КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Система файловых архивов FTP
|
|
|
|
Информационно-поисковые системы в среде WWW
Информационные технологии WWW
Ч
Мировые информационные сети, их классификация и характеристика
Отличительной чертой ЛВС является большая скорость передачи данных, низкий уровень ошибок и использование дешевой среды передачи данных. Большинство ЛВС принадлежат какой-либо конкретной организации, которая их поддерживает.
Типы сетей
Сети часто разделяют на три основных типа в зависимости от размера географической области, которую они охватывают. Небольшая область обычно связывается с термином "локальная вычислительная сеть" (Local Area Network - LAN). Большие области связываются с терминами "региональная вычислительная сеть" (Metropolitan Area Network - MAN) и "глобальная вычислительная реть" (Wide Area Network - WAN).
Локальная вычислительная сеть (ЛВС). Если сеть привязана к одному месту (обычно одному зданию или комплексу различных зданий), то она называется локальной. ЛВС связывает компьютерные системы и периферийные устройства (накопители на жестких дисках, стримеры, принтеры и т. п.) в группы, которые сообща используют данные и периферийные устройства.
Ниже приведены наиболее распространенные сетевые топологии.
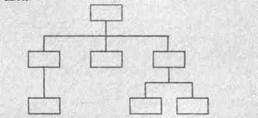
■ Иерархическая. Каждое из устройств обеспечивает непосредственное управление устройствами низшими по иерархии. Данная конструкция отличается простотой в общем управлении сетью, хорошими возможностями для расширения сети.
■ Горизонтальная. Характерна простота управления. Однако труден поиск неисправностей и необходимо резервирование главной шины.
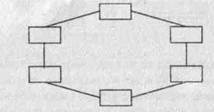
Кольцевая. Обычно данные расхпюстраняются только в одном направлении, передаваясь от станции к станции. Однако при отказе канала между двумя узлами происходит отказ всей сети, поэтому, как правило, в сеть встраиваются переключатели, изменяющие маршрут к узлу.
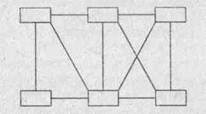
■ Ячеистая Устойчива к перегрузкам и отказам, высока надежность, однако сложна логика обмена данными.
Региональная вычислительная сеть. Если сеть охватывает целый город, то она является региональной вычислительной сетью (РВС). РВС - это самый новый тип сетей. РВС имеют много общего с ЛВС, но они по многим параметрам сложнее последних.
Например, помимо обмена данными и голосового обмена, РВС могут передавать видео- и аудиоинформацию.
РВС разработаны для поддержки больших расстояний, чем ЛВС. Они могут использоваться для связывания нескольких ЛВС вместе в высокоскоростные интегрированные сетевые системы. РВС сочетают лучшие характеристики ЛВС (низкий уровень ошибок, высокая скорость передачи) с большей географической протяженностью.
Глобальная вычислительная сеть. Если сеть распространяется на широкие области, такие, как страны, она называется глобальной вычислительной сетью (ГВС). Коммуникации по ГВС осуществляются посредством телефонных линий, спутниковой связи
или наземных микроволновых систем. ГВС зачастую создаются путем объединения ЛВС и РВС. Фактически объединение изолированных ЛВС и РВС в форму ГВС является современной тенденцией в области сетей. Поскольку ГВС. как правило, включают объединение многих ЛВС и РВС, то они часто представляют собой конгломерат различных технологий.
WWW, W3 - система для доступа к гипертекстовой и гипермедиа-информации (как, впрочем, и к любой другой, но соль именно в «ги-пер»). Изначально проект WWW зародился в CERN, европейском центре физики высоких энергий в 1990 г., но со временем перерос рамки сообщества ученых-физиков. Первые программы, демонстрирующие работу системы, были закончены в 1992 г. для компьютера NeXT. За несколько лет, прошедших с тех пор, система WWW совершила победоносное шествие практически по всем операционным платформам, включая самые примитивные (MS-DOS). «Отец» WWW, Тим Бернерс-Ли, сейчас является руководителем консорциума W30, W3 Organization, основанного CERN и MIT (Масачусетский технологический институт) в 1994 г. для развития и стандартизации WWW. В феврале 1995 г. CERN вышел из консорциума, мотивируя это необходимостью сосредоточить все усилия на чисто физических проектах. Преемником CERN стал французский национальный компьютерный центр INRIA.
