КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Шкала порядка, шкала интервалов
|
|
|
|
В этом случае обычно данные представляют в сгруппированном виде, так как иначе образуется очень много классов. Например, мы исследуем возрастной состав той же группы из тридцати человек. Если она не однородна в этом отношении, данные окажутся «размазанными». Тогда мы их группируем, выбирая определенный шаг (обычно десять лет), и вносим в таблицу обобщенные данные. Шаг выбирается с учетом характера данных и задач анализа. Отметим, что группировка данных приводит к потере части информации. Но зато мы добиваемся ее лучшей обозримости. Таблица распределения, которая в результате получится, может выглядеть так:
Таблица 2. Данные о возрастном составе группы авторов
| Возрастная группа | Частоты | % | Накопленные частоты | Накопленные % |
| 20-29 | 40,0 | 40,0 | ||
| 30-39 | 26,7 | 66,7 | ||
| 40-49 | 16,7 | 83,4 | ||
| 50-59 | 9.9 | 93,3 | ||
| 60-69 | 6,7 | 100,0 | ||
| Всего | 100,1 | 100,0 |
В первом столбце представлены возрастные интервалы. Обратим внимание, что они не пересекаются, то есть мы берем интервалы 20 — 29, 30 — 39, а не 20 — 30, 30 — 40. Иначе неясно будет, куда относить индивидов, попадающих на стык возрастных групп. Во втором и третьем столбцах представлены соответственно частоты и проценты. Глядя на них, мы видим, что возрастной состав группы неоднородный: в ней преобладают молодые люди, а люди старших возрастов встречаются реже.
В четвертом и пятом столбцах частоты и проценты представлены в несколько иной форме, которая применима для упорядоченных категорий (шкал порядка или отношений). Частоты и проценты суммируются по всем предыдущим категориям. При такой форме представления данных хорошо видно, сколько человек или какая доля выборки находятся ниже (или выше) определенного уровня. В нашем примере 25 человек из 30, или 83,4 %, моложе пятидесяти лет.
2) Данные о распределении переменной представляем в форме графиков. Рассмотрим четыре типа графиков, которые чаще всего используются в случае одномерного распределения.
Для шкал наименований обычно применяют столбиковые диаграммы. Число столбиков соответствует числу категорий. Высота каждого столбика отражает частоту встречаемости данной категории. Все столбики рисуются одинаковой ширины и не соприкасаются друг с другом. Порядок их расположения на горизонтальной оси может быть любым. Для представления долей и процентов удобны круговые диаграммы. Весь круг соответствует единице или ста процентам, а величина каждого сектора отражает представительство соответствующей категории.
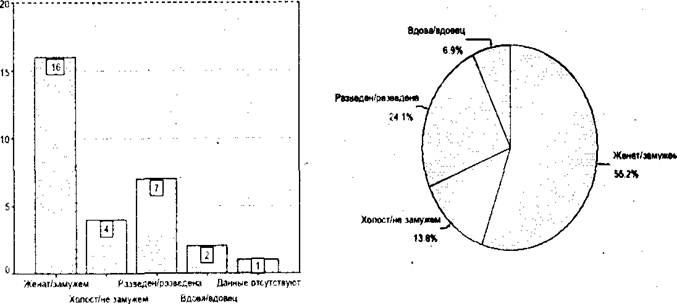
Рис. 1. Столбиковая диа- Рис. 2. Круговая диаграмма
грамма (Данные из Табл.1) (Данные из Табл. 1)

Для наглядного представления измеренных данных шкал равных интервалов используются так называемые гистограммы и полигоны. Гистограмма похожа на столбиковую диаграмму, только на горизонтальной оси в этом случае указываются границы интервалов. Столбики примыкают друг к другу. Высота столбика соответствует наблюдаемой частоте. Гистограмму легко преобразовать в полигон. Для этого середины вершин каждого столбца соединяются между собой прямыми отрезками. Получается ломаная линия, повторяющая контур, образуемый столбиками. Гистограмма удобна для изображения особенностей одного распределения. Преимущество полигона заключается в том, что на одном графике можно представить несколько полигонов и затем сравнивать между собой разные выборки.
