КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
И контекстно-свободных языков
|
|
|
|
Форме
Обобщенные КС-грамматики и приведение их к удлиняющей
КС-грамматика называется обобщенной, если она содержит аннулирующие правила (e - правила), то есть правила вида A® e, где e - пустая цепочка. Обобщенная грамматика зачастую более проста и наглядна. Тем не менее следует помнить, что для любой обобщенной КС-грамматики существует эквивалентная неукорачивающая КС-грамматика.
Теорема 4.6. Каждая КС-грамматика приводима к виду с не более чем одним аннулирующим правилом S® e, которого может и не быть.
Доказательство. Проведем его, как обычно, конструктивно, построением неукорачивающей грамматики.
Во-первых, нужно определить, порождает ли исходная грамматика пустую цепочку. Пусть S - начальный символ исходной грамматики G. Определим в G множество нетерминалов X i, из которых пустую цепочку можно получить за i шагов, и множество новых нетерминалов Zi. Таким образом, мы определим аннулирующие нетерминалы.
X0 = { A | $ A® e }, Z0 = X0
X1 = { A | $ A® x, где xÎ X0 }, Z1 = X1\ X0
....................................................................
X i = { A | $ A® x, где xÎ 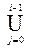 X j }, Z i = X i\ X i-1
X j }, Z i = X i\ X i-1
На каком-то шаге Z i станет равным Æ и процесс формирования аннулирующих нетерминалов можно закончить. Если S Ï X j, где 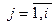 , то e Ï L(G) и правила S® e добавлять не надо. В противном случае, заменим в исходной грамматике во всех правилах S на S1, введем новый исходный нетерминал S и к правилам грамматики G добавим правила
, то e Ï L(G) и правила S® e добавлять не надо. В противном случае, заменим в исходной грамматике во всех правилах S на S1, введем новый исходный нетерминал S и к правилам грамматики G добавим правила
S® e ½ S1.
Все остальные правила вида A® e можно удалить. Для этого заменим каждое из правил, правые части которых содержат хотя бы по одному аннулирующему нетерминалу, множеством новых правил. Если правая часть правила содержит k вхождений аннулирующих нетерминалов, то множество, заменяющее это правило, будет состоять из 2k правил, соответствующих всем возможным способам удаления некоторых (или всех) из этих вхождений.
Пусть имеется правило
B® j 1 A 1 j 2 A 2 j 3 ... j k A k j k+1,
где A i (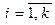 ) - аннулирующие нетерминалы. Добавим к этому правилу следующие правила:
) - аннулирующие нетерминалы. Добавим к этому правилу следующие правила:
B® j 1 j 2 A 2 j 3 ... j k A k j k+1, удалено A 1
B® j 1 A 1 j 2 j 3 ... j k A k j k+1, удалено A 2
..................................
B® j 1 A 1 j 2 A 2 j 3 ... j k j k+1, удалено A k
B® j 1 j 2 j 3 ... j k A k j k+1, удалены A 1, A 2
..................................
B® j 1 j 2 j 3 ... j k j k+1, удалены A 1, A 2,... A k
Заметим, что в случае неоднозначности на этом шаге может получиться меньше чем 2k правил. Так, для аннулирующего нетерминала A правило
B® aAA будет заменяться тремя правилами B® aAA ½ aA ½ a, так как в данном случае безразлично первое или второе вхождение A мы рассматриваем.
После такой замены правил для всех правых частей исходной грамматики, содержащих аннулирующие нетерминалы, исключим из грамматики все e - правила, включая те, которые могли появиться при замене.
В результате мы получим грамматику, эквивалентную исходной, что доказывается с использованием теорем 4.1 и 4.3.
Отметим, что мы рассматривали случай, когда аннулирующие нетерминалы имеют и другие альтернативы, кроме перехода в пустую цепочку. Если A ® e единственная альтернатива нетерминала A, то правые части правил, содержащие его вхождение, можно просто исключить. ƒ
В результате применения рассмотренного алгоритма можно получить КС-грамматику, по которой вывод любой непустой цепочки характеризуется тем, что сентенциальная форма, получаемая на каждом шаге вывода, будет не короче предыдущей. Не случайно полученная грамматика носит название неукорачивающей КС-грамматики (НКС-грамматики).
Пример 4.5. Рассмотрим обобщенную КС-грамматику с аксиомой <число>
<число> ® <знак> <цел.часть>. <др.часть>
<знак> ® + ½ - ½ e
<цел.часть> ® <цел.часть><цифра> ½ e
<др.часть> ® <цел.часть>
<цифра> ® 0 ½ 1 ½...½ 8 ½ 9
и приведем ее к неукорачивающей форме.
Вначале покажем, что данная грамматика не порождает пустой цепочки. Здесь
X0 = { <знак>, <цел.часть> },
X1 = { <др.часть> },
X2 = Æ и Z2 = Æ.
