КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Тема 4: дискрипторные информационно-поисковые языки: состав и стуктура
|
|
|
|
Метод координатного индексирования и поиска. Состав и структура дескрипторных информационно-поисковых языков. Анализ информации и построение словарей. Принципы отбора лексических единиц.
В основе построения дискрипторных информационно-поисковых языков лежит принцип координатного индексирования: основное смысловое содержание документа может быть выражено списком ключевых слов, т.е. наиболее существенных для понимания текста полнозначных[2] слов.
Принцип чистого координатного индексирования и поиска состоит в индексировании документов и запросов списками ключевых слов, являющихся ПОДами и ПОЗами, и в последующем сравнении полученных списков.
Метод координатного индексирования и поиска.
Пусть задано универсальное множество ключевых слов 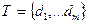 и некоторое множество документов
и некоторое множество документов 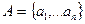 . Пусть далее
. Пусть далее 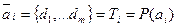 есть поисковый образ документа
есть поисковый образ документа 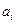 , т.е. существует такое отражение
, т.е. существует такое отражение 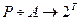 множества документов А в множество
множества документов А в множество 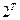 , что
, что 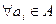 ,
, 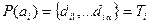 .
.
Пусть 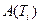 – подмножество документов с ПОДом, равным
– подмножество документов с ПОДом, равным 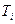 , т.е.
, т.е.
 ,
, 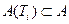 .
.
Обозначим подмножество документов, содержащих 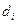 , через
, через 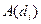 .
.
Если задано 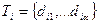 , то каждому
, то каждому 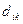 соответствует
соответствует 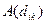 . Тогда
. Тогда 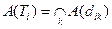 ,
, 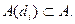
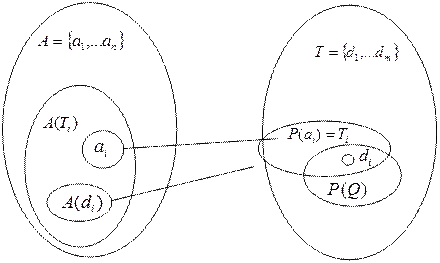
Рис. 4.1. Схема пересечения ПОД и ПОЗ
Рассмотрим запрос Q, поисковый образ которого есть 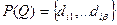 ,
, 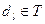 . Документ отвечает на запрос
. Документ отвечает на запрос 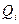 (релевантен Q), если
(релевантен Q), если
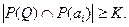
Подмножество релевантно запросу Q, если 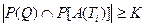 (рис. 4.1).
(рис. 4.1).
В соответствии с принципом чистой координации документ выдается на запрос Q в том случае, если их поисковые образы имеют не менее K общих ключевых слов.
Рассмотрим недостатки чистой координации на примерах [2]:
Пусть заданы следующие документы:
02. Хлористый натрий, бромистый калий, йодистый калий.
04. Ядерные реакторы.
05. Столкновение мезона с протоном.
06. Химические реакторы.
08. Передача электроэнергии из Англии в Шотландию.
Поисковые образы приведенных документов:
02. Хлориды, натрий, бромиды, калий, калий, йодиды.
04. Ядерные реакторы.
05. Столкновение, мезоны, протоны.
06. Химические, реакторы.
08. Передача, электроэнергия, Англии, Шотландия.
Перечислим некоторые нежелательные ситуации, возникающие при поиске в подобном массиве:
1) Ложная координация:
Запрос – йодистый натрий.
ПОЗ – йодиды, натрий.
В соответствии с принципом чистой координации, если К<2, то в массиве, выданном на данный запрос, будет документ 02. В действительности этот документ не отвечает запросу, т.к. в нем говорится об йодистом калии, а не о натрии.
2) Неполная координация:
Запрос – столкновение протона с протоном.
ПОЗ – столкновение, протоны.
Выдача – документ 05, не соответствующий запросу.
3) Синонимия ключевых слов
Запрос – поваренная соль.
ПОЗ – поваренная соль.
Выдача отсутствует, хотя нужно выдать документ 02, т.к. термин «поваренная соль» синоним термина «хлористый натрий».
4) Полисемия
Запрос – реакторы.
ПОЗ – реакторы.
Выдача – документы 04, 06, т.е. химические и ядерные реакторы.
5) Необозначенность родо-видовых (парадигмических) связей
Запрос – галоиды щелочных металлов.
ПОЗ – галоиды, щелочные металлы.
Выдачи нет, хотя нужно выдать документ 02, т.к:
а) галоиды – бромиды, йодиды, хлориды и т.д.;
б) щелочные металлы – калий, натрий и т.д.
6) Ложные синтагматические связи:
Запрос – передача электроэнергии из Шотландии в Англию.
