КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Принятие решений в условиях неопределенности
|
|
|
|
Принятие решений при проведении эксперимента.
Допустим, что вероятности р(Q1), р(Q2), …, р(Qn) в принципе существуют, но вам неизвестны. Иногда в этом случае предполагают все состояния природы равновероятными (так называемый «принцип недостаточного основания» Лапласа), но вообще-то это делать не рекомендуется. Все-таки обычно более или менее ясно, какие состояния более, а какие - менее вероятны. Для того чтобы найти ориентировочные значения вероятностей р(Q1), р(Q2), …, р(Qn), можно, например, воспользоваться методом экспертных оценок. Хоть какие-то ориентировочные значения вероятностей состояния природы все же лучше, чем полная неизвестность. Неточные значения вероятностей состояний природы в дальнейшем могут быть «скорректированы» с помощью специально поставленного эксперимента. Эксперимент может быть как «идеальным», полностью выясняющим состояние природы, так и неидеальным, где, вероятности состояний уточняются по косвенным данным
Человек, прежде чем принять решение, пытается получить некоторую информацию о состоянии природы экспериментальным путем. Предполагается, что проведение эксперимента не требует никаких затрат,
Пусть проведен эксперимент, имеющий t исходов – возможных прогнозов состояния природы,
Z=(z1, z2,…, zt), 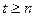 .
.
Известна условная вероятность Р(zβ/Qj) b-го результата эксперимента при состоянии природы Qj,
Pbj= Р(zβ/Qj), b=1,2,…,t, j=1,2,…,n. (7)
Множество значений Pbj можно представить в виде матрицы размера t·n, данной в табл. 5.
Для использования информации, полученной в результате эксперимента, введем понятие стратегии.
Таблица 5
| Qj Zb | Q1 | Q2 | … | Qn |
| z1 | P11 | P12 | … | P1n |
| z2 | P21 | P22 | … | P2n |
| … | … | … | … | … |
| zt | Pt1 | Pt2 | … | Ptn |
Стратегия - это соответствие последовательности t результатов эксперимента последовательности t операций,
(z1, z2,…, zt)→ (ai, aj,…, ak). (8)
Выражение (8) подразумевает, что
z1→ ai, 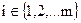 ,
,
z2→ aj, 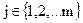 ,
,
……………………
zt→ ak, 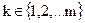 .
.
Число возможных стратегий l определяется формулой
l = mt,
m – число операций, t - число результатов эксперимента. При m=2, t=3 всевозможные стратегии представлены в табл.6.
Таблица 6
| Si zb | S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 |
| z1 | a1 | a1 | a1 | a1 | а2 | а2 | а2 | а2 |
| z2 | a1 | a1 | а2 | а2 | a1 | a1 | а2 | а2 |
| z3 | a1 | а2 | a1 | а2 | a1 | а2 | a1 | а2 |
Задача ПР формулируется так: какую одну из операций a1,a2,…, am следует выбрать в зависимости от одного из результатов эксперимента z1, z2,…, zt.
Для принятия решения находим усредненные полезности стратегий Si, i= 1,2, …, l, при состояниях природы Qj, j=1, 2, …, n,
U(Si,Qj)=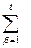 αi β j Pβ j, i= 1,2, …, l, j=1, 2, …, n, (9)
αi β j Pβ j, i= 1,2, …, l, j=1, 2, …, n, (9)
где αiβj - полезность β-ой компоненты i-ой стратегии при состоянии природы Qj, Pβj – условная вероятность β-го результата эксперимента при состоянии природы Qj. Стратегия Si определена множеством операций, значения αi β j берутся из таблицы полезностей значения Pβj – из табл. 5. Полученные значения усредненных полезностей U(Si,Qj) можно записать в виде матрицы размера n·l. Для принятия решения – выбора наилучшей стратегии можно воспользоваться уже рассмотренными критериями: максимина, минимакса сожалений и равновозможных состояний.
Рассмотрим конкретный пример. Предполагается лишь два состояния природы: Q1 - теплая погода, Q2 – холодная погода, и только две операции: a1 – одеться для теплой погоды, a2 – одеться для холодной погоды. Эта ситуация характерна для туристов. Матрица полезности дана в табл.7.