Среди множеств X - нет нетерминала <число> и, следовательно, правила
<число> ® e
добавлять не надо.
Проведем замены правил, правые части которых содержат аннулирующие нетерминалы, а затем удалим e - правила.
В результате получим грамматику
<число> ® <знак> <цел.часть>. <др.часть> ½ <цел.часть>. <др.часть> ½
<знак>. <др.часть> ½ <знак> <цел.часть>. ½. <др.часть> ½
<цел.часть>. ½ <знак>. ½.
<цел.часть> ® <цел.часть><цифра> ½ <цифра>
<др.часть> ® <цел.часть>
<цифра> ® 0 ½ 1 ½...½ 8 ½ 9
На рис. 4.2 представлены деревья вывода цепочки +.9 по исходной (рис. 4.2 (а)) и результирующей (рис. 4.2 (б)) грамматикам.
š
Для приведения грамматики к удлиняющей форме необходимо кроме аннулирующих правил исключить и цепные правила. Цепное правило - это правило вида A® B, где A, B Î N.
Теорема 4.7. Для любой КС-грамматики существует эквивалентная ей грамматика без цепных правил.
Доказательство. Пусть в грамматике имеется правило A ® B и A ¹ S (A - не начальный символ грамматики). Тогда все правила вида C ® aAb заменим на правила C ® aBb, а правила A ® B удалим. Если A = S и для B существуют правила B ® j 1 ½ ... ½ j n, то заменим их на S ® j 1 ½ ... ½ j n , после чего S ® B удалим.
Любое такое преобразование правил допустимо исходя из теорем 4.1 - 4.3 и устраняет правила вида A ® B. Повторяем такие преобразования до тех пор, пока в грамматике не останется цепных правил. š
В результате устранения аннулирующих и цепных правил получается грамматика в удлиняющей форме, где сентенциальная форма на каждом шаге вывода будет длиннее сентенциальной формы на предыдущем шаге. Напомним, что эта форма грамматики использовалась для доказательства теоремы о разрешимости контекстных языков (теорема 1.1).
Пример 4.6. Пусть дана КС-грамматика с правилами
S ® aBa
B ® A ½ Bc
A ® aA ½ bb.
Правило B ® A можно устранить, воспользовавшись результатами теоремы 4.2, и получить грамматику
S ® aBa
B ® aA ½ bb ½ Bc
A ® aA ½ bb š
КС-грамматика G=(N,S,P,S) называется грамматикой без циклов, если в ней нет выводов A Þ+ A для AÎ N. КС-грамматика G называется приведенной, если она без циклов, без аннулирующих правил и без тупиков.
Грамматики с e - правилами и циклами иногда труднее анализировать, чем грамматики без таковых. Кроме того, в любой практической ситуации тупики (бесполезные символы) без необходимости увеличивают объем анализатора. Поэтому для некоторых алгоритмов синтаксического анализа, рассматриваемых во второй части пособия, мы будем требовать, чтобы грамматики, фигурирующие в них, были приведенными. Это требование позволяет рассматривать все КС-языки.
Теорема 4.8. Если L - КС-язык, то L=L(G) для некоторой приведенной КС-грамматики G.
Доказательство. Применить к КС-грамматике, определяющей язык L, эквивалентные преобразования по теоремам 4.5 - 4.7.?
4.4. Устранение левой рекурсии и левая факторизация
В целом ряде приложений требуется, чтобы грамматика рассматриваемого языка не содержала левой рекурсии. Наличие леворекурсивных правил в исходной грамматике не фатально, так как для любой КС-грамматики существует эквивалентная грамматика без левой рекурсии.
Рассмотрим случай когда правила грамматики саморекурсивны, то есть левая часть правила и край правой части совпадают. Пусть нетерминал A имеет m леворекурсивных правил
A ® Aa i для 1 £ i £ m
и n правил
A ® b j для 1 £ j £ n,
которые не являются леворекурсивными (отметим, что отсутствие последних делает A тупиком).
Заменив эти правила на правила
A ® bj <список A> для 1 £ j £ n
<список A> ® a i <список A> для 1 £ i £ m
<список A> ® e,
где <список A> - новый нетерминал, мы получим эквивалентную группу правил без левой рекурсии.
Пример 4.7. Самой короткой грамматикой для представления идентификатора является леворекурсивная грамматика
<И> ® б ½ <И>б ½ <И>ц,
где б - любая буква, а ц - любая цифра. В данной грамматике два леворекурсивных правила и одно правило без левой рекурсии. Заменяя их на правила
<И> ® б<И1>
<И1> ® б<И1> ½ ц<И1> ½ e,
мы получим обобщенную праворекурсивную грамматику идентификатора. Заметим, что исключение аннулирующего правила приведет нас к грамматике из примера 4.3. š
Если в грамматике имеется группа правил вида
A ® ab 1 ½ ... ½ ab n,
то цепочку a можно “вынести за скобку” и преобразовать данную группу правил к виду
A ® a B
B ® b 1 ½ ... ½ b n.