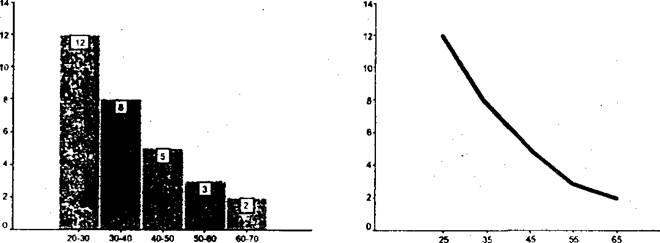
Возрастные группы Возрастные группы
Рис. 3. ГистограммаРис. 4. Полигон
3) Оценка параметров распределения.
Построение таблиц и графиков — это первый шаг статистического анализа. Следующим шагом является оценка параметров распределения. Вычисляются показатели, которые позволяют дать еще более сжатое описание наблюдаемых значений.
Эти показатели распадаются на две основные группы: 1) меры центральной тенденции;
2) меры рассеяния.
1) Меры центральной тенденции. Ониуказывают на расположение среднего, или типичного, значения признака, вокруг которого сгруппированы остальные наблюдения. Понятие среднего, центрального, значения в статистике, как и в повседневной жизни, подразумевает нечто «ожидаемое», «обычное», «типичное». Наиболее часто используют так называемое среднее (арифметическое). Вычисляют его, как известно, путем суммирования значений всех наблюдений и деления полученной суммы на общее число наблюдений. Для числовой шкалы:

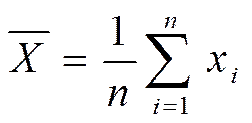
то есть
где X1…Xi – наблюдаемые значения, n – число наблюдений.
В случае сгруппированных данных (шкала интервалов) поступают следующим образом: находят середину каждого интервала, это значение умножают на частоту, полученные величины складывают и делят на общее число наблюдений. Рассматриваемый показатель характеризует область распределения, в которой концентрируются наиболее типичные представители изучаемой выборки. Но это справедливо лишь для тех случаев, когда распределение близко к нормальному. При таком распределении основная масса значений концентрируется в его средней части, а любые отклонения встречаются тем реже, чем дальше они отстоят от центра. Например, распределение такого признака, как рост человека, в целом близко к нормальному: больше всего людей среднего роста, а очень высокие и очень маленькие попадаются довольно редко. Средняя величина удобна для сравнения двух выборок или двух популяций. Так, мы говорим, что мужчины в среднем выше женщин, и это утверждение вполне справедливо несмотря на то, что встречаются высокие женщины, рост которых значительно превышает среднестатистический. Или, например, известно, что средний рост мужчины-пигмея меньше роста средней европейской женщины.
Две другие меры центральной тенденции — это мода (Мо) и медиана (Мd). В качестве моды берется значение, которое чаще всего встречается в распределении. Моду специально вычислять не надо. Достаточно сгруппировать данные и выбрать тот класс, в который попадает больше всего наблюдений. В разобранном выше примере (Табл. 1) лучше всего представлена категория семейных людей. Это и есть мода для данной выборки. Встречаются распределения, имеющие не одну, а две моды. Распределение такого типа называется бимодальным. На графике в этом случае мы увидим две вершины. Чаще всего это указывает на то, что выборка является неоднородной: в ней присутствуют два типа объектов. Констатация такого факта обычно наводит нас на мысль разбить всю выборку на две подгруппы и рассмотреть их отдельно.
Медиана (Md) — это значение, которое делит упорядоченное множество данных пополам, так что одна половина наблюдений оказывается меньше медианы, а другая — больше. Иными словами, медиана — это 50-й процентиль распределения. Как мы уже видели, при работе с большим массивом данных удобнее всего искать медиану, построив на основании частотного распределения распределение накопленных частот (или построив распределение накопленных процентов на основании распределения процентов). Если число значений в группе наблюдений четное, то медианой будет среднее двух центральных значений.
Когда распределение имеет нормальный вид (то есть оно симметрично), его среднее арифметическое значение и медиана совпадают. Когда же распределение асимметрично (скошено), медиана лучше схватывает его центральную тенденцию. Выбор подходящей меры центральной тенденции определяется как характером распределения, так и характером используемых данных.
Качественные данные (шкала наименований) допускают использование только моды. Для ранжированных данных (шкала порядка) допустимо использование и моды, и медианы. Количественные данные (шкала равных интервалов) можно описывать любым из трех показателей, хотя на практике чаще всего в этом случае вычисляют среднее арифметическое значение. Именно этот показатель вместе с показателем рассеяния участвует в расчете целого ряда других статистических показателей.
|
|
|
|
Дата добавления: 2014-01-15; Просмотров: 1581; Нарушение авторских прав?; Мы поможем в написании вашей работы!