КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Особенности организации современных процессоров
|
|
|
|
Элементной базой современных компьютеров являются сверхбольшие ИС (СБИС). СБИС выпускаются трех типов:
· СБИС с аппаратной реализацией алгоритмов обработки данных. Это микропроцессоры различных типов: универсальные, сигнальные, а также микроконтроллеры;
· микросхемы памяти: статистической (SRAM) и динамической (DRAM);
· программируемые логические ИС (ПЛИС).
Быстродействие процессоров можно повысить:
1. за счет увеличения тактовой частоты (т.е. за счет уменьшения продолжительности такта Т: tком=n*T);
2. за счет параллельной (в частности, конвейерной) обработки (организации работы), при которой как бы уменьшается количество тактов n на выполнение команд программы;
3. за счет уменьшения времени обращения к памяти.
Увеличение тактовой частоты достигается в основном за счет совершенствования технологии СБИС, т.е. за счет уменьшения размеров электронных элементов, длины проводников, напряжения питания.
Повышение быстродействия процессоров на уровне системы команд обеспечивается различными способами.
Операции (и команды) процессора делятся на скалярные и векторные. Скалярные операции (и команды, их возбуждающие) – это операции, в которых операнды и результаты являются скалярами (числами).
Для обработки массивов используются векторные операции (и команды, их возбуждающие). В них операнды и, возможно, результат являются массивом (вектором) чисел. Пример – умножение элементов двух массивов (векторов): очередные два элемента из двух массивов перемножаются, их произведение суммируется с содержимым заданного регистра. Затем модифицируются адреса ячеек памяти для извлечения двух других очередных элементов массивов и т. д. Эта последовательность действий (умножений, сложений, модификаций адресов элементов) повторяется заданное число раз по счетчику, определенному в теле команды.
Внедрение векторных команд в систему команд процессора повышает скорость обработки за счет уменьшения затрат времени на адресацию, выборку и дешифрацию команд: вместо нескольких обращений к памяти за командами – одно (за одной векторной командой) на весь массив исходных данных.
Следует отметить, что использование векторных команд требует от программиста написания векторной программы, что равносильно разработке параллельной программы (параллельному программированию).
При сохранении последовательного программирования для ускорения обработки используются суперскалярные процессоры. В них увеличение быстродействия достигается за счет применения конвейерной обработки, при которой в одном такте вырабатывается несколько скалярных результатов.
Повышение быстродействия при конвейерной организации обеспечивается не только за счет совершенствования самих конвейеров, но и путем их эффективной загрузки, т.е. за счет уменьшения простоев.
Эффективная загрузка параллельно работающих конвейеров обеспечивается либо аппаратурой процессора, либо компилятором, либо совместно аппаратурой и компилятором.
При компиляции из последовательной программы извлекается информация о параллелизме. Эта информация в явном виде указывается процессору и используется им для эффективного управления вычислительным процессом.
В случае аппаратного выделения параллелизма специальные средства процессора сами выделяют элементы параллелизма из последовательной программы в процессе ее выполнения – в динамике. При этом в силу ограниченных возможностей аппаратуры (по сравнению с компилятором) используются более простые формы параллелизма – в основном естественного. Пример простейшего естественного параллелизма – это целочисленная обработка и обработка с плавающей запятой. Использование этого параллелизма привело к появлению процессоров с так называемой разнесенной структурой (архитектурой) – decoupled architecture (рисунок 4.10). Процессор с разнесенной архитектурой состоит из двух субпроцессоров, каждый из которых управляется собственным потоком команд. Условно их называют адресным А-процессором и исполнительным Е-процессором. А-процессор выполняет все целочисленные (прежде всего адресные) вычисления и формирует обращения к памяти по чтению и записи. Е-
 |
процессор реализует вычисления с плавающей запятой.
Данные, извлекаемые из памяти, разделяются по типам и помещаются в соответствующую очередь (FIFO-очередь) адресов АА (целочисленные данные) или АЕ - очередь данных с плавающей запятой. Если очередь АЕ пуста, то Е-процессор ждет поступления данных в очередь АЕ от А-процессора. Результаты обработки из Е-процессора помещаются в очередь результатов ЕА для записи в память по адресу из очереди адресов записи AW. Адрес для записи результата вычисляется А-прроцессором и отправляется в очередь адресов для записи AW, не дожидаясь, пока результат обработки поступит в очередь ЕА. А-процессор, выбирая первые элементы из очередей AW, ЕА, организует их в пары А,D и отправляет в память (на запись). Если одна из очередей пуста (или обе вместе), то запись в память приостанавливается.
При чтении из памяти А-процессор отправляет данные либо в очередь АА (целочисленные данные), либо в очередь ЕА (плавающая запятая).
Расщепление последовательной программы на потоки команд для А- и Е-процессоров осуществляется либо на уровне компилятора, либо в процессоре специальным блоком–расщепителем.
