КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция 16
|
|
|
|
OpenMP
ЛЕКЦИЯ 15.
Интерфейс OpenMP задуман как стандарт для программирования на
масштабируемых SMP-системах (модель общей памяти). В стандарт OpenMP
входят спецификации набора директив компилятора, процедур и переменных
среды. До появления OpenMP не было подходящего стандарта для эффективно-
го программирования на SMP-системах.
Наиболее гибким, переносимым и общепринятым интерфейсом параллель
ного программирования является MPI (интерфейс передачи сообщений). Одна-
ко модель передачи сообщений:
• недостаточно эффективна на SMP-системах;
• относительно сложна в освоении, так как требует мышления в "невычислительных" терминах. POSIX-интерфейс для организации нитей (Pthreads)
поддерживается широко (практически на всех UNIX-системах), однако по
многим причинам не подходит для практического параллельного програм-
мирования: слишком низкий уровень, нет поддержки параллелизма по
данным.
OpenMP можно рассматривать как высокоуровневую надстройку над
Pthreads (или аналогичными библиотеками нитей). За счет идеи "инкременталь-
ного распараллеливания" OpenMP идеально подходит для разработчиков, же-
лающих быстро распараллелить свои вычислительные программы с большими
параллельными циклами. Разработчик не создает новую параллельную про-
грамму, а просто последовательно добавляет в текст последовательной про-
граммы OpenMP-директивы. При этом, OpenMP - достаточно гибкий механизм,
предоставляющий разработчику большие возможности контроля над поведени-
ем параллельного приложения. Предполагается, что OpenMP-программа на од-
нопроцессорной платформе может быть использована в качестве последова-
тельной программы, т.е. нет необходимости поддерживать последовательную и
параллельную версии. Директивы OpenMP просто игнорируются последова-
тельным компилятором.
Спецификация OpenMP для C/C++, содержит следующую функциональ-
ность:
• Директивы OpenMP начинаются с комбинации символов "# pragma
omp". Директивы можно разделить на 3 категории: определение парал лельной секции, разделение работы, синхронизация. Каждая директива
может иметь несколько дополнительных.
• Компилятор с поддержкой OpenMP определяет макрос " _OPENMP", ко
торый может использоваться для условной компиляции отдельных бло-
ков, характерных для параллельной версии программы.
• Распараллеливание применяется к for-циклам, для этого используется ди
ректива " #pragma omp for ". В параллельных циклах запрещается исполь-
зовать оператор break.
• Статические (static) переменные, определенные в параллельной области
программы, являются общими (shared).
• Память, выделенная с помощью malloc(), является общей (однако указа-
тель на нее может быть как общим, так и приватным).
• Типы и функции OpenMP определены во включаемом файле < omp.h >.
• Кроме обычных, возможны также "вложенные" (nested) мьютексы - вме-
сто логических переменных используются целые числа, и нить, уже за-
хватившая мьютекс, при повторном захвате может увеличить это число.
Программная модель OpenMP представляет собой fork-join параллелизм, в котором главный поток по необходимости порождает группы потоков, при
вхождении программы в параллельные области приложения.
В случае симметричного мультипроцессинга SMP на всех процессорах процессорной системы исполняется один экземпляр операционной системы, которая отвечает за распределение прикладных процессов (задач, потоков) между отдельными процессорами.
Интерфейс OpenMP является стандартом для программирования на мас-
штабируемых SMP-системах с разделяемой памятью. В стандарт OpenMP вхо-
дят описания набора директив компилятора, переменных среды и процедур. За
счет идеи "инкрементального распараллеливания" OpenMP идеально подходит
для разработчиков, желающих быстро распараллелить свои вычислительные
программы с большими параллельными циклами. Разработчик не создает но-
вую параллельную программу, а просто добавляет в текст последовательной
программы OpenMP-директивы.
Предполагается, что OpenMP-программа на однопроцессорной платформе может быть использована в качестве последовательной программы, т.е. нет необходимости поддерживать последовательную и параллельную версии. Директивы OpenMP просто игнорируются последовательным компилятором, а для
вызова процедур OpenMP могут быть подставлены заглушки, текст которых
приведен в спецификациях. В OpenMP любой процесс состоит из нескольких
нитей управления, которые имеют общее адресное пространство, но разные по-
токи команд и раздельные стеки. В простейшем случае, процесс состоит из од-
ной нити.