ПОЗ – передача, электроэнергия, Шотландия, Англия.
Выдача – документ 08, хотя он и не отвечает запросу.
7) Невыдача документов, близких по смыслу запросу.
Запрос – хлористый и йодистый натрий, щелочные металлы.
ПОЗ – хлориды, йодиды, натрий, щелочные металлы.
Выдача отсутствует при К =5, хотя при К =3 будет выдан документ 02.
Для ликвидации указанных недостатков необходимы:
· устранение синонимии, полисемии, омонимии; это достигается введением в ИПЯ лексографического контроля;
· учет парагматических связей; учет возможен благодаря операций «И», «ИЛИ», «НЕ» и весовых коэффициентов, а также других методов и приемов уточнения и расширения запросов;
· учет синтагматических связей; учет возможен с помощью указателей роли и связи.
Основными элементами ДИПЯ являются (рис. 4.2):
1. Словарь лексических единиц, обеспечивающий выделение определенных частей текста и их замену на коды лексических единиц.
2. Правила применения ИПЯ (грамматика), определяющие процедуру перевода текстов документов и запросов (слов и словосочетаний – морфология; фраз, текстов в целом – синтаксис) с естественного языка на ИПЯ.
3. Правила построения и ведения ИПЯ, определяющие процедуру изменения и совершенствования ИПЯ, т.е. его словаря и правил применения.
Словари лексических единиц делятся на 2 группы:
– основные лексические словари, составляющие лексику ИПЯ. В качестве лексических единиц этих словарей используются ключевые слова, словосочетания и дескрипторы;
– морфологические словари, обеспечивающие морфологический анализ и нормализацию слов.
Ключевое слово – полнозначное слово естественного языка, выражающее смысловое содержание фрагмента документа или запроса самостоятельно или в наборе с другими ключевыми словами.
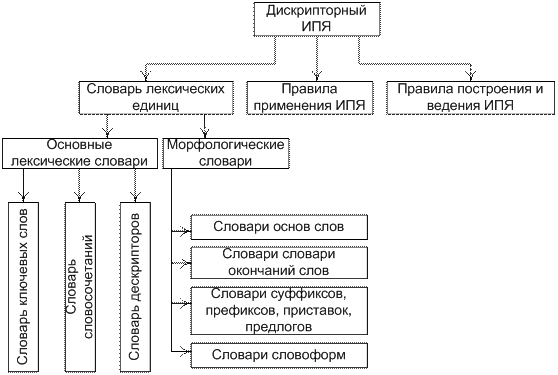
Рис. 4.2. Основные элементы дескрипторных ИПЯ
Словосочетание – последовательность нескольких слов (обычно 2–5) естественного языка, выражающая основное смысловое содержание фрагмента документа или запроса. Словосочетание может использоваться и в роли ключевого слова. Обычно словарь ключевых слов включает и отдельные слова и словосочетания, однако словосочетаний в этом словаре меньше, чем отдельных слов. И наоборот, словарь словосочетаний в основном состоит из словосочетаний.
Дескриптор – понятие, обозначающее группу эквивалентных или близких по смыслу ключевых слов, т.е. это имя класса синонимов. В качестве дескрипторов могут быть использованы код, слово или словосочетание.
Словарь дескрипторов с заданными парадигматическими[3] отношениями между его элементами носит название тезауруса. Тезаурус – это основной тип словарей современных ИПС.
Обобщенная структура информационно-поискового тезауруса включает, как минимум, три составляющих – словарную часть, семантическую карту, руководство по использованию.
Словарная часть – алфавитный список дескрипторов с их словарными статьями и ключевых слов. Словарная статья дескриптора строится по схеме:
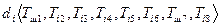 ,
,
где –дескриптор, 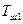 –множество ключевых слов-синонимов ;
–множество ключевых слов-синонимов ; 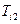 –множество родовых по отношению к дескрипторов, т.е. дескрипторов, связанных с отношением род–вид;
–множество родовых по отношению к дескрипторов, т.е. дескрипторов, связанных с отношением род–вид; 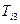 – множество видовых по отношению к дескрипторов;
– множество видовых по отношению к дескрипторов; 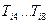 –множества дескрипторов, связанных с одним из отношений целое–часть, часть–целое, причина–следствие, следствие–причина, функциональное сходство. Все указанные множества упорядочены по алфавиту. В конкретных тезаурусах некоторые из множеств или все могут отсутствовать. Все множества могут быть одноэлементными или пустыми.
–множества дескрипторов, связанных с одним из отношений целое–часть, часть–целое, причина–следствие, следствие–причина, функциональное сходство. Все указанные множества упорядочены по алфавиту. В конкретных тезаурусах некоторые из множеств или все могут отсутствовать. Все множества могут быть одноэлементными или пустыми.
