КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция 6. Временные ряды: их анализ
|
|
|
|
Эконометрические модели, характеризующие протекание процесса во времени или состояние одного объекта в последовательные моменты времени (или периоды времени) представляют модели временных рядов. Временным рядом называется последовательность значений признака, принимаемых в течение нескольких последовательных моментов времени или периодов. Эти значения называются уровнями ряда. Между уровнями временного ряда, или (что, то же) ряда динамики может иметься зависимость. В этом случае значения каждого последующего уровня ряда зависят от предыдущих. Подобную корреляционную зависимость между последовательными уровнями ряда динамики называют автокорреляцией уровней ряда.
Количественное измерение корреляции осуществляется посредством использования линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько (1 или более) шагов во времени, получаемого из общей формулы линейного коэффициента корреляции для двух случайных величин у и х
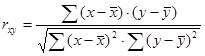 , (6.1)
, (6.1)
Эта общая формула приводит к удобной расчетной формуле в применении к исходному временному ряду и его сдвигу во времени:
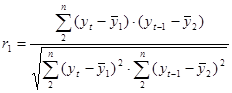 (6.2)
(6.2)
Это коэффициент автокорреляции уровней ряда первого порядка – он измеряет зависимость между соседними уровнями ряда, или при лаге 1. В формуле (6.2) индексы 1 и 2 внизу справа для средних от у показывают, что это соответственно средние для исходного и для сдвинутого рядов. Не забывайте, что у сдвинутого ряда на одно значение меньше, чем у исходного (естественно он имеет меньшее на 1 число членов) и следовательно среднее берется для этих рядов по этому меньшему числу членов. Первое значениие исходного ряда опускается и в свою сумму при вычислении среднего не входит!
2. Аналогично определяется коэффициент автокорреляции второго, третьего и более высокого порядков. (6.1)
Соответствующая расчетная формула собственно для временного ряда из этой общей формулы получается простой заменой (для коэффициента автокорреляции первого порядка) величины х на величину у, сдвинутую на 1 шаг по времени.
Если сдвиг во времени составляет всего один шаг, то соответствующий коэффициент корреляции называется коэффициентом автокорреляции уровней ряда первого порядка. При этом лаг равен 1. Измеряется же при этом зависимость между соседними уровнями ряда. В общем случае число шагов (или циклов), на которые осуществляется сдвиг, характеризующий влияние запаздывания, также называется лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции (в общем случае уменьшается), но при этом его поведение все же существенно зависит от структуры исходного ряда. В частности, при сильной сезонной зависимости и не очень заметном линейном тренде коэффициенты автокорреляции высших порядков, особенно четвертого, могут заметно превышать таковой первого порядка!
Динамика уровней ряда может иметь основную тенденцию (тренд). Это весьма характерно для экономических показателей. Тренд является результатом совместного длительного действия множества, как правило, разнонаправленных факторов на динамику исследуемого показателя. Далее довольно часто динамика уровней ряда подвержена циклическим колебаниям, которые зачастую носят сезонный характер. Иногда не удается выявить тренд и циклическую компоненту. Правда, нередко в этих случаях каждый следующий уровень ряда образуется как сумма среднего уровня ряда и некоторой случайной компоненты.
В очень многих случаях уровень временного ряда представляется в виде суммы тренда, циклической и случайной компоненты или в виде произведения этих компонент. В первом случае это аддитивная модель временного ряда. Во втором случае – мультипликативная модель. Исследование временного ряда заключается в выявлении и придании количественного выражения каждой из этих компонент. После чего удается использовать соответствующие выражения для прогнозирования будущих значений ряда. Можно также решать задачу построения модели взаимосвязи двух или нескольких временных рядов.
Для выявления трендовой, циклической компоненты можно использовать коэффициент автокорреляции уровней ряда и автокорреляционную функцию. Автокорреляционная функция это последовательность коэффициентов автокорреляции уровней первого, второго и т.д. Соответственно график зависимости значений автокорреляционной функции от величины лага (порядка коэффициента автокорреляции) - коррелограмма. Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а следовательно, и лаг, при котором связь между текущим и предыдущими уровнями ряда наиболее тесная.
Прежде чем пояснить это отметим: коэффициент автокорреляции характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Если ряд имеет сильную нелинейную тенденцию коэффициент автокорреляции может приближаться к нулю. Знак его не может служить указанием на наличие возрастающей или убывающей тенденции в уровнях ряда.