«Рабочее пространство» WWW - Internet. Это не означает, что WWW и Internet не могут обойтись друг без друга. Нет, вполне возможно использовать WWW в качестве локальной информационной системы. Более того, форматы данных и протоколы не имеют никакой привязки к технологической основе сети (IP). Однако всякая информационная система, помимо технических характеристик, сильна (или слаба) своим содержанием и пользовательским интерфейсом. Так уж получилось, что именно сеть Internet, являясь транспортом, в силу своего размера, открытости и структуры, сделала WWW глобальной реальностью, а миллионы пользователей совместно наполнили Web мириадами документов.
Причины успеха просты - дружественный интерфейс, легкость на-
вигации в Internet, способность легко интегрировать мультимедиа-объекты и решение типа «все в одном» - типичный навигатор (browser) является клиентом для почти всех популярных информационных служб в Internet. Web фантастически популярен и растет даже быстрее Internet.
WWW работает по принципу клиент-сервер, точнее, клиент-серверы: существует множество серверов, которые по запросу клиента возвращают ему гипермедийный документ - документ, состоящий из частей с разнообразным представлением информации (текст, звук, графика, трехмерные объекты и т.д.), в котором каждый элемент может являться ссылкой на другой документ или его часть. Ссылки эти в документах WWW организованы таким образом, что каждый информационный ресурс в глобальной сети Интернет однозначно адресуется, и документ, который Вы читаете в данный момент, способен ссылаться как на другие документы на этом же сервере, так и на документы (и вообще на ресурсы Интернет) на других компьютерах Интернет. Причем пользователь не замечает этого, и работает со всем информационным пространством Интернет как с единым целым. Ссылки WWW указывают не только на документы, специфичные для самой WWW, но и на прочие сервисы и информационные ресурсы Интернет. Более того, большинство программ-клиентов WWW (browsers, навигаторы) не просто понимают такие ссылки, но и являются программами-клиентами соответствующих сервисов: ftp, gopher, сетевых новостей Usenet, электронной почты и т.д. Таким образом, программные средства WWW являются универсальными для различных сервисов Интернет, а сама информационная система WWW играет интегрирующую роль.
Надо отметить, что идея распределенного гипертекста зародилась довольно давно. Например, можно отметить проект одного из австрийских университетов Hyper-G. С точки зрения автора своим успехом WWW в очень большой степени обязана NCSA, разработавшему популярнейший в прошлом WWW-навигатор с графическими способностями. В начале 1993 г. NCSA, National Center for Supercomputing Applications, Национальный центр суперкомпьютерных приложений при университете штата Иллинойс в Урбана-Шампань выпустил в свет первую версию Mosaic - WWW-навигатора, которому было суждено завоевать мир. В свое время Mosaic прозвали «Internet killer application» (т.е. хит, бестселлер Интернет), и она была доступна практически для всех клонов Unix и для MS-Windows. Мозаика была основным инструментом для пользователей WWW. С тех пор многое изменилось.
Следующий этап - образование компании Netscape Communications Corp. (NS) и выпуск этой компанией нового навигатора. Между бесплатным навигатором Mosaic и Netscape Navigator (далее просто Netscape) существует некая генеалогическая связь. Дело в том, что их написали одни и те же люди, в большинстве своем ныне работающие в Netscape Communications Corporation. Сейчас такое высказывание, может быть, не совсем точно, так как в команду Mosaic влились новые программис-
ты вместо ушедших. С начала 1996 года и Relcom и Demos начали распространение Netscape в России. Первые версии Netscape распространялись бесплатно и ими до сих пор многие пользуются.