Семантическая карта – система тематических классов дескрипторов, представленная в виде графической схемы или таблицы.
Руководство по использованию ИПТ содержит правила перевода ключевых слов и словосочетаний на ИПЯ, правила лексикографического контроля и редактирования ПОД и ПОЗ, а также правила ведения ИПТ.
Основное назначение морфологических словарей состоит в отождествлении различных форм одного и того же слова и выявлении соответствующей грамматической информации, которую несет данное слово независимо от его окружения в тексте. Отождествление различных форм одного и того же слова проводятся для их нормализации, т.е. приведения к единому написанию и морфологической форме (нормальному виду). Именно в таком виде после соответствующего кодирования используются при индексировании и поиске документов. Нормализация слов необходима для их индексирования. Грамматическая информация к слову необходима для его восстановления (декодирования) по его коду, представленному в терминах ИПЯ.
Наиболее широкое распространение получили словари основ слов; окончаний слов; суффиксов, префиксов, приставок и предлогов; словоформ (словоформа – это последовательность букв между двумя соседними пробелами).
Процедура нормализации слов и выявления соответствующей им грамматической информации может выполняться как с использованием морфологического анализа и синтеза, так и без них. В любом случае прибегают к морфологическим словарям. Использование методов морфологического анализа позволяет сократить количество словарей, но за счет усложнения процедуры нормализации и выявления грамматической информации. Чем менее сложен алгоритм морфологического анализа, тем более сложны используемые им морфологические словари. Следует отметить, что нормализацию слов можно выполнить с помощью морфологических словарей минимальной сложности или вообще без них. Однако платой за такую простоту является невозможность получения грамматической информации или ее бедность.
Анализ информации и построение словарей. Принципы отбора лексических единиц.
Задача построения словарей сводится к следующему [2]: по заданному классу текстов необходимо выбрать попарно-различные лексические единицы (словоформы, основы слов, КС, дескрипторы и т.д.), определить их морфологические синтаксические и семантические характеристики и расположить в заранее обусловленном порядке.
При построении словарей приходится решать три основные проблемы: какие слова включать в словарь; какие учесть типы отношений; какова должна быть детальность словаря?
Решение первой проблемы в основном базируется на учете синонимии[4], омонимии[5], полисемии[6], а также информативности слов, косвенным показателем которой является частота их встречаемости в текстах. Лингвистические исследования показывают, что распределение слов по их частоте вхождения в текст для достаточно больших текстов заданного тематического профиля подчиняется закону, близкому к гиперболическому. Высокочастотной части этого распределения соответствуют «общие» слова, не несущие существенной смысловой нагрузки в текстах данной совокупности. Низкочастотной части распределения соответствуют новые специфические термины, не нашедшие распространения в текстах совокупности.
С учетом сказанного принципы отбора слов при решении первой из названных проблем [2]:
– не включать в словари редкие термины;
– исключать общие понятия с высокой частотой встречаемости;
– в каждый класс понятий вводить слова только с одинаковой частотой встречаемости;
– использовать только устойчивые слова и словосочетания;
– исключать незначащие (в пределах данных текстов) слова, тщательно проанализировав;
– неоднозначные термины применять в том значении, которое они имеют в данном массиве.
Типы пардигматических и синтагматических отношений, используемых в ИПЯ, определяют его смысловыразительную способность, которая возрастает с увеличением количества и усложнением типов учитываемых отношений.
Основные принципы, которым необходимо руководствоваться при выборе таких отношений:
– затраты на разработку, ведение и использование словарей не должны превышать эффекта от их применения;
– выбор типов отношений зависит от предполагаемых целей и областей использования ИПЯ и определяется необходимой полнотой и точностью поиска информации;
– прежде чем переходить к учету синтагматических отношений, необходимо исчерпать возможности парадигматики. Это связано с тем, что парадигматика позволяет найти область решений, а синтагматика – конкретное решение.
Степень детализации словаря определяет полноту и точность поиска. Широкоупотребляемые термины дают большую полноту, но низкую точность поиска.
При выборе степени детализации словарей необходимо учитывать заданные ограничения на желаемую полноту и точность поиска, а также иметь иерархию словарей и использовать их различные уровни при поиске информации по разным запросам.