Этот прием носит название левой факторизации и его необходимо знать для ряда приложений.
Упражнения
4.1. В грамматике
S ® abAcDkY
A ® nmDky ½ vaxYe ½ jab
D ® ghYo ½ kh
Y ® f ½ d
устраните правила
A ® nmDky ½ vaxYe ½ jab
D ® ghYo ½ kh
и проведите декомпозицию относительно Y. Подсчитайте количество правил результирующей грамматики и грамматики до проведения преобразований.
4.2. Исключите тупики из следующих грамматик:
(а)
S ® aBcD ½ kLMp L ® f M
B ® cLpDq ½ pDc ½ f M ® Lk ½ pMLc
D ® f Dr ½ f pq K ® r F
F ® abc ½ ab
(б)
S ® AB ½ BC ½ kL A ® aA ½ bL ½ c
B ® BS ½ AL L ® cB ½ j ½ p
C ® QS ½ dC Q ® qQ ½ aC
M ® xN ½ yM ½ zS ½ h N ® xC ½ v ½ wM
(в)
S ® BA ½ CB ½ AL C ® QS ½ dC
A ® aA ½ bB ½ cC Q ® qQ ½ aC
B ® BS ½ AL ½ g M ® xN ½ yM ½ zS ½ h
L ® cB ½ jC ½ p N ® xC ½ v ½ wM
4.3. Устраните аннулирующие правила из следующих грамматик:
(а)
S ® abCDe ½ Kp
C ® dSde ½ e
D ® dD ½ DD ½ e ½ f K ½ e
K ® e ½ mcf
(б)
S ® aSbS ½ bSaS ½ e
(в)
S ® ABC A ® BB ½ e
B ® CC ½ a C ® AA ½ b
4.4. Устраните цепные правила из грамматики
E ® E+T ½ T
T ® T * F ½ F
F ® (E) ½ a
4.5. Найдите приведенную грамматику, эквивалентную грамматике
S ® A ½ B A ® C ½ D
B ® D ½ E C ® S ½ a ½ e
D ® S ½ b E ® S ½ c ½ e
4.6. Устраните левую рекурсию в следующих грамматиках:
(а)
E ® E+T ½ E-T ½ T ½ -T
T ® T * F ½ T / F ½ F
F ® (E) ½ a
(б)
S ® AB
A ® Aa ½ Ab ½ d ½ e
B ® qK ½ rB ½ Bf ½ Bg
K ® vS ½ w
Глава 5. СВОЙСТВА АВТОМАТНЫХ
5.1. Общий вид цепочек А-языков и КС-языков.
5.2. Операции над языками.
5.2.1. Операции над КС-языками.
5.2.2. Операции над А-языками.
5.2.3. Операции над К-языками.
5.3. Выводы для практики.
5.4. Неоднозначность КС-грамматик и языков.
Упражнения
В этой главе мы исследуем некоторые из основных свойств А- и КС-языков. Упомянутые здесь результаты образуют малую долю огромного богатства знаний об этих языках. Часть свойств этих языков уже были рассмотрены в главах 1-4. Ниже мы обсудим общий вид цепочек этих языков, неоднозначность КС-грамматик и КС-языков, некоторые операции, относительно которых замкнуты классы А- и КС-языков.
5.1. Общий вид цепочек А-языков и КС-языков
Мы хотим получить характеристику цепочек А-языков, которая будет полезна для доказательства того, что некоторые языки не являются автоматными. Следующую теорему об общем виде цепочек А-языков называют теоремой о “разрастании”, потому что она в сущности говорит о том, что если даны А-язык и достаточно длинная цепочка в нем, то в этой цепочке можно найти непустую подцепочку, которую можно повторить сколько угодно раз (т.е. она “разрастается”), и все полученные таким образом “новые” цепочки будут принадлежать тому же А-языку. С помощью этой теоремы часто приводят к противоречию предположение о том, что некоторый язык является автоматным.
Теорема 5.1. Пусть L - А-язык. Существует такая константа p, что если y Î L и ½y½³ p, то цепочку y можно записать в виде abg, где 0 <½b½£ p и ab ig Î L, для всех i ³ 0.
