КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Эволюция способов организации процессоров
|
|
|
|
Известно, что существенное, практически неограниченное повышение быстродействия компьютеров можно получить путем распараллеливания вычислительных процессов в мультипроцессорных ВК. Однако это сложный путь и, следовательно, дорогой. Более простой и дешевый – повышение быстродействия традиционных однопроцессорных ВК. Основное преимущество (кроме простоты архитектуры) таких ВК объясняется еще и требованиями преемственности ПО, и простотой программирования (разработки программ) для них.
Основное преимущество современных суперскалярных процессоров объясняется тем, что они обеспечивают рост быстродействия путем распараллеливания обработки данных при сохранении традиционных, привычных, простых последовательных программ и языков программирования.
В этом случае компиляторы и аппаратура процессора сами, без вмешательства программиста, обеспечивают извлечение параллелизма из последовательной программы (алгоритма) и используют эту информацию для эффективной загрузки параллельно работающих устройств (конвейеров) процессора.
Извлечение параллелизма осуществляется следующим образом. Текст последовательной программы отражает статическую структуру алгоритма. С целью распараллеливания в процессе выполнения с конкретным набором входных данных программа должна быть представлена динамической структурой, то есть множеством последовательностей инструкций в порядке их исполнения, каждая из которых (из последовательностей) запускается в свой конвейер (исполнительное устройство). В конвейерах выполняется одновременно несколько команд, причем иногда в порядке, отличном от заданного в последовательной программе (в статической структуре программы). Это переупорядочение может быть выполнено компилятором заранее или аппаратными средствами процессора во время исполнения программы.
Таким образом, в суперскалярных процессорах используется распараллеливание уровня команд (ILP). На этом уровне компиляторы и процессоры, выражаясь математическим языком, преобразуют полностью упорядоченное множество команд исходной последовательной программы в частично упорядоченное множество, структурированное зависимостями по данным и управлению. Другими словами, преобразуют статическую структуру программы в динамическую. Главной целью такого преобразования является повышение степени параллелизма исполнения команд.
Главное препятствие высокопараллельного исполнения команд – зависимости по управлению, которые должны быть установлены, определены (предсказаны) заранее, прежде чем будут выполнены все последующие за переходом команды.
Как создается динамическая структура в процессоре? В процессе выполнения программы процессор как бы продвигает окно исполнения по статической структуре программы (в фон Неймановском процессоре окно узкое – шириной в одну команду). Команды в окне могут исполняться параллельно, если между ними нет зависимостей (они являются функционально совместимыми). Зависимые команды нельзя выполнять параллельно, поэтому производительность конвейера падает.
Для устранения зависимостей по управлению, причинами которых являются команды перехода, используется метод предсказания: блок предсказаний процессора предсказывает переход и процессор начинает исполнять команды предсказанного перехода (спекулятивное исполнение). Если предсказание оказывается ошибочным, то состояние процессора восстанавливается на момент предсказания перехода – отсюда возможные потери времени.
Команды в окне исполнения могут быть также зависимыми по данным. Это означает, что их можно выполнять только в том порядке, в котором они заданы в последовательной программе.
В общем случае различают 4 вида зависимостей по данным:
- RAR – чтение после чтения (фактическое отсутствие зависимости);
- WAR – запись после чтения;
- WAW – запись после записи;
- RAW – чтение после записи.
Действительной зависимостью является только RAW, так как в этом случае возникает возможность прочитать из регистра (ячейки) старые данные, а не новые, если в результате переупорядочения в конвейерах, команда записи будет выполнена позже чтения (что недопустимо).
“Лишние” зависимости типа WAR, WAWдолжны быть выявлены и устранены (для эффективной загрузки конвейеров). Действительно, зависимость WAR состоит в том, что из регистра (ячейки) сначала должна читаться информация (например, адрес из регистра DX в командах IN, OUT в процессорах типа Intel), а затем в тот же регистр (ячейку) заносится другая информация – ввиду, например, нехватки регистров, или ввиду низкого качества компилятора, который генерирует не оптимизированный программный код (а также неопытностью программиста).