Система WWW в целом состоит из следующих компонент:
• HTML (HyperText Markup Language) - язык гипертекстовой разметки;
• HTTP (HyperText Transfer Protocol) - прикладной протокол, разработанный для обмена гипертекстовой информацией в Internet;
• Спецификаций на типы данных в Internet (Internet Media Types);
• Система WWW-адресации (URL).
Язык HTML очень прост. Разработчики WWW и позже консорциум W30 стремятся оформить HTML как DTD (Document Type Definition) в терминах SGML (Standard Generalized Markup Language), ISO-стандарта (ISO - International Standards Organization - международная организация стандартов) для обработки документов. С практической точки зрения HTML представляет собой разметку, сделанную обычными английскими словами внутри документа. HTML был разработан для того, чтобы выделить в документах логическую структуру.
Протокол HTTP (HyperText Transfer Protocol) также в высшей степени прост, что иногда вредит организации информационного сервиса. Это правила общения между навигатором и WWW-сервером. Одна сессия легко укладывается в схему запрос-ответ. В простейшем случае навигатор требует некий документ, и сервер его выдает. С одной стороны, такая простота - вещь хорошая, с другой - это влечет за собой дополнительные накладные расходы и, следовательно, временные задержки и неэффективность.
Схема HTTP содержит идентификатор, адрес машины, ТСР-порт, путь в директории сервера, поисковый критерий и метку: http:// polyn.net.kiae.su/polyn/manifest.html.
Согласование типов документов, передаваемых в рамках WWW, производится с помощью заголовков, которыми обмениваются навигатор и WWW-сервер. Весь комплекс заголовков известен как MIME, Multipurpose Internet Mail Extensions. Это означает «многоцелевые расширения почты в Интернет», и следы MIME можно видеть во многих электронных письмах.
Заголовки:
Content-Transfer-Encoding: iso8859-5 Content-Length: 8674
и,уж безусловно, MIME-Version: 1.0
- есть несомненный признак MIME.
Сами типы документов специфицированы в RFC (Request For Comment - запрос для комментария. Портфель документов, в которых опубликованы стандарты Internet, предлагаемые ей ^андарты, а также


 общепринятые идеи, негласные стандарты и т.п. Эти документы фактически определяют Internet), описывающем так называемые «типы данных в Internet» (Internet Media Types).
общепринятые идеи, негласные стандарты и т.п. Эти документы фактически определяют Internet), описывающем так называемые «типы данных в Internet» (Internet Media Types).
Навигатор должен знать, какого типа документ он получает, ведь он должен его интерпретировать, показывать и вообще что-то с ним делать.
Навигаторы предоставляют пользователю возможность указывать внешние программы-интерпретаторы для разных типов документов.
Для внесения в WWW возможности интерактивного диалога с пользователем и создания динамических документов имеется ряд способов, частично стандартизованных, частично нет. Это такие средства, как:
CGI (CommonGatewaylnterface) - часть HTML, создание интерактивных форм, создание документов, как вывод программ. Интерфейс CGI был специально разработан для расширения возможностей WWW за счет подключения всевозможного внешнего программного обеспечения. Такой подход логично продолжал принцип публичности и простоты разработки и наращивания возможностей WWW. По настоящему полезные формы профессионального уровня все же создавать в рамках CGI невозможно. Этому мешают бедность средств CGI и свойства (statelessness) протокола HTTP.
SSI, SSI+ - нестандартизованные расширения серверов, например, доступ к БД через ODBC без программирования.
Страница базы данных WWW - законченный информационный объект, который отображается пользователю при обращении к информационному ресурсу WWW по универсальному идентификатору этого ресурса (URL).
Таким образом, мы видим, что WWW представляет собой систему:
• открытую (все спецификации, протоколы и т.д. опубликованы и доступны бесплатно);
• масштабируемую (система адресации);
• легко интегрируемую и расширяемую (MIME, внешние интерпретаторы).