Обмен с памятью в процессорах с расщепленной архитектурой организуется путем посылки транзакций – входных сообщений, несущих информацию не только об адресах ячеек и направлении обмена (ЧТ, ЗП), но и сами данные, их назначение (тип данных).
Интерфейс с памятью посредством транзакций чтения и записи позволяет поставить между процессором и памятью коммутационную среду, с помощью которой можно переходить к построению (организации) многопроцессорных ВК.
Способы уменьшения времени обращения к памяти. Первый способ – многоуровневая иерархическая организация памяти:
· регистры (десятки, сотни), время обращения – 1 такт ЦП;
· КЭШ первого уровня (L1) (десятки KB), время обращения – 1-2 такта ЦП;
· КЭШ второго уровня (L2) (сотни KB), время обращения – 3-5 такта ЦП, и т.д.
· Основная память (десятки, сотни MB, ГВ), время обращения – десятки тактов ЦП.
Использование буферной памяти небольшого объема и высокого быстродействия позволяет существенно сократить количество медленных обращений к ОП, подменяя часть из них обращениями к быстрой буферной памяти. За счет чего это происходит? За счет размещения активных фрагментов информации (команд и данных) в буфере на разных уровнях. Такая организация памяти существенно уменьшает простои процессора в ожидании данных. Пока процессор обрабатывает блоки данных, размещенные в буфере, производится обмен блоками (программ и данных) между уровнями памяти, т. е. Обеспечивается совмещение во времени обработки в процессоре с пересылкой блоков между уровнями памяти.
Эффект уменьшения времени обращения к памяти будет тем больше, чем больше время обработки информации, расположенной в буфере, по сравнению с временем пересылки между ОП и буфером. Этот эффект базируется на свойстве локальности вычислительных процессоров, которое заключается в том, что процессор обычно многократно использует одни и те же ячейки для выработки некоторого результата (пример – итерационный цикл).
Второй способ – расслоение памяти. Этот способ также базируется на свойстве локальности адресов: при обращении к памяти процессор обычно генерирует естественную последовательность соседних адресов А, А+1, …, А+К-1 (К – длина цепочки адресов). В этом случае возможно К параллельных одновременных обращений в память по адресам, принадлежащим различным блокам памяти, состоящей из К блоков.
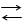 Очередной шаг эволюции – использование сокращенного набора команд (RISC). Дело в том, что практика применения компиляторов показала, что в процессе трансляции чаще всего используются простые команды типа R,R ®R и R память. Это означает, что компиляторы (их авторы) не в состоянии эффективно использовать сложные команды. Поэтому созрела идея использования сокращенного набора простых команд, которая и была реализована в RISC-процессорах. К такому решению разработчиков подтолкнуло также появление конвейерных процессоров (суперскалярных). Оказалось, что для RISC-команд конвейер организуется проще и эффективнее, чем для CISC-команд.
Очередной шаг эволюции – использование сокращенного набора команд (RISC). Дело в том, что практика применения компиляторов показала, что в процессе трансляции чаще всего используются простые команды типа R,R ®R и R память. Это означает, что компиляторы (их авторы) не в состоянии эффективно использовать сложные команды. Поэтому созрела идея использования сокращенного набора простых команд, которая и была реализована в RISC-процессорах. К такому решению разработчиков подтолкнуло также появление конвейерных процессоров (суперскалярных). Оказалось, что для RISC-команд конвейер организуется проще и эффективнее, чем для CISC-команд.
Конвейерная организация (обработка) породила проблемы, связанные с эффективной загрузкой конвейеров (с уменьшением простоев). Эта проблема (эффективной загрузки конвейеров) решается либо компилятором, устанавливающим очередность запуска команд в конвейер и вставляющим пустые такты (команды NOP) при невозможности запуска очередной команды, либо специальной аппаратурой процессора, отслеживающей зависимости между командами и устраняющей конфликты.
CISC-процессоры отличаются сложностью форматов и переменной длиной команд и, следовательно, сложным устройством управления, что препятствует повышению тактовой частоты. Поэтому переход на RISC-команды позволяет увеличивать тактовую частоту: блоки конвейеров проще, время их работы меньше, такт работы конвейера меньше, частота процессора выше.
Недостаток RISC-процессоров – большой объем (длина) машинных программ.
Развитие архитектуры процессоров происходит при постоянном стремлении обеспечить преемственность ПО. Сохранение преемственности и повышение быстродействия процессоров противоречат друг другу.
Проблема повышения быстродействия в рамках CISC-процессоров решается путем использования в них RISC-ядра и аппаратного транслятора CISC-команд в RISC-команды. Другими словами, в CISC-процессор встраивается RISC-ядро и аппаратный транслятор, превращающий CISC-команды в команды (в последовательности команд) RISC-ядра. Такой подход используется, в частности, в современных процессорах фирмы Intel.