Теперь об анализе структуры временного ряда с помощью автокорреляционной функции и коррелограммы. Довольно ясно, что, если наиболее высоким оказался коэффициент автокорреляции первого порядка, то исследуемый ряд содержит основную тенденцию, или тренд и скорее всего только ее. Если ситуация иная, когда наиболее высоким оказался коэффициент корреляции некоторого отличного от единицы порядка к, то ряд содержит циклические компоненты (циклические колебания) с периодом к моментов времени. Наконец, если ни один из коэффициентов корреляции не является значимым, то достаточно правдоподобными являются следующие две гипотезы. Либо ряд не содержит ни тренда, ни циклических компонентов, так что его структура носит флуктуацинный (резко случайный) характер. Возможно также, что имеется сильная нелинейная тенденция, обнаружение которой требует дополнительных специальных исследований.
Автокорреляция связана с нарушением третьего условия Гаусса-Маркова, что значение случайного члена (случайного компонента, или остатка) в любом наблюдении определяется независимо от его значений во всех других наблюдениях. Для экономических моделей характерна постоянная направленность воздействия не включенных в уравнение регрессии переменных, являющихся наиболее частой причиной положительной автокорреляции. Случайный член в регрессионной зависимости подвергается воздействию переменных, влияющих на зависимую переменную, которые не включены в уравнение регрессии. Если значение случайного компонента в любом наблюдении должно быть независимым от его значения в предыдущем наблюдении, то и значение любой переменной, “скрытой” в случайном компоненте, должно быть некоррелированным с ее значением в предыдущем наблюдении.
Попытки вычисления коэффициентов корреляции различных порядков и тем самым формирования автокорреляционной функции являются так сказать непосредственным выявлением корреляционной зависимости, которое иногда приводит к вполне удовлетворительным результатам. Имеются специальные процедуры оценивания неизвестного параметра r в выражении линейной зависимости, представляющем рекуррентное соотношение, связывающее значения случайных компонентов в текущем и в предыдущем наблюдении (коэффициент авторегрессии).
Тем не менее, необходимо иметь также и особые тесты на наличие или отсутствие корреляции по времени. В большинстве из таких тестов используется такая идея: если имеется корреляция у случайных компонентов, то она присутствует также и в остатках, получаемых после применения к модели (уравнениям) обычного МНК. Не станем здесь вдаваться в подробности реализации этой идеи. Они не очень сложны, но связаны с громоздкими алгебраическими преобразованиями. Важнее иметь в виду следующее. Как правило, все или почти все они связаны с проверкой двух альтернативных статистических гипотез. Нулевая гипотеза – отсутствие корреляции (r=0). Альтернативная гипотеза либо просто состоит в том, что несправедлива гипотеза нулевая, т.е. r¹0. Либо так называемая односторонняя, более точная r>0. Независимо от вида второй (альтернативной) гипотезы соответствующее распределение (используемое в критерии) зависит не только от числа наблюдений и количества регрессоров (объясняющих переменных), но и от всей матрицы коэффициентов при неизвестных в уравнениях системы.
Понятно, что невозможно составить таблицу критических значений для всех матриц, так что приходится использовать обходные способы применения таких тестов. В тесте Дарбина-Уотсона используются для этого верхняя и нижняя (две) границы, которые уже зависят только от количества наблюдений, регрессоров и уровня значимости – таким образом, их уже можно затабулировать (составить для них таблицы). Правда, применение их (границ) далеко не всегда просто! Все ясно, когда соответствующая статистика (эмпирическое, или рассчитанное распределение) Дарбина-Уотсона меньше нижней границы, то отвергается нулевая гипотеза и принимается альтернативная гипотеза. Если же тест больше верхней границы, то принимается первая (нулевая) гипотеза. Но если тест попадает между этими границами, ситуация становится неопределенной: непонятно как выбрать одну из двух гипотез. К сожалению, ширина этой неопределенной зоны вполне может быть довольно широкой. Естественно, что поэтому пытались и небезуспешно построить тесты, сужающие такую зону неопределенности.
Вернемся теперь к проблеме выявления основной зависимости. Для этого существуют различные методы. Это могут быть качественные методы и качественный анализ исследуемых временных рядов. В том числе построение и визуальный анализ графика зависимости уровней ряда от времени. Это могут быть методы сопоставления двух параллельных рядов и методы укрупнения интервалов. Поскольку они носят достаточно качественный характер, суть их понятна из названия, и, к тому же, они приводятся в курсах статистики, не станем более говорить о них.