Зависимость WAW состоит в том, что один и тот же регистр используется для записи разных результатов (например, регистр DX, в который сначала заносится адрес одного порта, а затем другого). От зависимостей типа WAW также можно избавиться.
После устранения лишних зависимостей по данным и управлению команды в окне можно исполнять параллельно.
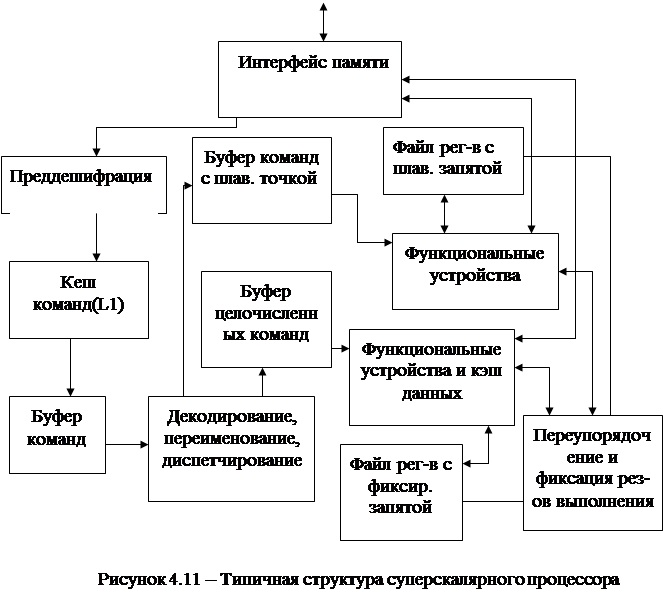
Типичная структура суперскалярного процессора представлена на рисунке 4.11. Основные блоки:
1) блок предварительной выборки команд (в окно исполнения) и предсказания перехода (с КЭШ – памятью команд);
2) блок декодирования команд (в окне);
3) блок анализа зависимостей между командами, переименования регистров и диспетчеризации;
4) блоки (файлы) регистров с фиксированной и плавающей запятой;
5) блок обрабатывающих устройств (конвейеров) и КЭШ данных;
6) блок переупорядочения результатов выполненных команд;
7) блок управления памятью (интерфейс памяти).
Предсказание переходов. За один такт с конвейеров процессора сходит несколько результатов (несколько команд), следовательно, на вход конвейеров также необходимо загружать несколько команд. Это означает, что за один такт из памяти необходимо извлекать несколько команд. С этой целью, в частности, между основной (медленной) памятью и блоками обработки ставятся (многоуровневые) раздельные кэш данных и команд.
Для уменьшения потерь времени, связанных с отсутствием требуемых команд в кэш команд (вызванным промахами при обращениях к кэш-памяти – подробности в 6 главе), в состав системы кэширования вводятся средства предсказания переходов.
Промахи при обращениях к кэш-команд возникают в случае команд ветвлений. Исполнение команд ветвлений состоит из следующих этапов:
1) распознавание (декодирование) команды условного перехода (отделение от команд других типов);
2) анализ условия перехода;
3) вычисление адреса перехода;
4) 
передача управления, если условия выполнено.
На каждом из них можно использовать приемы, повышающие производительность.
1. Для быстрого декодирования можно использовать: либо специальные биты в поле кода операции команды, либо преддекодирование (как в процессорах iх86) команд при их загрузке в кэш-команд.
2. Для команды ветвления, которая находится в кэш-команд, условие перехода обычно еще не определено (не вычислено). В этих условиях и нужно предсказать, по какому пути пойдет ветвление (по «да», или по «нет»).
Первый способ предсказания – на основе статической, априорной информации о переходе (например, вероятность перехода по да – 0.7, по нет – 0.3, предсказание делается по большей вероятности).