К информационным технологиям WWW относятся: HTML, URL, HTTP, CGI, Java, JavaScript.
Java - это современный язык для разработки приложений, созданный специально для распределенных сред. Java является простым объектно-ориентированным языком, не требующим длительного обучения программистов. Для работы в сетецентрической среде возрастающей сложности система программирования должна соответствовать объектно-ориентированной концепции.
Java является знакомым языком программирования, так как синтаксис Java во многом напоминает C++. Исключение адресной арифметики по мнению создателей должно обеспечить более надежный код
по сравнению с C++. Надежность программ обеспечивается проверками на этапе компиляции и последующей проверкой во время выполнения.
Язык JavaScript разрабатывался компанией Netscape как язык сценариев просмотра HTML-страниц. JavaScript является объектно-ориентированным языком. В целом язык ориентирован на встроенные объекты Netscape Navigator: окна, формы, поля форм, элементы рабочих областей Navigator. Это сильно облегчает обучение языку и позволяет сразу писать интересные и полезные программы.
Используя JavaScript, можно организовать многооконный интерфейс с локальной справочной системой и встроенной графикой, возложив при этом многие вопросы проверки вводимых пользователем данных на JavaScript. По своим функциональным возможностям JavaScript довольно сильно уступает Java: можно организовать прокрутку текста, организовать открытие нового окна, запрограммировать калькулятор, но не более того.
Таким образом, нами были рассмотрены два класса доступа к информационным ресурсам Internet: распределенные файловые системы (Usenet, FTP, Gopher, NFS), распределенные информационные системы (WWW, WAIS).
Основные протоколы, используемые в Интернет, не обеспечены достаточными встроенными функциями поиска, не говоря уже о миллионах серверах, находящихся в ней. Протокол HTTP, используемый в Интернет, хорош лишь в отношении навигации, которая рассматривается только как средство просмотра страниц, но не их поиска. То же самое относится и к протоколу FTP, который даже более примитивен, чем HTTP. Из-за быстрого роста информации, доступной в Сети, навигационные методы просмотра быстро достигают предела их функциональных возможностей, не говоря уже о пределе их эффективности. Не указывая конкретных цифр, можно сказать, что нужную информацию уже не представляется возможным получить сразу, так как в Сети сейчас находятся миллиарды документов и все они в распоряжении пользователей Интернет, к тому же сегодня их количество возрастает согласно экспоненциальной зависимости. Количество изменений, которым эта информация подвергнута, огромно и, самое главное, они произошли за очень короткий период времени. Основная проблема заключается в том, что единой полной функциональной системы обновления и занесения подобного объема информации, одновременно доступного всем пользователям Интернет во всем мире, никогда не было. Для того чтобы структурировать информацию, накопленную в сети Интернет, и обеспечить ее пользователей удобными средствами поиска необходимых им данных, были созданы поисковые системы.

 Информационно-поисковая система - система, предназначенная для поиска информации в базе данных.
Информационно-поисковая система - система, предназначенная для поиска информации в базе данных.
Поисковые системы обычно состоят из трех компонент:
• агент (паук или кроулер), который перемещается по Сети и собирает информацию;
• база данных, которая содержит всю информацию, собираемую пауками;
• поисковый механизм, который люди используют как интерфейс для взаимодействия с базой данных.
Средства поиска и структурирования, иногда называемые поисковыми механизмами, используются для того, чтобы помочь людям найти информацию, в которой они нуждаются. Средства поиска типа агентов, пауков, кроулеров и роботов используются для сбора информации о документах, находящихся в Сети Интернет. Это специальные программы, которые занимаются поиском страниц в Сети, извлекают гипертекстовые ссылки на этих страницах и автоматически индексируют информацию, которую они находят для построения базы данных. Каждый поисковый механизм имеет собственный набор правил, определяющих, как собирать документы. Некоторые следуют за каждой ссылкой на каждой найденной странице и затем, в свою очередь, исследуют каждую ссылку на каждой из новых страниц, и так далее. Некоторые игнорируют ссылки, которые вед^т к графическим и звуковым файлам, файлам мультипликации; другие игнорируют ссылки к ресурсам типа баз данных WAIS; другие проинструктированы, что нужно просматривать прежде всего наиболее популярные страницы.