Таблица 7 Таблица 8
| Qj ai | Q1 | Q2 | Qj zb | Q1 | Q2 | |||||||
| a1 | z1 | 0.6 | 0.3 | |||||||||
| z2 | 0.2 | 0.5 | ||||||||||
| a2 | z3 | 0.2 | 0.2 | |||||||||
Критерий максимина гарантирует 4 ед. полезности и рекомендует выбирать операцию а2. Критерий минимакса дает этот же ответ.
Но есть возможность воспользоваться данными прогноза погоды (в этом и состоит эксперимент), которые могут быть трех видов:
z1 – ожидается теплая погода,
z2 – ожидается холодная погода,
z3 – прогноз неизвестен.
Из прошлого опыта известны условные вероятности этих трех видов прогноза для каждого состояния природы 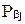 , b=1,2,3, j =1,2, представленные в табл. 8.
, b=1,2,3, j =1,2, представленные в табл. 8.
Для каждой из 8–ми стратегий и каждого из 2–х состояний природы определим взвешенные суммы полезностей по формуле (9), используя данные таблиц 6 – 8,
U(S1,Q1) =10×0.6 + 10×0.2 +10×0.2 =10,
U(S2,Q1) =10×0.6 + 10×0.2 +4×0.2 = 8.8,
U(S3,Q1) =10×0.6 + 4×0.2 + 10×0.2 = 8.8,
........................................................
U(S8,Q1) = 4×0.6 + 4×0.2 + 4×0.2 = 4,
U(S1,Q2) = 0×0.3 + 0×0.5 +0×0.2 = 0,
.........................................................
U(S8,Q2) = 7×0.3 + 7×0.5 + 7×0.2 = 7.
Все вычисленные значения U(Si,Qj), i = 1,2,…8, j = 1, 2, помещены в табл.9.
Таблица 9
 Si
Qj Si
Qj
| S1 | _ S2 | S3 | S4 | _ S5 | _ S6 | S7 | S8 |
| Q1 | 8.8 | 8.8 | 7.6 | 6.4 | 5.2 | 5.2 | ||
| Q2 | 1.4 | 4.9 | 2.1 | 5.6 |
Из табл. 9 предварительно следует исключить плохие стратегии –– те стратегии, обе компоненты которых не больше (£) соответствующих компонент какой–либо другой стратегии. Ввиду того, что 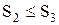 ,
, 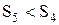 , S6 ≤ S7, то стратегии
, S6 ≤ S7, то стратегии 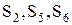 исключаются из рассмотрения (в табл. 9 они помечены знаком "–").
исключаются из рассмотрения (в табл. 9 они помечены знаком "–").
К оставшимся, допустимым стратегиям 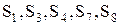 можно применить известные нам критерии. Используя критерий максимина, имеем:
можно применить известные нам критерии. Используя критерий максимина, имеем:
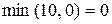 ,
,  ,
,
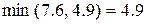 ,
, 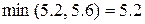 ,
, 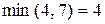 ,
,
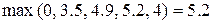 .
.
Следовательно, наилучшей стратегией является стратегия S7, гарантирующая 5.2 ед. полезности. Для сравнения максиминная операция 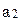 гарантирует лишь 4 ед. полезности. Так как S7 = (a2, a2, a1), то в силу (8) имеем
гарантирует лишь 4 ед. полезности. Так как S7 = (a2, a2, a1), то в силу (8) имеем
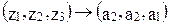 .
.
Это значит, что при прогнозе z1 выбирается операция а2, при прогнозе z2 – a2, при прогнозе z3 – a1, т.е. максиминная стратегия S7 рекомендует одеваться тепло, если прогноз – теплая или холодная погода, и одеваться легко, если прогноз неизвестен. Последнее утверждение весьма непрактично.
Максиминная стратегия S7 при неблагоприятном стечении обстоятельств может привести и к худшему результату, чем максиминная операция . Например, имеет место холодная погода 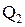 . Тогда согласно максиминной операции турист получит 7 ед. полезности (табл. 7). С другой стороны, если результат прогноза будет
. Тогда согласно максиминной операции турист получит 7 ед. полезности (табл. 7). С другой стороны, если результат прогноза будет 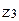 (прогноз неизвестен) и согласно стратегии S7 будет выбрана операция
(прогноз неизвестен) и согласно стратегии S7 будет выбрана операция 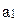 (одеться легко), то он получит 0 ед. полезности. Это явление –– типичное для теории игр и теории принятия решений. S7 гарантирует лишь среднюю полезность в 5.2 ед.