Повышение производительности путем переключения контекста. Современные компьютеры обычно используют мультипрограммный режим работы. Время переключения процессора с одной задачи на другую, естественно, должно быть минимальным. Современные операционные системы при обработке прерываний, вызове подпрограмм, при переключении задач активно используют переключение контекста процессора. Уменьшение времени переключения контекста можно обеспечить либо за счет уменьшения количества регистров, сохраняемых в памяти, либо за счет аппаратной поддержки сохранения (вместо программной). В этом случае каждой активизируемой программе предоставляется свое подмножество регистров. В процессорах SPARC компании SUN, например, используются 192 регистра, разделенных на 8 групп по 32 регистра в каждой (с перекрытием окон): регистры с номерами 24-31 одной группы одновременно являются регистрами с номерами 0-7 другой группы (окна). В этом случае сохранения регистров в памяти фактически не требуется.
Концепция открытых систем. Со временем постоянно растет сложность решаемых задач и, как следствие, растет сложность программных систем. Разнообразие типов (архитектур) процессоров ограничивает область применения сложных программных систем, т. к. для процессоров других типов их приходится разрабатывать заново. Поэтому с целью расширения области применимости сложных и дорогостоящих программных систем предпринимались попытки стандартизации (унификации) архитектуры процессоров. Однако на уровне машинных команд этого сделать так и не удалось (в силу конкуренции фирм и различного назначения процессоров). Аналогичные попытки были сделаны на уровне ассемблера, языков высокого уровня, интерфейса прикладных программ с операционными системами.
Отсутствие стандартизации не позволяет создавать новые программные системы простым способом – путем конструирования из существующих программ, прошедших апробацию в различных условиях применения большим количеством независимых пользователей. На пути к такой стандартизации необходимо пройти два обязательных этапа:
- решение проблемы адекватного описания системы,
- решение проблемы тестирования системы на соответствие этому описанию. Тестирование должно быть доказательным.
Обе эти проблемы до сих пор не решены. Свидетельством тому являются известные примеры ошибок в микропроцессорах известных компаний (Intel в том числе), а также не декларированные возможности как микропроцессоров, так и операционных систем.
Один из подходов комплексного решения проблемы комплексного решения проблемы стандартизации средств сводится к формулировке концепции открытых систем. Открытая система – это система, разработанная с использованием стандартных средств: интерфейсов, протоколов и форматов данных, переносимых по принципам построения.
Переносимость – это свойство, заключающееся в возможности исполнения программы в исходных кодах на различных аппаратных средствах (платформах) под управлением (в среде) различных ОС.
Кроме того, открытые системы должны обладать свойством взаимодействия. Взаимодействие – это свойство (открытой) системы, обеспечивающее способность обмена информацией с автоматическим восприятием форматов и семантики данных (например, в сети Internet).
Третье свойство открытых систем – масштабируемость, которая обеспечивает возможность исполнения программ на различных ресурсах (объем памяти, количество и быстродействие процессоров) с пропорциональным изменению ресурсов значением показателей эффективности.
Одна из известных попыток реализации концепции открытых систем предпринята в проекте стандарта ANDF (Architecture Nentral Distribution Format), который направлен на обеспечение переносимости программ. Для этого компиляцию предлагается делать в два этапа. На первом этапе исходный текст программы вместе с обобщенными описаниями типов данных транслируется в обобщенные декларации интерфейсов открытых систем – API. Результатом является программа в терминах абстрактной алгебры. Текст такой программы может быть подвергнут формальной проверке (тестированию) и, если необходимо, преобразованию. Тем самым обеспечивается адекватное описание системы и исчерпывающее ее тестирование. На втором этапе трансляции генерируется программа под конкретную архитектуру процессора.
Второй подход – использование Java-технологии (компания SUN). В основу положена так называемая виртуальная Java-машина со стандартными спецификациями (архитектурой).
Java-процессор имеет стековую архитектуру, поэтому большинство его команд имеют длину в один байт. Это позволяет иметь минимальную длину программ. (Стековая архитектура процессоров давно используется в отечественных ВК “Эльбрус”). Технология виртуальных Java-процессоров активно используется в сети Internet. Открытые программные системы на основе Java-процессоров, накапливаемые в недрах сети Internet, позволяют конструировать системы из уже существующих программных продуктов.
Недостаток Java-машин – низкая производительность, которая компенсируется использованием RISC-ядра в современных процессорах. В этом случае программа на первом этапе транслируется (компилируется) в язык Java-процессора, а на втором этапе в процессе выполнения Java-программы транслируется (интерпретируется аппаратурой процессора) в совокупность команд RISC-ядра.
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 913; Нарушение авторских прав?; Мы поможем в написании вашей работы!