Агенты - самые «интеллектуальные» из поисковых средств. Они могут делать больше, чем просто искать: они могут выполнять даже транзакции от имени пользователя. Уже сейчас они могут искать сайты специфической тематики и возвращать списки сайтов, отсортированных по их посещаемости. Агенты могут обрабатывать содержание документов, находить и индексировать другие виды ресурсов, не только страницы. Они могут также быть запрограммированы для извлечения информации из уже существующих баз данных. Независимо от информации, которую агенты индексируют, они передают ее обратно базе данных поискового механизма.
Общий поиск информации в Сети осуществляют программы, известные как пауки. Пауки сообщают о содержании найденного документа, индексируют его и извлекают итоговую информацию. Они просматривают заголовки, некоторые ссылки и посылают проиндексированную информацию базе данных поискового механизма.
Кроулеры просматривают заголовки и возращают только первую ссылку.
Роботы могут быть запрограммированы так, чтобы переходить по различным ссылкам различной глубины вложенности, выполнять индексацию и даже проверять ссылки в документе. Из-за их природы они
могут застревать в циклах, поэтому, проходя по ссылкам, им нужны значительные ресурсы Сети. Однако, имеются методы, предназначенные для того, чтобы запретить роботам поиск по сайтам, владельцы которых не желают, чтобы они были проиндексированы.
Агенты извлекают и индексируют различные виды информации. Некоторые, например, индексируют каждое отдельное слово во встречающемся документе, в то время как другие индексируют только наиболее важных 100 слов в каждом, индексируют размер документа и число слов в нем, название, заголовки и подзаголовки и т.д. Вид построенного индекса определяет, какой поиск может быть сделан поисковым механизмом и как полученная информация будет интерпретирована.
Агенты могут также перемещаться по Интернет и находить информацию, после чего помещать ее в базу данных поискового механизма. Администраторы поисковых систем могут определить, какие сайты или типы сайтов агенты должны посетить и проиндексировать. Проиндексированная информация отсылается базе данных поискового механизма так же, как было описано выше.
Когда кто-либо хочет найти информацию, доступную в Интернет, он посещает страницу поисковой системы и заполняет форму, детализирующую информацию, которая ему необходима. Здесь могут использоваться ключевые слова, даты и другие критерии. Критерии в форме поиска должны соответствовать критериям, используемым агентами при индексации информации, которую они нашли при перемещении по Сети.
База данных отыскивает предмет запроса, основанный на информации, указанной в заполненной форме, и выводит соответствующие документы, подготовленные базой данных. Чтобы определить порядок, в котором список документов будет показан, база данных применяет алгоритм ранжирования. В идеальном случае, документы, наиболее релевантные пользовательскому запросу будут помещены первыми в списке. Различные поисковые системы используют различные алгоритмы ранжирования, однако основные принципы определения релевантности следующие:
1. Количество слов запроса в текстовом содержимом документа (т.е. в html-коде).
2. Тэги, в которых эти слова располагаются.
3. Местоположение искомых слов в документе.
4. Удельный вес слов, относительно которых определяется релевантность, в общем количестве слов документа.
Эти принципы применяются всеми поисковыми системами. А представленные ниже используются некоторыми, но достаточно известными (например, AltaVista, HotBot).