Второй способ – динамическое предсказание, делается на основе информации, которая собирается в процессе выполнения программы и накапливается таблицах в виде предъистории ветвления для каждой команды перехода в программе. Например, в виде счетчика, который декрементируется в случае ошибки предсказания, и увеличивается в случае правильного предсказания. Предсказание осуществляется по знаку числа в счетчике.
Адрес ветвления обычно формируется путем целочисленного сложения. Ускорение может быть достигнуто, если использовать буфер, в который заносятся ранее использованные адреса переходов: Ада, Анет. Извлечение адреса из буфера занимает меньше времени, чем сложение.
Декодирование команд, переименование ресурсов и диспетчирование. На этой стадии выделяются существенные зависимости по данным типа RAW, устраняются несущественные типа WAW, WAR, производится распределение (диспетчирование) команд по буферам функциональных устройств (конвейеров).
При декодирование для каждой команды создается одна или несколько упорядоченных троек, каждая из которых содержит: исполняемую операцию (код операции), указатели на операнды (адреса операндов), указатели (адреса) на место размещения результатов операции.
Для преодоления лишних зависимостей типа WAW, WAR используется процедура (прием, способ), которая называется переименованием регистра. В этом случае для идентификации регистров используются логические и физические адреса. При программировании используются логические имена. Когда команда пишет значение по некоторому логическому имени (например, в регистр с номером два - R2). Другие команды, использующие это значение, обращаются к нему по физическому адресу (R2). Если какая-то другая команда должна записать значение по тому же логическому адресу (DX), то она получает в свое распоряжение другой физический адрес.
Основные способы переименования регистров:
1. Физический файл регистров больше логического
2. Размеры файлов равны
В первом случае переименование результатов осуществляется так: для исключения зависимостей типа WAW, WAR каждому логическому имени сопоставляется имя из списка свободных физических адресов. Если список свободных регистров пуст, диспетчиризация команд приостанавливается до момента появления свободных регистров.
Второй способ. В случае, когда файлы регистров равны, между логическими и физическими адресами устанавливается однозначное соответствие и, кроме того, организуется переупорядочивающий буфер для исполняемых команд. Он выполняется как очередь FIFO, организованная в виде кольцевого буфера с двумя указателями: начало и конец. Новые команды помещаются в конец очереди. По завершении команды результат ее исполнения помещается в предписанный ей элемент очереди (элемент тройки). Когда команда достигнет начала очереди (головы) и к этому моменту она успеет исполниться, то ее результат помещается в регистровый файл, а сама команда удаляется из очереди. Команда, не исполненная (в виду отсутствия операндов) остается в очереди до момента получения операндов.
Значение переменной, соответствующее логическому имени регистра, может быть размещено либо в соответствующем физическом регистре, либо в переупорядочивающем буфере.
Следует отметить, что переименование регистров фактически реализует модель вычислений по готовности данных – управление вычислениями потоком данных.
Исполнение команд. Сформированные для каждой команды упорядоченные тройки (КО, указатели операндов и результата) заносятся в буферы. После этого наступает этап динамической проверки готовности значений операндов, необходимых для исполнения команды. Команда готова к исполнению, если готовы ее операнды и свободны ресурсы, на которых она может быть выполнена.
Для организации окна исполнения можно использовать различные методы: одной очереди, многих очередей, резервирующий станции.
Одна очередь. В этом случае переименования регистров не требуется, доступность значений просто отмечается битом резервирования для каждого регистра. Регистр резервируется в момент, когда команда назначается на исполнение. Освобождается регистр, когда команда выполнена. Если для команды ресурсы не были зарезервированы, то она приостанавливается.
Много очередей. В этом случае каждая очередь организуется для команд одного типа: например, очередь команд с плавающей запятой, очередь команд для работы с памятью и т. п.