Несколько более гибок и опирается на количественные (аналитические) инструменты анализа метод скользящей средней, или скользящего окна. В нем последовательно рассчитываются вместо одного “полного” среднего для всех наблюдений ряд так называемых частных средних для трех, пяти или более наблюдений, номера которых постоянно сдвигаются вправо (в сторону увеличения). Таким образом, получается последовательность частных средних, которая отсеивает несущественные флуктуации и способна легче обнаружить тренд, чем данные исходного ряда.
Очевидно также, что при описанном выше использовании коэффициентов автокорреляции уровней ряда для выявления тренда используется сравнение коэффициентов автокорреляции первого порядка, рассчитанных по исходным и преобразованным уровням ряда. Совсем очевидно, что при наличии линейного тренда соседние уровни ряда тесно коррелируют. Для нелинейного тренда дело обстоит сложнее, но нередко может быть упрощено сведением к линейному случаю соответствующим преобразованием переменных.
Основным способом моделирования и изучения, таким образом, основной тенденции временного ряда (ряда динамики) является аналитическое выравнивание временного ряда. При этом строится аналитическая функция, характеризующая зависимость уровней ряда динамики от времени. Эта функция называется также трендом. Сам такой способ выявления основной тенденции называется аналитическим выравниванием. В конце предыдущей лекции описаны различные способы определения типа тренда. В целом построение модели тренда включает следующие основные этапы:
1. выравнивание исходного ряда методом скользящей средней;
2. расчет сезонной компоненты;
3. устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных в модели;
4. аналитическое выравнивание уровней и расчет значений тренда с использованием полученного уравнения тренда;
5. расчет полученных по модели значений, генерируемых трендом и сезонной компонентой;
6. расчет абсолютных и относительных ошибок.
В качестве основной тенденции выдвигается гипотеза о некоторой аналитической функции, выражающей данную зависимость. Но ведь требуется еще определить коэффициенты (параметры) данной зависимости. Для определения (оценивания) параметров тренда используется обычный МНК. Критерием отбора наилучшей формы тренда является наибольшее значение скорректированного коэффициента детерминации.
Для устранения тренда применяют метод отклонений от тренда, в ходе которого вычисляются значения тренда для каждого ряда динамики модели и отклонения от тренда. Далее для последующего анализа уже применяют не исходные данные, а отклонения от тренда.
Другой метод устранения тренда это метод последовательных разностей. Если тренд линейный, то исходные данные заменяются первыми разностями, которые в этом случае равны просто коэффициенту регрессии b сложенному с разностью соответствующих случайных компонент. Если тренд параболический, то исходные данные заменяются вторыми разностями. В случае экспоненциального и степенного тренда метод последовательных разностей применяется к логарифмам исходных данных. Не следует упускать из виду и уже обсуждавшуюся выше автокорреляцию в остатках. Для выявления автокорреляции остатков используется критерий Дарбина-Уотсона.
Рассматриваются также и эконометрические модели, содержащие не только текущие, но и лаговые (учитывающие запаздывание) значения факторных переменных. Эти модели так и называются модели с распределенным лагом. Если максимальная величина лага конечна, то для такой модели зависимость имеет довольно простой вид. Это просто сумма свободного члена и произведений коэффициентов (регрессии) на факторные переменные (в текущий момент, в предшествующий момент соответственно, в предпредшствующий момент и т.д.). Естественно, имеется еще и случайный член. Последовательные суммы соответствующих коэффициентов при значениях факторов в различные моменты времени называются промежуточными мультипликаторами. Для максимального лага воздействие фактора на результативное переменное описывается полной суммой соответствующих коэффициентов, которая и называется долгосрочным мультипликатором. После деления этих коэффициентов на долгосрочный мультипликатор получаются относительные коэффициенты модели с распределенным лагом. По формуле средней арифметической взвешенной получают величину среднего лага модели множественной регрессии. Эта величина представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора в момент t. Имеется также медианный лаг - период, в течение которого с момента времени t будет реализована половина общего воздействия фактора на результат.
Во многих практически интересных ситуациях выявление тренда (при всей важности этого) вовсе не является завершением исследования структуры ряда и требуется по крайней мере обнаружение и изучение еще циклической (сезонной) составляющей. Проще всего для решения подобных задач использовать метод скользящей средней. Далее построить аддитивную или мультипликативную модель временного ряда. Если амплитуда сезонных колебаний (или циклических колебаний) приблизительно постоянна, то строят аддитивную модель временного ряда, в котором (этом временном ряде) значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается, то строят мультипликативную модель. В мультипликативной модели уровни ряда зависят от значений сезонной компоненты.