Доказательство. Если L - конечный язык, то положим константу p больше длины самой длинной цепочки языка L, тогда ни одна из цепочек языка не удовлетворяет условиям теоремы и она верна. В противном случае, пусть
M = (Q, S, d, q0, F) - конечный автомат с n состояниями и L(M) = L. Пусть p = n. Если y Î L и ½ y ½ ³ n, рассмотрим последовательность конфигураций, которую проходит автомат M, допуская цепочку y. Так как в этой последовательности, по крайней мере, n+1 конфигурация, то найдутся две конфигурации с одинаковыми состояниями. Поэтому должна быть такая последовательность тактов, что
(q 0, abg) ú¾* (q 1, bg) ú¾ k (q 1, g) ú¾* (q 2, e)
для некоторого q 1 и 0 < k £ n. Отсюда 0 <½b½£ n.
Но тогда для любого i > 0 автомат может проделать следующую последовательность тактов:
(q 0, ab i g) ú¾* (q 1, b i g)
(q 1, b i g) ú¾ + (q 1, b i-1 g)
..............
(q 1, b 2 g) ú¾ + (q 1, bg)
(q 1, bg) ú¾ + (q 1, g)
(q 1, g) ú¾* (q 2, e).
Для случая i = 0 все еще очевиднее:
(q 0, ag) ú¾* (q 1, g) ú¾* (q 2, e).
Так как abg Î L, то и ab i g Î L, для всех i ³ 0. š
Эта теорема обычно используется для доказательства того, что некоторые выбранные цепочки не являются цепочками А-языка и, следовательно, не могут быть определены А-грамматиками.
Следствие 5.1. Язык L, состоящий из цепочек x n y n, не является автоматным языком.
Допустим, что он автоматный. Тогда для достаточно большого n цепочка x n y n может быть представлена в виде abg, причем b ¹ e и ab i g Î L для всех i ³ 0.
Если b = x...x или b = y...y, то ag = ab 0 g Ï L, так как количество символов x и y в цепочке ag различно. Если b = x...xy...y, то abbg = ab 2g Ï L, так как в цепочке abbg символы x и y будут перемешаны. Полученное противоречие доказывает, что L - не является А-языком. š
Следствие 5.2. Язык арифметических выражений не является А-языком, так как он может содержать произвольное количество вложенных скобок, причем количество открывающих скобок совпадает с количеством закрывающих. Аналогично не является А-языком любой язык, содержащий вложенные конструкции типа фигурных скобок в языке C, begin - end, repeat - until и т.п. Каждая конечная А-грамматика, порождающая подобные конструкции, будет выводить и цепочки с неравным количеством открывающих и закрывающих скобок. Тем не менее, анализировать подобные цепочки можно и с помощью автоматного подхода. При этом, в синтаксисе языка допускается произвольное количество открывающих и закрывающих скобок, а контроль их парности возлагается на семантические подпрограммы. š
Прежде чем рассматривать теорему о разрастании КС-языков, примем без доказательств следующую теорему.
Теорема 5.2. Для любой КС-грамматики, которая не допускает вывода вида А Þ+ aАb,
где ½a½> 0 и ½b½> 0, можно построить эквивалентную А-грамматику. š
Иными словами, любой язык, который при описании КС-грамматикой не содержит самовставляемых нетерминалов, включает только одностороннюю рекурсию, при выводе наращивает цепочку в одну сторону, неважно, влево или вправо, является автоматным языком.
Теорема 5.3. Для любого КС-языка L существует постоянная p такая, что если y Î L и ½y½ > p, то y = abgjl, где b¹e, j¹e и ab igj il Î L для любого i³0.
Доказательство. Аналогично с теоремой 5.1 рассмотрим только случай бесконечных языков.
Рассмотрим в бесконечном КС-языке L бесповторные деревья вывода, то есть такие, у которых ни на одной ветви нет повторяющихся нетерминалов. Таких деревьев конечное число. Максимальная высота бесповторного дерева
v - равна количеству нетерминалов грамматики. Если максимальная длина правых частей правил грамматики равна b, то максимальная длина цепочки, выводимой бесповторными деревьями, будет не более bv. Положим p = bv. Рассмотрим цепочку с длиной больше p и ту ветвь ее дерева вывода, в которой нетерминалы повторяются.
Рассмотрим поддеревья D1 и D2, начинающиеся с повторяющегося нетерминала A. Если D1 заменить на D2, то получим дерево вывода цепочки agl. Подвеска дерева D2 к корню D1 возможна, так как после нее корень дерева D1 соответствует применению того же правила, что и корень дерева D2. Таким образом, полученное дерево вывода является деревом вывода в той же грамматике.
Если D2 заменить на D1, то получим дерево вывода цепочки ab 2gj 2l. Дерево D1, которым заменяется D2, содержит в себе D2 в качестве поддерева. Заменив его на D1, получим дерево вывода цепочки ab 3gj 3l. Продолжая такие замены, можно получить любую из цепочек ab igj il. š
Пример 5.1. Пусть дана КС-грамматика с правилами:
S ® aAp
A ® cAc ½ cbAb ½ d.