5. Время - как долго страница находится в базе поискового сер
вера. Поначалу кажется, что это довольно бессмысленный прин
цип. Но, если задуматься, как много существует в Интернете сай
тов, которые живут максимум месяц! Если же сайт существует



 довольно долго, это означает, что владелец весьма опытен в данной теме и пользователю больше подойдет сайт, который пару лет вещает миру о правилах поведения за столом, чем тот, который появился неделю назад с этой же темой. 6. Индекс цитируемости - как много ссылок на данную страницу ведет с других страниц, зарегистрированных в базе поисковой системы. База данных выводит ранжированный подобным образом список документов с HTML и возвращает его человеку, сделавшему запрос. Различные поисковые механизмы также выбирают различные способы показа полученного списка - некоторые показывают только ссылки; другие выводят ссылки с первыми несколькими предложениями, содержащимися в документе или заголовок документа вместе с ссылкой. Основные информационно-поисковые системы WWW: Lycos, AltaVista, Yahoo, OpenText, Infoseek. Рассмотрим вкратце характеристики этих систем.
довольно долго, это означает, что владелец весьма опытен в данной теме и пользователю больше подойдет сайт, который пару лет вещает миру о правилах поведения за столом, чем тот, который появился неделю назад с этой же темой. 6. Индекс цитируемости - как много ссылок на данную страницу ведет с других страниц, зарегистрированных в базе поисковой системы. База данных выводит ранжированный подобным образом список документов с HTML и возвращает его человеку, сделавшему запрос. Различные поисковые механизмы также выбирают различные способы показа полученного списка - некоторые показывают только ссылки; другие выводят ссылки с первыми несколькими предложениями, содержащимися в документе или заголовок документа вместе с ссылкой. Основные информационно-поисковые системы WWW: Lycos, AltaVista, Yahoo, OpenText, Infoseek. Рассмотрим вкратце характеристики этих систем.
Lycos (www.lycos.com). В Lycos используется следующий механизм индексации:
• слова в <title> заголовке имеют высший приоритет;
• слова в начале страницы;
• слова в ссылках;
• если в его базе индекса есть сайты, ссылка с которых указывает на индексируемый документ - релевантность этого документа возрастает.
Как и большинство систем, Lycos дает возможность применять простой запрос и более детальный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке, после чего Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о количестве документов на каждое слово, а позже и список ссылок на формально релевантные документы. В списке против каждого документа указывается его мера близости запросу, количество слов из запроса, попавших в документ, и оценочная мера близости, которая может быть больше или меньше формально вычисленной. Пока нельзя вводить логические операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Такая возможность применяется для построения расширенной формы запроса, предназначенной для искушенных пользователей, уже научившихся работать с этим механизмом. Таким образом, видно, что Lycos относится к системе с языком запросов типа «Like this», но намечается его расширение и на другие способы организации поисковых предписаний.
AltaVista (www.altavista.com). Индексирование в этой системе осуществляется при помощи робота. При этом робот имеет следующие приоритеты:
• слова содержащиеся в теге <title> имеют высший приоритет; ключевые фразы в <Meta> тэгах;
• ключевые фразы, находящиеся в начале странички;
• ключевые фразы в ссылках;
• ключевые фразы по количеству вхождений, присутствия слов, фраз.
Если тэгов на странице нет, использует первые 30 слов, которые индексирует и показывает вместо описания (tag description)
Наиболее интересная возможность AltaVista - это расширенный поиск. Здесь стоит сразу оговориться, что, в отличие от многих других систем AltaVista поддерживает одноместный оператор NOT Кроме этого, имеется еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой фразеологический словарь. Кроме всего прочего, при поиске в AltaVista можно задать имя поля, где должно встретиться слово: гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К сожалению, подробно процедура ранжирования в документации по системе не описана, но видно, что ранжирование применяется как при простом поиске, так и при расширенном запросе. Реально эту систему можно отнести к системе с расширенным логическим поиском.