(одеться легко), то он получит 0 ед. полезности. Это явление –– типичное для теории игр и теории принятия решений. S7 гарантирует лишь среднюю полезность в 5.2 ед.
3.2. Использование смешанной стратегии
Стратегия S* называется смешанной, если она представлена в виде выпуклой комбинации двух других стратегий,
S* = сSm1 + (1 - с)Sm2, 0<с<1, m1, m2 Î {1, 2, …, t}.
Это определение базируется на понятии выпуклой комбинации точек [14]. Переход к смешанной стратегии осуществляется с целью повышения гарантированной средней полезности.
Стратегии рассмотренного выше примера изобразим точками на плоскости с координатами 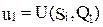 ,
, 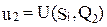 , i=1,3,4,7,8 (рис. 2).
, i=1,3,4,7,8 (рис. 2).
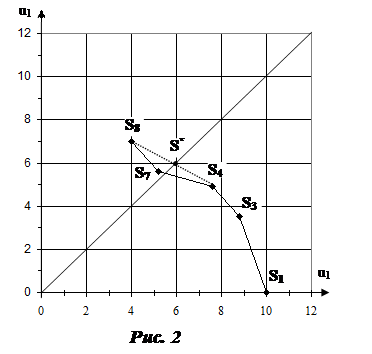 |
По рис. 2 видно, что если взять в определенных пропорциях стратегии S4 и S8, то получим смешанную стратегию, лучшую по сравнению со стратегией S7. Проведем биссектрису I-го координатного угла и найдем точку пересечения ее с отрезком [S4, S8] –– точку
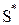 .
.
Запишем уравнение прямой, проходящей через точки S4(7.6; 4.9), S8 (4;7),
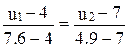 ,
,
которое приводится к виду:
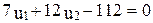 .
.
Из этого уравнения находим координаты точки , для которой 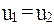 ,
,
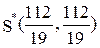 .
.
Так как 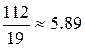 , то стратегия лучше стратегии S7, гарантирующей 5.2 ед. полезности, S*>S7. Теперь остается представить стратегию в виде выпуклой комбинации стратегий S4, S8,
, то стратегия лучше стратегии S7, гарантирующей 5.2 ед. полезности, S*>S7. Теперь остается представить стратегию в виде выпуклой комбинации стратегий S4, S8,
S* = cS4 + (1 – c)S8, 0 < c <1. (10)
Для определения значения параметра a достаточно записать уравнение (10) для абсцисс входящих в него точек,
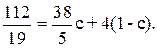
из которого получаем 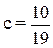 . Тогда равенство (10) принимает вид:
. Тогда равенство (10) принимает вид:
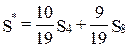 . (11)
. (11)
Так как 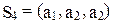 ,
, 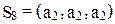 , то в силу равенства (11) имеем
, то в силу равенства (11) имеем
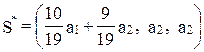 .
.
Практически смешанную стратегию S* можно реализовать так. Если результат эксперимента есть z2 или z3, то используется операция a2. Если же результат эксперимента есть z1, то с помощью подходящего случайного механизма с вероятностью 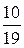 используется операция a1, и с вероятностью
используется операция a1, и с вероятностью 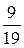 –– операция а2. Основой случайного механизма могут служить 19 одинаковых карточек, на 10–и из которых записан символ а1, а на 9–и –– символ а2. Из этого набора 19–и карточек случайно выбирается одна и используется та операция, символ, которой изображен на этой карточке.
–– операция а2. Основой случайного механизма могут служить 19 одинаковых карточек, на 10–и из которых записан символ а1, а на 9–и –– символ а2. Из этого набора 19–и карточек случайно выбирается одна и используется та операция, символ, которой изображен на этой карточке.
3.3. Принятие решений в условиях риска
К условиям, перечисленным в подпараграфе 3.1, добавляется еще одно – значения априорных вероятностей состояний окружающей среды (природы):
p(Q1), p(Q2),..., p(Qn). (12)
Тогда для каждой стратегии 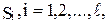 определяется усредненная по всем состояниям природы средняя полезность
определяется усредненная по всем состояниям природы средняя полезность 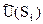 по формуле:
по формуле:
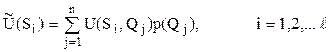 (13)
(13)
U(Si,Qj) – полезность стратегии 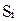 при состоянии природы
при состоянии природы 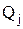 , которая находится по формуле (9). Затем из множества
, которая находится по формуле (9). Затем из множества 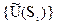 ,
, 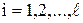 , выделяется максимальный элемент,
, выделяется максимальный элемент,
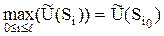 ,
, 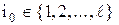 .Стратегия
.Стратегия 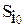 , обладающая максимальной средней полезностью
, обладающая максимальной средней полезностью 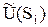 , называется байесовской стратегией,
, называется байесовской стратегией,
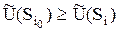 , .