В остальном схема во многом аналогична уже приводившейся выше с очевидными модификациями. Именно процесс построения модели включает следующие шаги:
1. выравнивание исходного ряда методом скользящей средней,
2. расчет значений сезонной компоненты,
3. устранение сезонной компоненты из исходных уровней.
После этого наступает очередь шагов второго уровня:
4. получение выровненных данных в аддитивной или мультипликативной модели соответственно,
5. затем выполняется уже аналитическое выравнивание этих один раз уже выровненных уровней суперпозиции компонент тренда и циклической и расчет значений тренда в этой усовершенствованной модели с использованием полученного уравнения тренда,
6. наконец, расчет уже по этой модели значений суперпозиции тренда и циклической компоненты и расчет абсолютных и относительных ошибок.
Если полученные значения ошибок не содержат автокорреляции, то ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок для анализа взаимосвязи исходного ряда и других временных рядов.
Иногда строится модель регрессии с включением (явно) фактора времени и фиктивных переменных. При этом количество фиктивных переменных должно быть на единицу меньше числа моментов (периодов) времени внутри одного цикла колебаний. Каждая фиктивная переменная отражает сезонную (циклическую) компоненту ряда, для какого либо одного периода, поэтому она просто численно равна единице для данного периода и нулю для всех остальных периодов. Основным недостатком модели с фиктивными переменными является большое количество фиктивных переменных во многих случаях и тем самым снижение числа степеней свободы. В свою очередь уменьшение числа степеней свободы снижает вероятность получения статистически значимых оценок параметров уравнения регрессии.
Кроме сезонных и циклических колебаний весьма важную роль играют единовременные изменения характера тенденции временного ряда. Эти (относительно) быстрые однократные изменения тренда (его характера) вызываются структурными изменениями в экономике, либо мощными глобальными (внешними) факторами. Прежде всего выясняется значимо ли повлияли общие структурные изменения на характер тренда. При условии значимости такого влияния (структурных изменений) на характер тренда используется кусочно-линейная модель регрессии. Кусочно-линейная модель означает представление исходной совокупности данных ряда в виде двух частей. Одна часть данных моделируется просто линейной моделью с одним коэффициентом регрессии (углом наклона прямой) и представляет данные до момента (периода) структурных изменений. Вторая часть данных это тоже линейная модель, но уже с иным коэффициентом регрессии (углом наклона).
После построения двух таких моделей (подмоделей) линейной регрессии получают уравнения двух соответствующих прямых. Если структурные изменения незначительно повлияли на характер тенденции ряда, то вместо построения точной кусочно-линейной модели вполне можно использовать единую аппроксимирующую модель, т.е. использовать одну общую линейную зависимость (одну прямую) тоже вполне приемлемо представляющую данные в целом. Незначительное ухудшение в отдельных данных при этом не принципиально.
Если строится кусочно-линейная модель, то снижается остаточная сумма квадратов по сравнению с единым для всей совокупности уравнением тренда. В то же время разделение исходной совокупности на две части ведет к потере числа наблюдений и, тем самым, к снижению числа степеней свободы в каждом уравнении кусочно-линейной модели. Единое уравнение для всей совокупности данных позволяет сохранить число наблюдений исходной совокупности. Остаточная сумма квадратов по этому уравнению в то же время выше, чем такая же сумма для кусочно-линейной модели. Выбор конкретной (одной из двух моделей) именно кусочно-линейной или просто линейной, т.е. единого уравнения тренда зависит от соотношения между снижением остаточной дисперсии и потерей числа степеней свободы при переходе от единого уравнения регрессии к кусочно-линейной модели.
Для оценки этого соотношения был предложен статистический тест Грегори-Чоу. В этом тесте рассчитываются параметры уравнений трендов, вводится гипотеза о структурной стабильности тенденции исследуемого ряда динамики. Ясно, что остаточную сумму квадратов кусочно-линейной модели можно найти как сумму соответствующих сумм квадратов для обоих линейных компонентов модели. Сумма числа степеней свободы этих компонентов дает число степеней свободы всей модели в целом. Тогда сокращение остаточной дисперсии при переходе от единого уравнения тренда к кусочно-линейной модели это просто остаточная сумма квадратов, из которой вычтены соответствующие суммы для обеих компонент кусочно-линейной модели. Столь же просто определяется и соответствующее число степеней свободы.