Одной из актуальных задач информационно-поисковых систем является поиск аналогов. Сложность этой проблемы заключается в том, что по поисковому образу запроса, выраженному в терминах одной области знаний или отрасли техники, необходимо найти документ-аналог, поисковый образ которого выражен в терминах другой области знаний. Возникает межъязыковый барьер совместимости профессиональных языков. Один из путей преодоления такого барьера состоит в фасетном[7] принципе организации словарей, т.е. в построении одноименных фасет в словарях всех областей знаний и метафасет или трансляторов для перевода терминов одной области знаний в термины другой области знаний в пределах заданного фасета. Другой путь решения той же проблемы состоит в построении иерархического комплекса словарей, охватывающего все области знаний.
Количественные характеристики словарей. Эффективность информационного поиска в значительной мере определяется уровнем качества словарей информационно-поискового языка. Качество словарей можно охарактеризовать различными показателями. Наиболее часто используются следующие:
1) Количество типов словарей.
2) Число лексических единиц словарей.
3) Полнота словаря.
Рассмотрим ИПЯ некоторой автоматизированной ИПС, обслуживающей определенную предметную область. 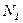 – общее число понятий данной предметной области, которые могут быть построены из лексических единиц ИПЯ (
– общее число понятий данной предметной области, которые могут быть построены из лексических единиц ИПЯ (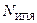 ) по правилам их образования в данном ИПЯ. Тогда коэффициент полноты словаря можно определить отношением к :
) по правилам их образования в данном ИПЯ. Тогда коэффициент полноты словаря можно определить отношением к :
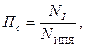
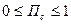 .
.
На практике используют:
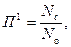
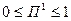 ,
,
где 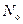 – количество лексических единиц словаря, по которым должен проводится поиск (определяется по общему количеству несовпадающих лексических единиц массива запросов),
– количество лексических единиц словаря, по которым должен проводится поиск (определяется по общему количеству несовпадающих лексических единиц массива запросов), 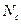 – количество лексических единиц в словаре.
– количество лексических единиц в словаре.
4) Коэффициент отображения лексики поискового массива.
Данный коэффициент определяется следующим образом:
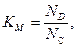
где 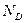 – количество дескрипторов в словаре.
– количество дескрипторов в словаре.
5) Коэффициент динамики роста словаря.
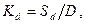
где 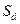 – количество лексических единиц, введенных в словарь в процессе обработки D документов.
– количество лексических единиц, введенных в словарь в процессе обработки D документов.
6) Распределение лексических единиц по длине словосочетаний
Средняя длина словосочетаний, используемых в ИПЯ в качестве лексических единиц, характеризует степень прекоординации[8] ИПЯ, тем самым являясь важной характеристикой смысловыразительной способности ИПЯ. Для характеристики ИПЯ с этой точки зрения используют распределение длин словосочетаний:
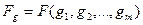 ,
, 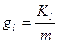 ,
,
где 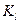 – количество лексических единиц, содержащих l слов; m – максимальная длина словосочетания в ИПЯ (в числе слов).
– количество лексических единиц, содержащих l слов; m – максимальная длина словосочетания в ИПЯ (в числе слов).
Средняя длина лексических единиц:
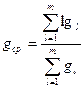 , где
, где 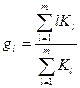 .
.
7) Распределение лексических единиц по количеству символов
Длину лексических единиц ИПЯ можно характеризовать распределением:
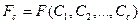 ,
,
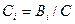 ,
,
где 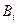 – количество лексических единиц, содержащих i символов, с – максимальное число символов в лексической единице. Среднее число символов в лексической единице:
– количество лексических единиц, содержащих i символов, с – максимальное число символов в лексической единице. Среднее число символов в лексической единице:
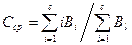
8) Ранговое распределение лексических единиц словаря.
Пусть 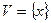 –словарь ИПС. Обозначим
–словарь ИПС. Обозначим 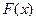 – частоту встречаемости слова x во всех текстах массива. Перенумеруем словарь так, чтобы частота слова была невозрастающей функцией его номера, т.е. если
– частоту встречаемости слова x во всех текстах массива. Перенумеруем словарь так, чтобы частота слова была невозрастающей функцией его номера, т.е. если 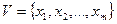 , то
, то 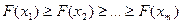 .
.
Назовем функцию 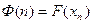 ранговым распределением слов
ранговым распределением слов 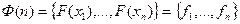 .
.
Показано, что частота слова n- го ранга связана с частотой слова 1-го ранга следующей зависимостью:
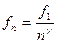 ,
,
где n –ранг слова.
Контрольные вопросы
1. Какова суть метода координатного индексирования и поиска?
2. Каковы недостатки чистой координации и пути их устранения?
3. Какие основные элементы включают дескрипторные поисковые языки? Охарактеризуйте каждый из этих элементов.
4. Какие используются для оценки уровня качества словарей информационно-поискового языка?
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 1750; Нарушение авторских прав?; Мы поможем в написании вашей работы!