Резервирующая станция. Резервирующая станция – это совокупность средств, предназначенная для размещения всех необходимых для выполнения команды элементов: КО, имени (указателя) первого операнда, самого операнда, имени второго операнда, самого операнда, признаков доступности второго операнда, имени регистра результата. Когда команда завершится, то имя ее результата сравнивается с именами операндов команд, ожидающих этого результата. Если таковые обнаруживаются, то результат записывается в соответствующую позицию и устанавливается признак доступности. Когда у команды становятся доступными все операнды, начинается ее исполнение.
Завершающей фазой исполнения команды является фаза изменения состояния процессора по результатам выполнения команды. Для отображения состояния процессора используются два набора значений: текущее состояние (изменяемое по результатам операции) и состояние, необходимое для восстановления (в случае промаха).
Состояние процессора модифицируется и сохраняется в буфере истории вычислений. Эта информация, в случае необходимости, используется для восстановления состояния процессора.
Второй способ – вводится два состояния в явном виде – физическое и логическое. Физическое состояние изменяется сразу после завершения команды, а логическое – когда ясен результат условно выполненных команд. Для реализации этого способа используется переупорядочивающий буфер: результат из него отправляется в файл логических регистров и в память.
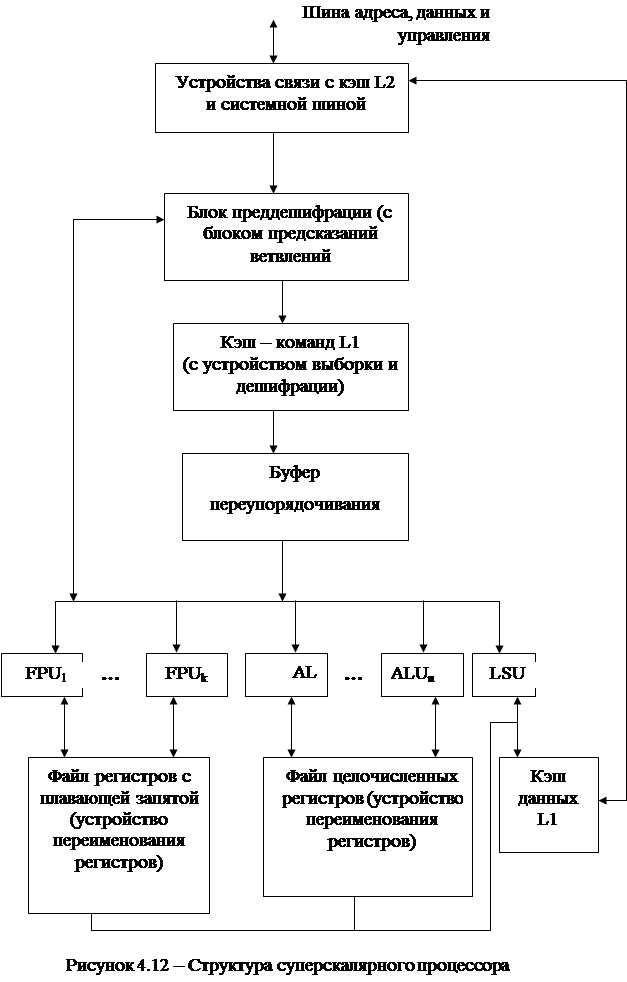
Структура суперскалярного процессора представлена на рисунке 4.12.
Назначение суперскалярного процессора – реализовать параллельное испольнение команд в рамках модели последовательных программ: после извлечения последовательного потока команд из памяти между командами устанавливается только действительно необходимые зависимости по данным (устраняются недействительные WAW, WAR). При этом сохраняется информация о порядке следования команд в исходной программе, с тем, чтобы сохранить этот порядок в случае прерывания.
Недостатки (ограничения) суперскалярных процессоров:
1. Сложность процессора (затраты оборудования) возрастает пропорционально количеству одновременно исполняемых команд (количеству конвейеров) и даже быстрее. Практическим пределом распараллеливания является, по прогнозам специалистов, не более 7-8 команд (конвейеров).