После этого рассчитывается фактическое значение F-критерия по дисперсиям на одну степень свободы. Это значение сравнивают с табличным, полученным по таблицам распределения Фишера для требуемого уровня значимости и соответствующего числа степеней свободы. Как всегда, если расчетное (фактическое) значение больше табличного (критического), то гипотеза о структурной стабильности (незначимости структурных изменений) отклоняется. Влияние же структурных изменений на динамику изучаемого показателя признается значимым. Таким образом следует моделировать тенденцию ряда динамики с помощью кусочно-линейной модели. Если же расчетное значение меньше критического, то нельзя отклонять нуль-гипотезу без риска сделать неверный вывод. В этом случае следует использовать единое для всей совокупности уравнение регрессии как наиболее достоверное и минимизирующее вероятность ошибки.
К наиболее сложным задачам эконометрики относится изучение причинно-следственных зависимостей переменных, представленных в форме рядов динамики. Нужно проявлять особую осторожность в попытках использовать для этого традиционные методы кореляционно-регрессионного анализа. Дело в том, что эти ситуации характеризуются существенной спецификой и для адекватного исследования их имеются специальные методы, учитывающие эту специфику ситуации. На предварительном этапе анализа исследуется наличие в исходных данных сезонных или циклических колебаний в качестве выявления структуры изучаемого ряда динамики. Если такие компоненты имеются, то до проведения дальнейшего исследования взаимосвязи следует устранить сезонную или циклическую компоненту из уровней ряда. Это необходимо поскольку наличие таких компонент приведет к завышению истинных показателей силы и тесноты связи изучаемых рядов динамики, когда оба ряда содержат циклические компоненты одинаковой периодичности. Если же сезонные или циклические колебания содержит только один из рядов или периодичность колебаний в этих рядах различна, то соответствующие показатели будут занижены.
В основе всех методов устранения тренда лежат те или иные попытки устранения или фиксирования воздействия фактора времени на формирование уровней ряда. Все их можно разделить на два класса. В первый класс попадают методы, основанные на преобразовании уровней исходного ряда в новые переменные, не содержащие тренда. Полученные переменные используются для анализа взаимосвязи изучаемых временных рядов. Эти методы предполагают непосредственное устранение тренда из каждого уровня ряда динамики. Главные представители методов данного класса это метод последовательных разностей и метод отклонения от трендов.
Во второй класс попадают методы, основанные на изучении взаимосвязи исходных уровней временных рядов при элиминировании воздействия фактора времени на зависимую и независимые переменные модели. Прежде всего, это метод включения в модель регрессии по рядам динамики фактора времени.
В корреляционно-регрессионном анализе можно устранить воздействие какого либо фактора, если зафиксировать воздействие этого фактора на результат и другие включенные в модель факторы. Такой способ применяется в анализе рядов динамики, когда тренд фиксируется посредством включения фактора времени в модель в качестве независимой переменной. В простейшей линейной модели такое включение времени имеет вид слагаемого, которое есть просто произведение некоторого коэффициента на время. Кроме текущих переменных в уравнение регрессии могут входить также и лаговые значения результативной переменной.
Такая модель имеет некоторые преимущества по сравнению с методами отклонений от трендов и метода последовательных разностей. Она позволяет учесть всю информацию, содержащуюся в исходных данных. Это объясняется тем, что значения результативной переменной и факторов представляют собой уровни исходных рядов динамики. Важно также то, что сама модель строится по всей совокупности данных за рассматриваемый период. Это выгодно отличает модель от метода последовательных разностей, который приводит к потере числа наблюдений. Сами параметры модели с включением фактора времени определяют с помощью обычного МНК.
Метод отклонений от тренда для анализа взаимосвязи двух временных рядов заключается в следующем. Пусть каждый из рядов содержит тренд и случайную компоненту. Выполняется аналитическое выравнивание для каждого из этих двух рядов. Оно позволяет найти параметры соответствующих уравнений трендов. Также при этом определяются расчетные по тренду уровни рядов. Такие расчетные значения можно принять за оценку тренда каждого ряда. В свою очередь влияние тренда можно устранить вычитанием расчетных значений уровней ряда из фактических. После этого выполняется дальнейший анализ взаимосвязи рядов, но опираясь теперь уже не на исходные уровни, а используя отклонения от тренда. Вполне естественно считается, что отклонения от тренда сами уже не содержат основную тенденцию, поскольку все предыдущие процедуры как раз и имели своей целью ее устранение из отклонений.
