КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Размах, дисперсия S2, стандартное отклонение Sx
|
|
|
|
Меры рассеяния.
Показатели рассеяния характеризуют степень разброса данных вокруг некоторого среднего значения. Мы говорим о значительном рассеянии тогда, когда многие значения сильно отклоняются от воображаемого центра распределения. Специалисты по математической статистике говорят, что в этом случае данные «размазаны». Про распределение, характеризующееся малым разбросом, говорят, пользуясь аналогией из области стрельбы, что данные ложатся «кучно». Понятно, что в первом случае среднее значение оказывается более информативным показателем, чем во втором случае, то есть оно лучше описывает выборку в целом.
Например, в кордебалет идет строгий отбор танцовщиц по росту. В результате рассеяние показателей роста в этой группе людей значительно меньше, чем по популяции в целом. Зная средний рост балерины, можно быть уверенным, что реальный рост любой балерины будет очень близок к нему.
Как оценить степень рассеяния значений переменной? Здесь тоже существуют разные способы, выбор которых в каждом конкретном случае определяется характером данных — их типом и распределением.
Некоторое представление о рассеянии мы получаем, когда рассматриваем крайние члены распределения. Расстояние между ними называется размахом.
Например, в разобранном выше примере (Табл. 2) выборка включает индивидов, чей возраст колеблется в пределах от двадцати до семидесяти лет. Общий размах составляет пятьдесят лет. Большинство людей (40 %) моложе тридцати лет. Но в выборку попали два человека, которым уже за шестьдесят. Если мы вычислим показатель центральной тенденции по формуле среднего арифметического, то получим значение 36,5.
|
|
|
Для более точной оценки рассеяния в случае измерений по шкале равных интервалов используется показатель, называемый дисперсия. В этом случае учитывается отклонение каждого индивидуального значения от среднего в одну или в другую сторону. Нас интересует сумма таких отклонений. Но в случае симметричного распределения эта сумма всегда обращается в нуль, поскольку положительные и отрицательные отклонения взаимно гасятся. Сумма квадратов отклонений от среднего, деленная на количество наблюдений дает значение дисперсии.
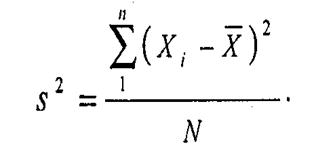
Если извлечь из дисперсии квадратный корень, то мы получим еще одну меру рассеяния — стандартное отклонение (Sx), которое также называют среднеквадратическим отклонением. Удобство этого показателя в том, что он выражается в тех же единицах, что и сами измеренные величины:
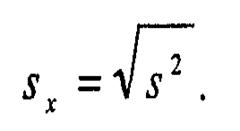
Рассмотренный показатель очень удобен, когда форма распределения близка к той, которая называется нормальным распределением.
Мы уже упоминали этот термин. Сейчас поясним, что он означает. Нормальное распределение — это такое распределение непрерывного признака, которое симметрично относительно среднего значения и если откладывать его значения на графике, то кривая имеет вид колокола. Рост человека оказывается одним из признаков, обнаруживающих распределение, хорошо описываемое нормальной кривой. Если мы измеряем рост многих людей, например — призывников в армию, а затем на основе этих данных строим график, то мы получаем нормальную кривую. С точки зрения анализа данных нормальное распределение привлекательно тем, что его можно исчерпывающе описать через два параметра — значение среднего и стандартного отклонения (дисперсии). Вместо тысяч значений — всего два числа. Чрезвычайно эффективный метод сжатия информации.
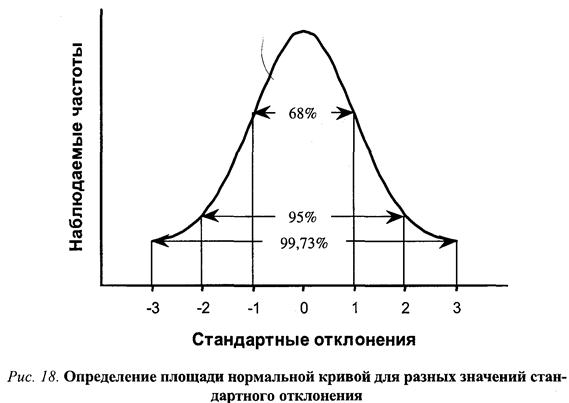
Стандартное отклонение действительно позволяет четко задавать критерии для выявления статистической нормы. Это возможно благодаря тому, что свойства нормального распределения хорошо известны и достаточно просто описываются. Так, известно, что в диапазоне одного стандартного отклонения в обе стороны от среднего оказывается примерно 68 % всех наблюдений, а если взять два стандартных отклонения, то этот участок распределения покроет около 95 % всех случаев. Значит, за этот диапазон выходит всего 5% возможных наблюдений.