2. Ограниченная степень параллелизма на уровне команд – ввиду команд условных переходов и из-за того, что размер окна исполнения ограничен, что ограничивает возможный присущий программе в целом параллелизм, так как в окно попадает ограниченное число команд.
Альтернатива суперскалярной архитектуре – длинное командное слово (VLIW). Использование этого способа предполагает задание (явное указание) в командном слове совокупности выполняемых операций. Поскольку это указано в команде, аппаратура процессора не должна заниматься извлечением параллелизма из программы и, следовательно, организована проще. Подготовкой таких программ занимается компилятор (или программист).
Достоинства VLIW. 1. Компилятор в своем распоряжение имеет всю программу (окно размером во всю программу), поэтому он более эффективно извлекает параллелизм, чем аппаратура суперскалярного процессора через
ограниченное окно исполнения. 2.VLIW–процессор имеет более простое устройство управления, так как не надо извлекать параллелизм, и, следовательно, может работать на более высокой тактовой частоте.
Недостатки VLIW. Окно исполнения не может быть очень большим, так как у компилятора нет информации о зависимостях, формируемых в динамике (условия перехода становятся известными только в динамике, например, для итерационных циклов). Этот недостаток препятствует возможности переупорядочения операций.
Дальнейшее совершенствование процессоров суперскалярной архитектурой привело к идее создания процессоров с мультискалярной организацией (архитектурой). Эти работы находятся на стадии теоретических исследований и имитационного моделирования. Основная идея (суть) этого подхода – мультискалярная модель выполнения программы. Основное отличие от суперскалярной модели – для параллельной обработки предлагается использовать не параллельные конвейеры (структура которых зависит от специфики команд), а универсальные по функциям (одинаковые по структуре) процессоры, у каждого из которых есть собственный счетчик команд. В остальном все достаточно похоже.
В мультискалярных процессорах (МСКП) также все основано на извлечении параллелизма уровня команд из последовательной программы, но представленной на языке высокого уровня. С целью извлечения параллелизма такая программа разбивается на совокупность задач. Задача – часть программы, выполнению которой соответствует непрерывная область динамической последовательности команд (например, одиночная итерация цикла). Разбиение программы на задачи осуществляется с помощью программных средств и аппаратуры процессора. Задачи статически разграничиваются аннотациями. Зависимости по управлению между ними представляются в виде графа управляющих зависимостей (ГУЗ). В нем вершинами являются задачи, а дугами задается порядок их выполнения.
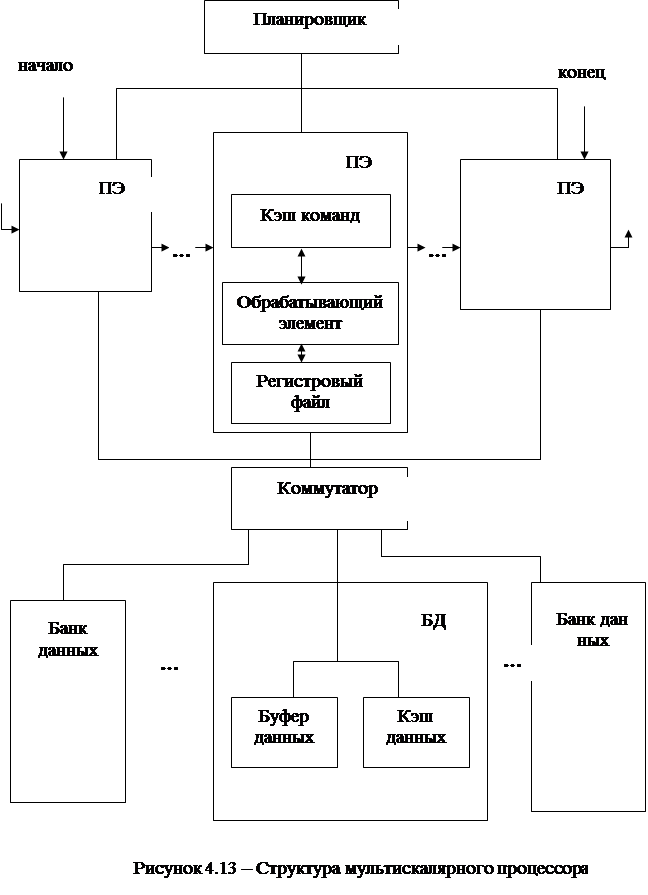
Структура МСК-процессора представлена на рисунке 4.13. Динамика выполнения программы (то есть задач) задается как обход ГУЗ программы (по дугам, по стрелка ГУЗ). На каждом шаге обхода ГУЗ МСК-процессор назначает одну задачу на один из свободных процессорных элементов (ПЭ) для выполнения и продолжает обход ГУЗ. Назначение обеспечивается передачей ПЭ начального значения программного счетчика (похоже на вызов программы). Значения регистров (данных) копируются в каждый ПЭ. Запущенные таким образом задачи выполняются параллельно на множестве ПЭ, что обеспечивает исполнение нескольких команд за 1 шаг.