Нередко вместо аналитического выравнивания ряда динамики для устранения тренда можно использовать более простой метод последовательных разностей. Так, если ряд динамики содержит явно выраженную линейную тенденцию, то ее можно устранить с помощью замены исходных уровней ряда цепными абсолютными приростами (первыми разностями). При наличии сильной линейной тенденции случайные остатки оказываются достаточно малы. В соответствии с предпосылками МНК и с учетом того, что коэффициент регрессии b это просто константа, не зависящая от времени, получаем, что первые разности уровней ряда не зависят от переменной времени. Поэтому их (первые разности) можно использовать для дальнейшего анализа. При наличии тренда в виде параболы второго порядка для устранения тренда используют замену исходных уровней ряда на вторые (а не первые) разности. Если тренд соответствует экспоненциальной или степенной зависимости, то метод последовательных разностей применяют не исходным уровням ряда, а к логарифмам исходных уровней.
В отличие от уравнения регрессии по отклонениям от тренда параметры уравнения в последовательных разностях имеют как правило прозрачную и простую интерпретацию. Но применение этого метода сокращает число пар наблюдений, по которым строится уравнение регрессии. Это означает в свою очередь потерю числа степеней свободы. Другой недостаток этого метода заключается в том, что использование вместо исходных уровней временного ряда их приростов или ускорений приводит к потере информации, содержащейся в исходных данных.
Важной проблемой, естественно примыкающей к рассмотренным темам, является автокорреляция в остатках. Дело в том, что последовательность остатков может рассматриваться как временной ряд. Тогда возникает возможность построения зависимости этой последовательности остатков от времени. Согласно предпосылкам адекватности применения МНК сами остатки должны быть случайными. В моделировании рядов динамики весьма распространена ситуация, когда остатки содержат тренд или циклические колебания. В этом случае каждое следующее значение остатков зависит от предшествующих, что и свидетельствует об автокорреляции остатков.
Такая автокорреляция остатков бывает связана с исходными данными и вызвана ошибками измерения в значениях результативного признака. В других случаях автокорреляция остатков происходит из-за недостатков формулировки модели. Например, может отсутствовать фактор, оказывающий существенное воздействие на результат, влияние которого отражается в остатках. Тем самым остатки вполне могут оказаться автокоррелированными. Помимо фактора времени в качестве таких существенных факторов могут выступать лаговые значения переменных, включенных в модель. Также может иметь место и такая ситуация, когда модель не учитывает несколько второстепенных по отдельности факторов, совместное влияние которых на результат уже оказывается существенным. Эта существенность проистекает в силу совпадения тенденций их изменения или фаз циклических колебаний.
Вместе с тем от такой истинной автокорреляции остатков необходимо отличать те ситуации, в которых причина автокорреляции заключается в неверной спецификации функциональной формы модели. Тогда уже нужно изменить форму связи факторных и результативного признаков. Именно это, а не использование специальных методов расчета параметров уравнения регрессии при наличии автокорреляции остатков, необходимо выполнять в таком случае.
Для определения автокорреляции остатков можно использовать построение графика зависимости остатков от времени с целью последующего визуального определения наличия или отсутствия автокорреляции. Другой метод это использование критерия Дарбина-Уотсона и расчет соответствующего теста. По существу этот тест представляет собой просто отношение суммы квадратов разностей последовательных значений остатков к остаточной сумме квадратов по модели регрессии. Надо иметь в виду, что практически во всех прикладных эконометрических и статистических программах указывается наряду со значениями t- и F-критериев, коэффициентом детерминации также значение критерия Дарбина-Уотсона.
Сам алгоритм выявления автокорреляции остатков на основе критерия Дарбина-Уотсона таков:
1. выдвигается гипотеза об отсутствии автокорреляции остатков;
2. альтернативные гипотезы состоят в наличии положительной или отрицательной автокорреляции в остатках;
3. затем по специальным таблицам определяются критические значения критерия Дарбина-Уотсона для заданного числа наблюдений, числа независимых переменных модели и уровня значимости;
4. по этим значениям числовой промежуток разбивают на пять отрезков.
Два из этих отрезков образуют зону неопределенности. Три других отрезка соответственно дают, что нет оснований отклонять гипотезу об отсутствии автокорреляции, есть положительная автокорреляция, есть отрицательная автокорреляция. При попадании в зону неопределенности практически считают, что имеется существование автокорреляции остатков и поэтому отклоняют гипотезу об отсутствии автокорреляции остатков.
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 4992; Нарушение авторских прав?; Мы поможем в написании вашей работы!