Максимальная высота бесповторного дерева здесь равна 2, а максимальная длина цепочки, выводимая бесповторным деревом, равна 3 (бесповторно выводится только цепочка adp). На рис. 5.1 (а) показано дерево вывода цепочки acbdbp. Здесь принято следующее: a = a, b = cb, g = d, j = b, l = p. На рис. 5.1 (б) показана замена поддерева D1 на D2, а на рис. 5.1 (в) замена D2 на D1. †
Теорема 5.3, как и теорема 5.1, чаще всего используется для доказательства того, что некоторые цепочки не принадлежат КС-языкам.
Следствие 5.3. Язык L, состоящий из цепочек x ny nz n, не является КС-языком.
Действительно, разделяя эту цепочку на пять частей abgjl любым возможным способом, мы увидим, что либо agl Ï L из-за неравного количества символов x, y и z, либо ab 2gj 2l Ï L из-за перемешивания символов внутри цепочки.
Следствие 5.4. Языки программирования в общем случае не являются КС-языками.
Например, в языках программирования каждая конкретная процедура имеет одно и то же число аргументов в каждом месте, где она упоминается. Можно показать, что такой язык не контекстно-свободен, отобразив множество программ с тремя вызовами одной и той же процедуры на не контекстно-свободный язык { 0 n 10 n 10 n | n³0 }.
В этих языках встречаются и другие явления, характерные для не КС-языков. Так язык, требующий описания идентификаторов, длина которых может быть произвольно большой до их использования, не контекстно-свободен. Правил КС-грамматик для описания таких явлений явно недостаточно.
Однако на практике все языки программирования считаются КС-языками. В компиляторах идентификаторы обычно обрабатываются лексическим анализатором и свертываются в лексемы прежде, чем достигают синтаксического анализатора. Контроль за их описанием до использования, так же как и подсчет числа параметров в процедуре и т.п., возлагается на семантические подпрограммы, не входящие в собственно синтаксический анализ. Это позволяет существенно упростить синтаксис языков программирования.
5.2. Операции над языками
По определению язык - это множество цепочек, следовательно, над языками можно выполнять операции, правомерные как для множеств, так и для цепочек (строк символов). Определим некоторые из них.
Язык L называется объединением языков L1 и L2 (L= L1 È L2), если он содержит все цепочки из L1 вместе со всеми цепочками из L2. Формально
L = {a½a Î L1 или a Î L2}.
Язык L называется пересечением языков L1 и L2 (L= L1 Ç L2), если он содержит все цепочки, принадлежащие как L1, так и L2. Формально L={a½a Î L1 и a Î L2}.
Язык L называется разностью языков L1 и L2 (L= L1 \ L2), если он содержит все цепочки из L1, которые не принадлежат L2. Формально L={a½aÎL1 и aÏL2}.
Язык L называется дополнением языка L1 (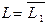 ), если он содержит все цепочки из некоторого универсального языка L2, которые не принадлежат L1. Формально L={a½a Ï L1}.
), если он содержит все цепочки из некоторого универсального языка L2, которые не принадлежат L1. Формально L={a½a Ï L1}.
Язык L называется конкатенацией (сцеплением) языков L1 и L2 (L= L1 L2), если он содержит попарные конкатенации всех возможных цепочек из L1 и L2. Формально L={ab½a Î L1 и b Î L2}.
Итерация языка L, обозначаемая L *, определяется следующим образом:
(1) L0 = { e },
(2) Ln = LLn-1 для n ³ 0
(3) L * =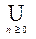 Ln.
Ln.
Позитивная итерация языка L, обозначаемая через L+, - это язык Ln. Заметим, что L+ = LL * = L * L и L * = L+ È { e }.
Язык L называется подстановкой языка L2 в язык L1 вместо терминала a (L=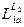 ), если он содержит все цепочки языка L1, в которых терминал a заменен на все возможные цепочки языка L2.
), если он содержит все цепочки языка L1, в которых терминал a заменен на все возможные цепочки языка L2.
Обращение языка L, обозначаемое LR, - это язык, содержащий все обращенные цепочки исходного языка. Формально L = {w R ½w Î L}.
Прежде чем обсуждать практические аспекты данных определений, поговорим о том, как построить грамматику языка, полученного в результате операций над языками, и как определить ее тип.
5.2.1. Операции над КС-языками
Нетрудно показать, что целый ряд операций над КС-языками дает в результате также КС-язык.
Теорема 5.4. КС-языки замкнуты относительно операций объединения, конкатенации, итерации, подстановки и обращения.
Доказательство. Пусть L1=L(G1) и L2=L(G2) два контекстно - свободных языка, определяемых КС-грамматиками G1=( VT1,VN1,R1,S1 ) и G2=( VT2,VN2,R2,S2 ) соответственно. Проиндексируем нетерминалы грамматики G1 индексом 1, а нетерминалы G2 - 2, с тем чтобы никакие имена различных грамматик не совпадали.