|
|
|
Используя свойства нормального распределения, можно ввести строгие количественные критерии, определяющие, что такое «нормальный вес», «нормальная острота зрения» и т. д. Психологические тесты тоже создаются с опорой на эти статистические закономерности. Нормы для оценки результатов испытаний выводят эмпирически с использованием аппарата математической статистики, т.е. трудность заданий подбирается таким образом, чтобы распределение результатов решения тестовых задач (число правильных ответов) описывалось нормальным законом. А затем строится шкала, где среднему значению соответствует сто баллов, а стандартное отклонение равно пятнадцати баллам. Также построен известный показатель - коэффициент интеллектуального развития (по-английски — intelligence quotient, или сокращенно IQ). Человек, у которого этот показатель ниже 70, считается умственно отсталым, а человека с показателем выше 130 относят к категории особо умственно одаренных.
Мы подробно разобрали случай, когда анализируется характер распределения одной переменной. Эти приемы очень важны, поскольку на них основаны все другие виды статистического анализа.
2. ДВУМЕРНЫЙ АНАЛИЗ данных
Теперь мы можем перейти к более сложному виду анализа, каким является двумерный анализ. Здесь рассматривается связь между двумя переменными. Мы имеем пары наблюдений, полученные на одном объекте. Это могут быть, например, результаты по двум тестам. Нас интересует, как один изучаемый признак связан с другим.
Таблица 3. Взаимосвязь между видом СМИ и характером суждений
| Суждение | Вид СМИ | Всего | |
| Газета «Московский комсомолец» | Экспертный журнал | ||
| 1. Рациональное (причины, анализ) | 50 (19,6) | 200 (81,6) | |
| 2.Оценочное (эмоционально-нравственное) | 205 (80,4) | 45 (18,4) | |
| 255 (100) | 245 (100) |
В таблице 3 два столбца (для образования) и две строки, следовательно, размерность этой таблицы 2х2. Кроме того, имеются дополнительные крайний столбец и крайняя строка (маргиналы таблицы), указывающие общее количество наблюдений в данной строке или в столбце. В правом нижнем углу указана общая сумма, т. е. общее число наблюдений в выборке.
|
|
|
Обычно характер взаимоотношений между переменными в небольшой таблице можно определить даже «на глазок», сравнивая числа в столбцах или строках. Еще легче это сделать, если вместо абсолютных значений стоят проценты. Чтобы перевести абсолютные частоты, указанные в клетках таблицы, в проценты, нужно разделить их на маргинальные частоты и умножить на 100. Если делить на маргинал столбца, мы получим процент по столбцу.
Например, 50/255х100 = 19,6%, т. е. 19,6% газет МК имеют рациональные суждения. Если делить на маргинал строки, то мы получим другую величину - процент по строке.
Элементарная таблица сопряженности размерности 2х2 - это минимально необходимое условие для вывода о наличии взаимосвязи двух переменных.
3) Строится диаграмма распределения.
Между переменными могут существовать различные зависимости: линейные, нелинейные.
Между переменными Х и Y существует линейное отношение: если одна переменная возрастает по величине, то это же происходит и с другой. Очевидно, что чем более компактно, «скученно» располагаются точки-наблюдения вокруг пунктирной прямой линии (описывающей идеальное линейное отношение Х и Y), тем сильнее зависимость. На рисунке 22 приведены три диаграммы рассеивания.