Обычно для демонстрации параллельных вычислений используют простую программу вычисления числа π. Рассмотрим, как можно написать такую программу в OpenMP. Число π можно определить следующим образом:
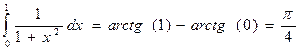
Вычисление интеграла затем заменяют вычислением суммы:
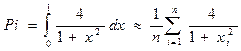
где xi = (i- 1/2 ) / n.
В последовательную программу вставлены две строки (директивы), и она становится параллельной
#include <stdio.h>
double f(double y) {return(4.0/(1.0+y*y));}
int main()
{
double w, x, sum, pi;
int i;
int n = 1000000;
w = 1.0/n;
sum = 0.0;
#pragma omp parallel for private(x) shared(w)
reduction(+:sum)
for(i=0; i < n; i++)
{
x = w*(i-0.5);
sum = sum + f(x);
}
pi = w*sum;
printf("pi = %f ", pi);
}
Программа начинается как единственный процесс на головном процессоре. Он исполняет все операторы вплоть до первой конструкции типа #pragma omp. В рассматриваемом примере это оператор parallel for, при исполнении которого порождается множество процессов с соответствующим каждому процессу окружением.
В случае симметричного мультипроцессинга SMP на всех процессорах процессорной системы исполняется один экземпляр операционной системы, которая отвечает за распределение прикладных процессов (задач, потоков) между отдельными процессорами. Распараллеливание применяется к for-циклам, для этого используется директива " #pragma omp for ", по которой ОС раздает процессорам (ядрам) личный экземпляр программы, как в SPMD, попросту передает один и тотже отрезок программы на заданное число процессоров. Распараллеливание применяется к for-циклам, для этого используется директива
" #pragma omp for ", по котоой ОС раздает ппроцессорам (ядрам) личный эк-
земпляр программы, как в SPMD.
В рассматриваемом примере окружение состоит из локальной (PRIVATE) переменной х, переменной sum редукции (REDUCTION) и одной разделяемой
(SHARED) переменной w. Переменные х и sum локальны в каждом процессе
без разделения между несколькими процессами. Переменная w располагается в
головном процессе. Оператор REDUCTION имеет в качестве атрибута опера-
цию, которая применяется к локальным копиям параллельных процессов в кон-
це каждого процесса для вычисления значения переменной в головном процес-
се. Переменная цикла i является локальной в каждом процессе, так как именно
с уникальным значением этой переменной порождается каждый процесс. Па-
раллельные процессы завершаются оператором END DO, выступающим как
синхронизирующий барьер для порожденных процессов. После завершения
всех процессов продолжается только головной процесс.
Директивы OpenMP с точки зрения C являются комментариями и начина-
ются с комбинации символов #pragma, поэтому приведенная выше программа
может без изменений выполняться на последовательной ЭВМ в обычном ре-
жиме.
Распараллеливание в OpenMP выполняется при помощи вставки в
текст программы специальных директив, а также вызова вспомогательных
функций. При использовании OpenMP предполагается SPMD-модель (Single
Program Multiple Data) параллельного программирования, в рамках которой для
всех параллельных нитей используется один и тот же код.
Программа начинается с последовательной области – сначала работает один процесс (нить), при входе в параллельную область порождается (компилятором) ещё некоторое число процессов, между которыми в дальнейшем распре-
деляются части кода. По завершении параллельной области все нити, кроме
одной (нити мастера), завершаются, и начинается последовательная область. В
программе может быть любое количество параллельных и последовательных
областей.
Кроме того, параллельные области могут быть также вложенными друг в
друга. В отличие от полноценных процессов, порождение нитей является отно
сительно быстрой операцией, поэтому частые порождения и завершения нитей
не так сильно влияют на время выполнения программы.