Если объединить нетерминалы, терминалы, правила исходных грамматик и добавить к последнему объединению правило
S ® S1 ½ S2,
где S - аксиома новой результирующей грамматики, то мы, очевидно, получим КС-грамматику, определяющую объединение языков L1 и L2. Действительно, индексирование нетерминалов не изменяет класса исходных грамматик, точно так же как и объединение их правил и добавление контекстно-свободной продукции
S ® S1 ½ S2.
Последняя продукция и обеспечивает порождение всех цепочек языка L1 по первой альтернативе правила и всех цепочек языка L2 по второй его альтернативе.
Таким образом, L= L1 È L2 = L(G), где
G=(VT1 ÈVT2,VN1ÈVN2,R=R1ÈR2È{S®S1|S2},S ) -
КС-грамматика, определяющая объединение языков L1 и L2.
Точно так же можно показать, что КС-грамматика
G=(VT1 ÈVT2,VN1ÈVN2,R=R1ÈR2È{S®S1S2},S )
определяет конкатенацию языков L1 и L2 (L(G)= L1 L2).
Если к правилам P1 исходной грамматики G1 добавить правило
S ® SS1 ½ e,
считая S начальным символом новой КС-грамматики G, то грамматика G будет определять итерацию языка L1 - L1 *. Если же к R1 добавить правило
S ® SS1 ½ S1 или правило S ® S1S ½ S1, или правило S ® SS ½ S1,
то полученная КС-грамматика G будет определять позитивную итерацию L1 +.
Если во всех правилах грамматики G1 вида A ® j ay заменить терминал a на S2 - аксиому грамматики G2, то полученная в результате таких преобразований КС-грамматика G будет определять не что иное, как язык L - подстановку языка L2 в язык L1 вместо терминала a: 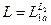 , при этом
, при этом
G=<(VT1 \{a})ÈVT2,VN1ÈVN2,R=R1ÈR2È{S®aS2b}\{S1®a a b },S>.
Для того чтобы получить грамматику, определяющую обращение LR для исходного языка L(G), достаточно обратить левые и правые части правил исходной грамматики G, то есть правила a ® b заменить на правила a R ® b R (в КС-грамматиках правила A ® b заменяются на правила A ® b R). Такие преобразования не изменяют класса КС-грамматик. †
Все рассмотренные преобразования КС-грамматик достаточно очевидны. Рассмотрим на примере только формирование грамматики для обращения языка.
Пример 5.2. Пусть задана грамматика с правилами
S ® aS ½ bB
B ® cB ½ d
Для простоты здесь взята А-грамматика, но ничто не мешает рассматривать ее как КС-грамматику. Цепочки, порождаемые данной грамматикой, состоят из необязательных символов “ а ” в начале цепочки, символа “ b ”, затем необязательных символов “ c ” и символа “ d ” в конце, т.е. цепочка имеет вид
[aaa...]b[ccc...]d,
где квадратные скобки традиционно обозначают необязательный элемент.
Обратим правила заданной грамматики и в результате получим:
S ® Sa ½ Bb
B ® Bc ½ d
Если правила исходной грамматики обеспечивали вывод цепочки слева направо, то полученные правила выводят ее справа налево. Цепочка, порождаемая последней грамматикой, имеет вид d[ccc...]b[aaa...]. †
Теорема 5.5. КС-языки не замкнуты относительно операций пересечения, дополнения и разности.
Доказательство. Языки L1={a n b n c j ½ n ³ 1, j ³ 1} и L2={a j b nc n ½ n ³ 1, j ³ 1} - КС-языки. Первый из них можно определить правилами
S ® XY
X ® aXb ½ ab
Y ® cY ½ c,
а второй
S ® XY
X ® aX ½ a
Y ® bYc ½ bc.
Однако L1Ç L2= {anbncn½n ³ 1} - не КС-язык (см. следствие теоремы 5.3). Таким образом, класс КС-языков не замкнут относительно пересечения.
Отсюда можно также заключить, что класс КС-языков не замкнут относительно дополнения. В силу закона де Моргана (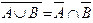 ) любой класс языков, замкнутый относительно объединения и дополнения, должен быть замкнут относительно пересечения. Из теоремы 5.4 известно, что КС-языки замкнуты относительно объединения и предположение об их замкнутости относительно дополнения приводит нас к противоречию с первым доказанным положением данной теоремы.
) любой класс языков, замкнутый относительно объединения и дополнения, должен быть замкнут относительно пересечения. Из теоремы 5.4 известно, что КС-языки замкнуты относительно объединения и предположение об их замкнутости относительно дополнения приводит нас к противоречию с первым доказанным положением данной теоремы.