Yahoo (www.yahoo.com). Данная система появилась в Сети одной из первых, и сегодня Yahoo сотрудничает со многими производителями средств информационного поиска, а на различных ее серверах используется различное программное обеспечение. Язык Yahoo достаточно прост: все слова следует вводить через пробел, они соединяются связкой AND либо OR. При выдаче не указывается степень соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на «общие» слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что в базе данных Yahoo информация есть наверняка. Ранжирование производится по числу терминов запроса в документе. Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
OpenText (www.opentext.com). Информационная система OpenText представляет собой самый коммерциализированный информационный продукт в Сети. Все описания больше похожи на рекламу, чем на информативное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, однако размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного
булевого поиска, OpenText можно было бы отнести к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
Infoseek (www.infoseek.com). В этой системе индекс создает робот, но он индексирует не весь сайт, а только указанную страницу. При этом робот имеет такие приоритеты:
• слова в заголовке <title> имеют наивысший приоритет;
• слова в теге keywords, description и частота вхождений\повторе-ний в самом тексте;
• при повторении одинаковых слов рядом выбрасывает из индекса;
• допускает до 1024 символов для тега keywords, 200 символов для тэга description;
• если тэги не использовались, индексирует первые 200 слов на странице и использует как описание.
Система Infoseek обладает довольно развитым информационно-поисковым языком, позволяющим не просто указывать, какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это при помощи специальных знаков «+» - термин обязан быть в документе, и «-» - термин должен отсутствовать в документе. Кроме этого, Infoseek позволяет проводить то, что называется контекстным поиском. Это значит, что используя специальную форму запроса, можно потребовать последовательной совместной встречаемости слов. Также можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Имеется возможность указания ключевых фраз, представляющих собой единое целое, вплоть до порядка слов. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса за вычетом общих слов. Все эти факторы используются как вложенные процедуры. Подводя краткое резюме, можно сказать, что Infoseek относится к традиционным системам с элементом взвешивания терминов при поиске.
Информационное агентство - организация, собирающая, обрабатывающая и распространяющая информацию. Известна поисковая система Magellan (www.magellan.com) одноименного информационного агентства, примечательная тем, что она не использует робота-ин-дексировщика. Все вопросы о включении того или иного информационного ресурса в базу данных поисковой системы решаются специальной редакционной коллегией, что, с одной стороны, гарантирует «чистоту» предоставляемой информации, но, с другой стороны, сильно ограничивает широту охвата поисковой системой представленной в Сети информации.
Среди наиболее известных отечественных поисковых систем стоит отметить Яндекс (www.yandex.ru), Апорт (www.aport.ru) и Рамблер (www.rambler.ru).
FTP (File Transfer Protocol) - протокол передачи файлов, еще один широко распространенный сервис Интернет. При рассмотрении ftp как сервиса Интернет имеется в виду не просто протокол, но именно сервис - доступ к файлам в файловых архивах.
Схема FTP позволяет адресовать файловые архивы FTP из программ-клиентов: ftp://polyn.net.kiae.su/pub/Oindex.txt.