После получения исполняемого файла необходимо запустить его на требуемом количестве процессоров. Для этого обычно нужно задать количество ни
тей, выполняющих параллельные области программы, определив значение
переменной среды MP_NUM_THREADS. После запуска начинает работать од-
на нить, а внутри параллельных областей одна и та же программа будет выпол-
няться всем набором нитей. При выходе из параллельной области производится
неявная синхронизация и уничтожаются все нити, кроме породившей. Все по-
рождённые нити исполняют один и тот же код, соответствующий параллельной
области. Предполагается, что в SMP-системе нити будут распределены по раз-
личным процессорам, однако это, как правило, находится в ведении операци-
онной системы.
Перед запуском программы количество нитей, выполняющих параллельную область, можно задать, с помощью переменной среды МP_NUM_THREADS.
Например, в Linux это можно сделать при помощи следующей команды: export OMP_NUM_THREADS=n. Функция omp_get_num_procs () возвращает количество процессоров, доступных для использования программе пользователя на момент вызова. Директивы master (master... end master) выделяют участок кода, который будет выполнен только нитью-мастером. Остальные нити просто
пропускают данный участок и продолжают работу с оператора, расположенно-
го следом за ним. Неявной синхронизации данная директива не предполагает.
Модель данных в OpenMP предполагает наличие как общей для всех нитей области памяти, так и локальной области памяти для каждой нити. В OpenMP переменные в параллельных областях программы разделяются на два основных класса:
• shared (общие; все нити видят одну и ту же переменную);
• private (локальные, каждая нить видит свой экземпляр переменной).
Общая переменная всегда существует лишь в одном экземпляре для всей области действия. Объявление локальной переменной вызывает порождение своего экземпляра данной переменной (того же типа и размера) для каждой нити.
Изменение нитью значения своей локальной переменной никак не влияет на изменение значения этой же локальной переменной в других нитях. Если не-
сколько переменных одновременно записывают значение общей переменной
без выполнения синхронизации или если как минимум одна нить читает значе-
ние общей переменной и как минимум одна нить записывает значение этой
переменной без выполнения синхронизации, то возникает ситуация так назы-
ваемой «гонки данных». Для синхронизации используется оператор barrier:
#pragma omp barrier
Нити, выполняющие текущую параллельную область, дойдя до этой директивы, ждут, пока все нити не дойдут до этой точки прграммы, после чего разблокируются и продолжают работать дальше.
Директивы OpenMP просто игнорируются последовательным компилятором, а для вызова функций OpenMP могут быть подставлены специальные «за-
глушки» (stub), текст которых приведен в описании стандарта. Они гарантиру-
ют корректную работу программы в последовательном случае – нужно
только перекомпилировать программу и подключить другую библиотеку.
OpenMP может использоваться совместно с другими технологиями парал-
лельного программирования, например, с MPI. Обычно в этом случае MPI ис-
пользуется для распределения работы между несколькими вычислительными
узлами, а OpenMP затем используется для распараллеливания на одном узле.
Простейшая программа, реализующаяю перемножение двух квадратных
матриц, представлена ниже. В программе замеряется время на основной
вычислительный блок, не включающий начальную инициализацию. В ос-
новном вычислительном блоке программы на языке Фортран изменён порядок
циклов с параметрами i и j для лучшего соответствия правилам размещения
элементов массивов.
#include <stdio.h>
#include <omp.h>
#define N 4096
double a[N][N], b[N][N], c[N][N];
int main()
{
int i, j, k;
double t1, t2;
// инициализация матриц
for (i=0; i<N; i++)
for (j=0; j<N; j++)
a[i][j]=b[i][j]=i*j;
t1=omp_get_wtime();
// основной вычислительный блок
#pragma omp parallel for shared(a, b, c) private(i, j, k)
for(i=0; i<N; i++){
for(j=0; j<N; j++){
c[i][j] = 0.0;
for(k=0; k<N; k++) c[i][j]+=a[i][k]*b[k][j];
}
}
t2=omp_get_wtime();
printf("Time=%lf ", t2-t1)
Рассмотрим реализации, которые позволяют увеличить количество одновременно работающих АЛУ, процессоров, что увеличивает быстродействие ЭВМ.
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 516; Нарушение авторских прав?; Мы поможем в написании вашей работы!