Для доказательства последнего положения достаточно вспомнить, что дополнение - это, по сути дела, разность множеств. †
5.2.2. Операции над А-языками
Теорема 5.6. Автоматные языки замкнуты относительно операций объединения, конкатенации, итерации, обращения, подстановки, пересечения, дополнения и разности.
Доказательство. Проведем его конструктивно, так же как и в теореме 5.4. Для представления А-грамматик используем графы состояний и в случае операций над двумя языками индексируем нетерминалы исходных грамматик.
Объединение. Пусть даны два А-языка L1=L(G1) и L2=L(G2) и графы состояний грамматик G1 и G2 схематично представлены на рисунках 5.2 (а) и (б), соответственно.
На рис. 5.2 (в) представлена грамматика G, определяющая объединение исходных языков. Для ее построения вводим новый начальный символ S. Если в исходных грамматиках из S i в A i ведет ребро, помеченное терминалом a, то проведем ребро из S в A i и пометим его тем же терминалом a. Выберем новый конечный символ F и все ребра, шедшие в F1 и F2 проведем в F, а F1 и F2 удалим. Вершины S1 и S2 в общем случае удалять нельзя, так как к ним могут идти ребра, но если в S i возвратов нет, то эту вершину (нетерминал) можно удалить (в нашем примере можно удалить вершину S2 вместе с выходящими из нее дугами).
Очевидно, что результирующая грамматика G является А-грамматикой. Зачастую она может быть недетерминированной, но перевод А-грамматики из недетерминированной формы в детерминированную уже был рассмотрен ранее.
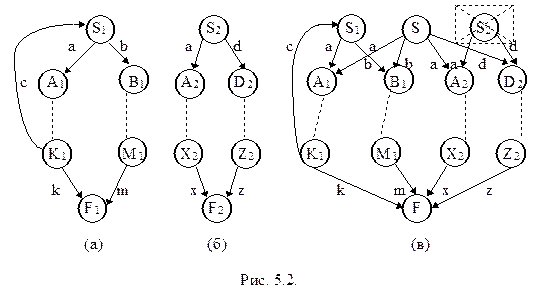
Конкатенация. В этом случае, получение грамматики-результата сводится к склеиванию начальной вершины S2 языка-суффикса с заключительной вершиной F1 языка-префикса, т.е. все ребра, шедшие в F1, направляются в S2, а F1 удаляется (см. рис. 5.3 (а)).
Итерация. Для каждого ребра,идущего из некоторой вершины A исходной грамматики в заключительную вершину F, строится дублирующее его ребро, ведущее из A в начальную вершину S. На рис. 5.3 (б) добавляемые ребра выделены жирной линией.
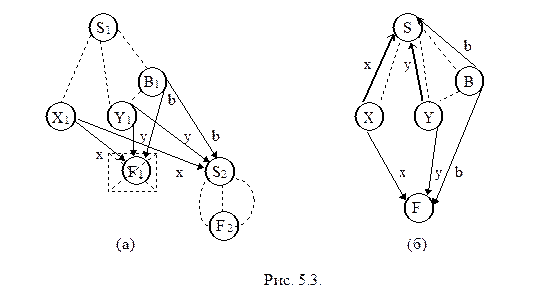
Обращение. На рис. 5.4 (а) представлен граф исходной грамматики. Изменим имя начальной вершины S на S1 и добавим вершину S2. Для всех ребер, выходящих из S1 и входящих в A, добавим дуги, выходящие из S2 и входящие в A (см. рис. 5.4 (б)). Заменим имя заключительной вершины F на имя начальной S, а имя вершины S2 на имя заключительной F и изменим ориентацию ребер. В результате мы получим А-грамматику, определяющую обращение исходного языка. Граф этой грамматики представлен на рис. 5.4 (в).
Заметим, что добавление вершины необходимо только в случае возвратов в начальную вершину исходной грамматики. Если возвратов нет, то достаточно изменить ориентацию ребер и сделать перестановку имен начального и заключительного состояний.

Подстановка. На рис 5.5 (а) представлена грамматика G2 языка L2, который мы хотим подставить вместо терминала a в язык L1 с грамматикой G1, приведенной на рис. 5.5 (б). Возьмем столько экземпляров G2, сколько в G1 имеется ребер, помеченных терминалом a. Нетерминалы в G1 отметим индексом 0, а нетерминалы в i - ом экземпляре G2 индексом i. На место каждого ребра G1, помеченного терминалом a и идущего из A0 в B0, подставим экземпляр G2, т.е. вершину A0 из G2 совместим с вершиной Si, а вершину B0 - с вершиной Fi. Отметим, что при наличии возвратов в начальную вершину грамматики G2 и других ребер, идущих из A0 грамматики G1 и помеченных терминалами, отличными от a, необходимо расщеплять начальную вершину грамматики G2 на две вершины. Одна из них в точности совпадает с исходной, а другая повторяет все выходы исходной начальной вершины, но возвраты в нее опускаются. Именно эту вторую начальную вершину без возвратов и совмещают с A0. Результаты этих преобразований приведены на рис. 5.5 (в), отражающем грамматику языка, полученного в результате указанной подстановки.