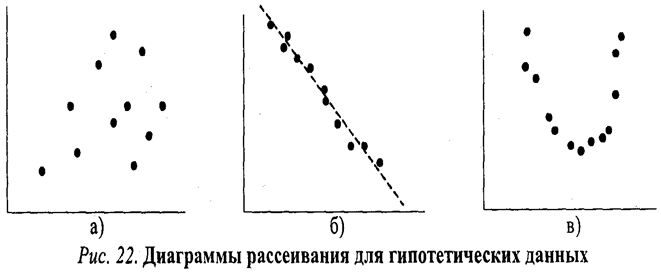
Очевидно, что на рисунке 22а какая-либо связь между x и y попросту отсутствует. На рисунке 22б воображаемая прямая линия (отмечена пунктиром) пересекла бы диаграмму сверху вниз, из левого верхнего в правый нижний угол. Иными словами, линейная связь в этом случае имеет обратное направление: чем больше X, тем меньше зависимая переменная У.
Заметим также, что «кучность» расположения точек вдоль воображаемой прямой на рисунке 22б не очень велика, а значит и связь (корреляция) между переменными не только обратная, отрицательная, но еще и не очень сильная, умеренная.
|
|
|
Наконец, на рисунке 22в зависимую и независимую переменную связывает явно нелинейное отношение: воображаемый график нисколько не похож на прямую линию и напоминает скорее параболу.
Методы анализа, о которых сейчас пойдет речь, не годятся для этого нелинейного случая, так как обычная формула для подсчета коэффициента корреляции даст нулевое значение, хотя связь между переменными существует.
Существует обобщенный показатель, позволяющий оценить, насколько связь между переменными приближается к линейному функциональному отношению, которое на диаграмме рассеивания выглядит как прямая линия. Это коэффициент корреляции, измеряющий тесноту связи между переменными, т. е. их тенденцию изменяться совместно.
Само слово «корреляция» как раз и означает «взаимосвязь». Какого типа отношения возможны между двумя переменными? Ну, во-первых, признаки могут быть совершенно независимыми друг от друга. Тогда изменения одного никак не связаны с изменением другого. Мы говорим, что переменные не коррелированны между собой. Если признаки связаны, то сама связь может быть прямой или обратной.
В первом случае большим значениям одного признака соответствуют более высокие значения другого и наоборот.
Во втором случае увеличение первого признака сопровождается уменьшением второго, а уменьшение первого — увеличением второго.
Статистики говорят о положительной и отрицательной корреляции. Наконец, степень связи тоже может варьироваться от максимума, когда значения одного признака позволяют уверенно предсказывать значения другого, до ее полного отсутствия. Коэффициент корреляции отражает всю гамму возможных отношений. Его значение может варьироваться от +1 до — 1. Положительные значения указывают на прямую связь между переменными, отрицательные — на обратную. Нуль соответствует случаю отсутствия корреляции.
Пример. Предположим, что у многих людей измеряют рост и вес тела. Каждый человек описывается двумя показателями, и в результате образуются два ряда измерений. Сравнивая между собой пары измерений, мы стремимся выявить характер связи между переменными. Между ростом и весом тела существует довольно высокая положительная корреляция. Это значит, что высокий человек, как правило, весит больше, чем человек меньшего роста. Связь эта не однозначная: высокий человек может быть очень худым, а человек невысокого роста может быть очень полным. Поэтому значение коэффициента корреляции в данном случае находится где-то между 0 и +1, видимо, чуть ближе к единице.
Коэффициент корреляции по-разному вычисляется для измеренных показателей (рост, вес) и для ранжированных данных (оценки, предпочтения). Но его окончательная форма и интерпретация остаются теми же. Если данные носят качественный характер (мужчина — женщина, совершеннолетний — несовершеннолетний, работающий — пенсионер), то вместо коэффициента корреляции применяются другие меры связи, основанные на сравнении частот. Для тех случаев, когда два ряда получены с помощью разных шкал, имеются свои вычислительные процедуры. Но общая логика анализа сохраняется.
Социальные науки чаще всего имеют дело с явлениями, которые отличаются множественной детерминацией и контекстуальным характером. Поэтому необходима особая тщательность в интерпретации наблюдаемых фактов.
|
|
|
|
Дата добавления: 2014-01-15; Просмотров: 4863; Нарушение авторских прав?; Мы поможем в написании вашей работы!