МСК-процессор можно рассматривать как параллельный многопроцессорный ВК с программой–планировщиком, которая назначает задачи на ПЭ. Следует отметить, что задачи, выполняемые на ПЭ, не являются независимыми. В них остаются зависимости по данным и управлению. Эти зависимости обслуживаются так: 1) каждый ПЭ поддерживает последовательную модель выполнения задачи; 2) последовательный (определяемый алгоритмом) порядок выполнения для совокупности ПЭ поддерживается с помощью организации циклической очереди ПЭ. Указатели начала и конца очереди идентифицируют ПЭ, которые выполняют самую раннюю и самую позднюю из назначенных задач.
По мере выполнения команд в ПЭ производится и потребление значений переменных программы. Эти значения связаны с регистрами и памятью. При последовательном выполнении область хранения переменных рассматривается как единый набор регистров и ячеек памяти. Единство поддерживается коммутатором. Потери производительности МСК-процессоров возможны из-за наличия в ПЭ:
- тактов бесполезных вычислений (неверное предсказание);
- тактов ожидания операндов (от других ПЭ);
- свободных тактов (когда ПЭ стоит без задачи – свободен).
Достоинства МСК-процессоров – большая глубина предсказания переходов. При стандартном подходе в суперскалярных процессорах вероятность правильного предсказания перехода резко падает с увеличением глубины (уровня) перехода. Если вероятность предсказания одного перехода составляет обычно 0.9, то вероятность правильности предсказания на пять ветвлений вперед составляет величину порядка 0.6. Ясно, что при этом существенно падает производительность.
Мультискалярный подход сохраняет высокий уровень вероятности правильного предсказания перехода на существенно большую глубину, так как планировщик ветвлений должен предсказывать только ветви, которые определяют задачи.
МСК-процессор во многом похож на супер-ЭВМ типа МПВК с общей памятью. Главное их отличие – МПВК требует, чтобы компилятор делил программу на задачи с прямым указанием зависимостей между задачами. Эти зависимости компилятору сообщает программист в виде специальных операторов синхронизации и межпроцессорных коммуникаций, которые используется в языках параллельного программирования. МСК-процессор не требует никакой априорной информации относительно зависимостей по управлению и данным, что обеспечивает преемственность последовательного ПО и, следовательно, не требуется использовать (более сложные) языки параллельного программирования.
Итак, в МСК-процессорах объединяются принципы низко- и высокоуровневого распараллеливания, методы анализа статической и динамической структур программы. Их применение позволяет добиться более высоких значений эффективности использования аппаратных ресурсов процессора, чем в других типах архитектур. Фактически в них соединены в единое целое процессы автоматического распараллеливания (распараллеливающий компилятор) и аппаратные средства, реализующие сгенерированные компилятором программы. Компилятор сам генерирует указания аппаратуре о зависимостях в виде специальных команд и отметок команд.
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 554; Нарушение авторских прав?; Мы поможем в написании вашей работы!