Вообще говоря, ftp - стандартная программа, работающая по протоколу TCP, всегда поставляющаяся с операционной системой. Ее исходное предназначение - передача файлов между разными компьютерами, работающими в сетях TCP/IP: на одном из компьютеров работает программа-сервер, на втором пользователь запускает программу-клиента, которая соединяется с сервером и передает или получает по протоколу ftp файлы. Здесь предполагается, что пользователь зарегистрирован на обоих компьютерах и соединяется с сервером под своим
именем и со своим паролем на этом компьютере. Протокол ftp, разумеется, оптимизирован для передачи файлов. Данная черта и послужила причиной того, что программы ftp стали частью отдельного сервиса Интернет. Дело в том, что сервер ftp может настраивается таким образом, что соединиться с ним можно не только под своим именем, но и под условным именем anonymous - аноним. Тогда Вам становятся доступна не вся файловая система компьютера, а некоторый набор файлов на сервере, которые составляют содержимое сервера anonymous ftp - публичного файлового архива. Итак, если кто-то хочет предоставить в публичное пользование файлы с информацией, программами и прочим, то ему достаточно организовать на своем компьютере, включенном в Интернет, сервер anonymous ftp. Сделать это достаточно просто, программы-клиенты ftp есть практически на любом компьютере -поэтому сегодня публичные файловые архивы организованы в основном как серверы anonymous ftp. На таких серверах сегодня доступно огромное количество информации и программного обеспечения. Практически все, что может быть предоставлено публике в виде файлов, доступно с серверов anonymous ftp. Это и программы - свободно распространяемые и демонстрационные версии, это и мультимедиа, это, наконец, просто тексты - законы, книги, статьи, отчеты. Таким образом, если Вы хотите представить миру демо-версию Вашего программного продукта - anonymous ftp является удачным решением такой задачи. Если, с другой стороны, Вы хотите найти последнюю версию Вашей любимой свободно распространяющейся программы, то искать ее нужно именно на серверах ftp. Несмотря на распространенность, у ftp есть и множество недостатков. Программы-клиенты ftp могут быть не всегда удобны и просты в использовании. Не всегда можно понять, а что это за файл перед Вами - то ли это тот файл, что Вы ищете, то ли нет. Нет простого и универсального средства поиска на серверах anonymous ftp - хотя для этого и существует специальный сервис archie, но это независимая программа, не универсальная и не всегда применимая. Программы ftp довольно стары и некоторые их особенности, бывшие полезными при рождении, не очень понятны и нужны сегодня - так, например, для передачи файлов есть два режима - бинарный и текстовый, и если Вы вдруг неправильно выбрали режим, то передаваемый файл может быть поврежден. Описания файлов на сервере выдаются в формате операционной системы сервера, а список файлов операционной системы UNIX может привести в недоумение пользователя DOS. Проблема тут в том, что со списком файлов выдается лишняя информация, а слишком много знать всегда вредно. Серверы ftp нецентрализованны, и это имеет свои проблемы. Несмотря на все это, серверы anonymous ftp сегодня - стандартный путь организации публичных файловых архивов в Интернет. Вы можете также организовывать доступ к файлам под паролем - например, своим клиентам, ftp - сервис прямого доступа, требующий полноценного подключения к Интернет, но воз-
можен и доступ через электронную почту - существуют серверы, которые могут прислать Вам по электронной почте файлы с любых серверов anonymous ftp. Однако это может быть весьма неудобно, ибо такие серверы сильно загружены, и Ваш запрос может долго ждать своей очереди. Кроме того, большие файлы при отсылке делятся сервером на части ограниченного размера, посылаемые отдельными письмами - и если одна часть из сотни потеряется или повредится при передаче, то остальные 99 тоже окажутся ненужными.
Archie - это не самостоятельный сервис, но сервис, облегчающий работу с серверами anonymous ftp, обеспечивающий поиск файлов на таких серверах. Вам наверняка никогда не придется организовывать свой сервер archie, но пользоваться его услугами придется наверняка. Их всего существует с десяток, и каждый из них сильно загружен. Серверы archie «помнят» списки всех файлов на многих серверах anonymous ftp, и по Вашему запросу могут искать интересующий Вас файл по имени или части имени. Вы задаете шаблон для поиска, указываете характеристики поиска и получаете список имен серверов и мест расположения файлов на них, которые удовлетворяют Вашему запросу. Существуют специальные программы-клиенты archie, но можно воспользоваться услугами такого сервера, и соединившись с ним по протоколу telnet и войдя под именем archie. Если Вы представляете, как может называться файл, который Вы ищете, то archie - адекватное средство его поиска, то средство, которое приходится часто использовать в своей работе. К недостаткам archie относится децентрализованность, высокая загруженность серверов, необходимость уметь задавать шаблон имени для поиска файла. Каждый сервер обслуживает свой набор серверов ftp, возможно перекрывающихся - Вы можете не обнаружить необходимую информацию на одном сервере, но найти на другом, и кто знает, на каком искать прежде.
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 1457; Нарушение авторских прав?; Мы поможем в написании вашей работы!