, .
Пусть в рассмотренном ранее примере р(Q1) = 0.6, p(Q2) = 0.4. Используя данные табл. 9. и формулу (13), вычислим среднюю полезность для каждой допустимой стратегии,
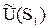 = 10×0.6 + 0×0.4 = 6,
= 10×0.6 + 0×0.4 = 6,
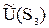 = 8.8×0.6 + 5×0.4 = 6.68,
= 8.8×0.6 + 5×0.4 = 6.68,
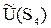 = 7.6×0.6 + 4.9×0.4 = 6.52,
= 7.6×0.6 + 4.9×0.4 = 6.52,
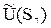 = 5.2×0.6 +5.6×0.4 =5.36,
= 5.2×0.6 +5.6×0.4 =5.36,
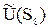 = 4×0.6 + 7×0.4 =5.2.
= 4×0.6 + 7×0.4 =5.2.
Затем найдем наибольшее число из полученных пяти чисел,
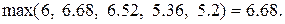
Следовательно, оптимальной стратегией является стратегия 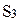 , обладающая максимальной средней полезностью, равной 6.68 ед.
, обладающая максимальной средней полезностью, равной 6.68 ед.
Заметим, что стратегия является байесовской для конкретных значений априорных вероятностей: р(Q1) = 0.6, p(Q2) = 0.4. При других значениях р(Q1), р(Q2) байесовской может быть и другая стратегия. Так, при р(Q1) = 0.5, p(Q2) = 0.5 байесовской является стратегия 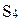 .
.
Проведение эксперимента в рассмотренной ситуации выгодно. Действительно, если эксперимент не проводить, то по данным табл.7 имеем:
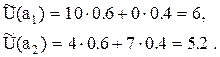
Байесовской операцией (стратегией) является операция а1, средняя полезность которой равна 6 ед.
Для дальнейших рассуждений нам понадобиться объединить выражения (13), (9) в одно,
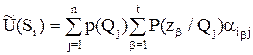 .
.
Меняя порядок суммирования в правой части последнего равенства, получим
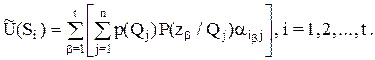 (14)
(14)
Из этого равенства следует, что при выборе оптимальной стратегии 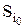 максимизация сводится к максимизации выражения в квадратных скобках в правой части (14), т.е. для каждого результата эксперимента zβ максимизация полезности Uβ(ai) сводится к выбору такой операции
максимизация сводится к максимизации выражения в квадратных скобках в правой части (14), т.е. для каждого результата эксперимента zβ максимизация полезности Uβ(ai) сводится к выбору такой операции 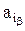 , которая максимизирует выражение в квадратных скобках.
, которая максимизирует выражение в квадратных скобках.
ЛИТЕРАТУРА.
1. Венцель Е.С. Исследование операций. Задачи, принципы, методология. - М: Наука, 1980.
2. Дегтярев Ю.П. Исследование операций. - М.: Высшая школа, 1986.
3. Корбут А.А., Финкелыптейн Ю.Ю. Дискретное программирование. -М.:Мир, 1978.
4. Кристофвдес Н. Теория графов. Алгоритмический подход. - М.: Мир, 1978.
5. Липский В. Комбинаторика для программистов. - М.: Мир, 1988.
6. Клейнрок Л. Теория массового обслуживания. - М.: Машиностроение, 1979.
7. Ивченко Г.И. и др. Теория массового обслуживания. - М. Высшая школа, 1982.
8. Шенок Р. Имитационное моделирование систем - искусство и наука.-М.: Мир, 1978.
9. Гудман С, Хидегниеми С. Введение в разработку и анализ алгоритмов. - М.: Мир, 1981.
10. Гмурман В.Е. Теория вероятностей и математическая статистика. Москва «Высшая школа» 1998.
|
|
|
|
Дата добавления: 2014-01-15; Просмотров: 365; Нарушение авторских прав?; Мы поможем в написании вашей работы!