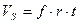 . Поэтому, очень часто, информация в звуковых файлах подвергается сжатию.
. Поэтому, очень часто, информация в звуковых файлах подвергается сжатию.
! Пример: Определить размер (в байтах) цифрового аудиофайла монофонического звучания, длительностью 10 секунд при частоте дискретизации 22,05 кГц и разрешении 8 бит. Файл сжатию не подвержен.
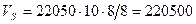 (байт).
(байт).
4.3 Передача данных
|
|
|
|
Дата добавления: 2014-01-07; Просмотров: 5862; Нарушение авторских прав?; Мы поможем в написании вашей работы!