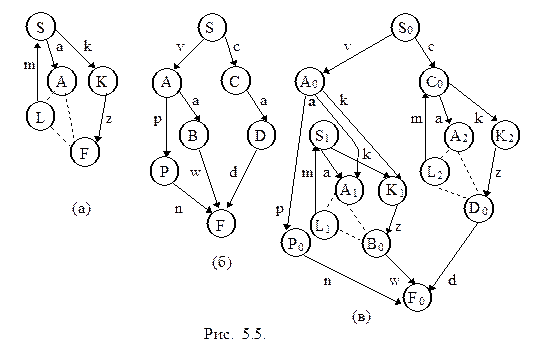
Пересечение. Здесь мы отойдем от принятого выше представления А-грамматик в виде графов состояний и рассмотрим построение грамматики, определяющей пересечение двух А-языков на конкретном примере.
Пример 5.3. Пусть А-язык L1 определяется А-грамматикой
G1=( VT1,VN1,R1,S1 ) и множество R1 - это группа модифицированных правил
S ® aS ½ bC ½ dC
C ® bC ½ cC ½ûë F,
где F - заключительный нетерминал,
и А-язык L2 определяется А-грамматикой G2=( VT2,VN2,R2,S2 ) и
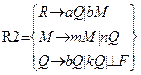
Выполним формальную процедуру операции пересечения.
Определим грамматику G=( VN, VT, R, <SR>) языка L = L1Ç L2. Для того чтобы проконтролировать наше решение, вначале определим вид цепочек как заданных языков, так и языка - результата, благо простота выбранных грамматик позволяет легко это сделать. Цепочки языка L1 могут содержать в начале произвольное количество символов a, обязательный символ b или d, затем, возможно, серию символов b и (или) c и в завершении символ ûë. Схематично цепочку языка L1 можно представить в виде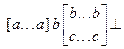 , где квадратные скобки ограничивают необязательные части строки, многоточие обозначает произвольное количество символов, а две строки - произвол в выборе символов. Цепочки языка L2 имеют вид
, где квадратные скобки ограничивают необязательные части строки, многоточие обозначает произвольное количество символов, а две строки - произвол в выборе символов. Цепочки языка L2 имеют вид  или
или 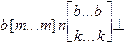 , а цепочка результирующего языка -
, а цепочка результирующего языка -  .
.
Заметим, что S Í S1Ç S2. Построение грамматики-пересечения напоминает построение детерминированной формы А-грамматики. В качестве элементов нового множества нетерминалов выбираются пары нетерминалов исходных грамматик типа <SR>, <SQ>, <SM>, <CM>, <CQ> и т.п. В результате построения правил грамматики-пересечения часть этих нетерминалов может быть исключена как внутренние или внешние тупики. Схема построения правил новой грамматики состоит в том, что рассматриваются только те пары нетерминалов и те их альтернативы, которые имеют одни и те же терминалы в качестве продолжения цепочки. В результате мы получим грамматику
<SR> ® a<SQ> ½ b<CM>
<SQ> ® b<CQ>
<CQ> ® b<CQ> ½ûë <FF>
Заметим, что нетерминал <CM> не имеет общего продолжения, является внешним тупиком и его можно исключить вместе с правилом <SR> ® b<CM>. †
То есть операция пересечения L=L1ÇL2 определяется следующим образом:
G=<VT1ÇVT2,VN={<A1A2>,A1ÎVN1,A2ÎVN2},<S1S2>,R={<AB>®a<CD>, если в исходных грамматиках G1 присутствует правило вида A®aC: A,CÎVN1, в грамматике G2 B®aD, B,DÎVN2} >.
В результате такого построения получается язык, включающий множество цепочек, принадлежащих языку L1 и L2. Действительно:
а) если jÎL1,L2 и j=ab…f, то отсюда следует, что существует вывод в L1 и L2: S1aA1bB1…fF1 в G1 и вывод в G2: S2aA2bB2…fF2.
По построению, если существуют такие правила вывода, то в L появится правило вида <S1S2>a<A1A2>…f<F1F2>. Если есть такой вывод, то цепочка j принадлежит языку L.
б) Проводя аналогичные рассуждения в обратном порядке, получим, что любая цепочка, принадлежащая языку L, принадлежит языкам L1 и L2. †
Рассмотрим еще один пример:
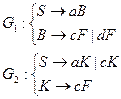
В результате выполнения операции пересечения получим:
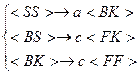 – тупик
– тупик
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 1100; Нарушение авторских прав?; Мы поможем в написании вашей работы!