КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Тема 5: системы индексирования
Типы систем индексирования. Морфологический анализ и нормализация понятий.
Индексирование – это процесс перевода текстов с естественного языка на ИПЯ. Индексирование базируется на совокупности инструкций, детально описывающих процесс индексирования и представляющих собой комплекс правил, включающих и правила применения ИПЯ [2].
Система индексирования (СИ) совокупность методов и средств перевода текстов с естественного языка на ИПЯ в соответствии с заданным набором словарей лексических единиц и с правилами применения ПНЯ. Помимо правил применения ИПЯ система индексирования может включать большое разнообразие инструкций, положений, методов и т.д., регламентирующих те или иные этапы процесса индексирования.
Существующие системы индексирования сильно отличаются друг от друга, и описать их общий состав и структуру невозможно. Однако наличие общих признаков позволяет дать системное представление о классах систем индексирования.
Рассмотрим типологию систем индексирования по пяти наиболее важным основаниям (рис. 5.1).
1. Но степени автоматизации процесса индексирования выделяют
системы:
- ручного индексирования;
- автоматического индексирования;
- автоматизированного индексирования.
2. По степени контролируемости различают системы:
- без словаря;
- с жестким словарем;
- со свободным словарем.
3. По характеру алгоритма отбора слов текста выделяют системы:
- с последовательным просмотром текста (отбираются все полнозначные слова);
- эвристическими процедурами выбора слов текста (слова отбираются интуитивно или по заданной процедуре):
- со статистическими процедурами выбора слов (отбираются только информативные слова в соответствии с распределением частот их употребления).
4. По характеру лексикографического контроля различают системы:
- без лексикографического контроля;
- с полным контролем;
- с промежуточным контролем.
Лексикографический контроль предусматривает:
• устранение синонимии, полисемии и омонимии на основе нормативных словарей лексических единиц с парадигматическими отношениями между ними;
• нормализацию слов на основе морфологических нормативных словарей.
В системах с полным контролем реализуются обе функции лексографического контроля. В системах индексации с промежуточным контролем эти функции реализуются частично.
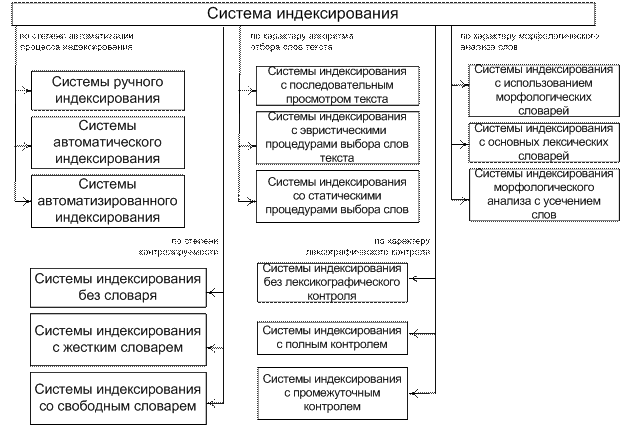
Рис. 5.1. Типы систем индексирования
5. По характеру морфологического анализа слов различают системы:
- с использованием морфологических словарей;
- с использованием основных лексических словарей;
- с использованием морфологического анализа с усечением слов.
Возможны системы индексирования без морфологического анализа.
Примеры систем индексирования:
1) Процесс свободного индексирования состоит в следующем. Индексатор выписывает слова или словосочетания, которые, по его мнению, отражают содержание текста. Он может брать слова, отсутствующие в тексте, но важные, с его точки зрения, для выражения смысла текста. Отобранный список слов является поисковым образом документа. Это системы индексирования с ручным индексированием, без словаря, с эвристическими процедурами отбора слов, без лексиграфического контроля и морфологического анализа.
2) Процесс полусвободного индексирования аналогичен вышеописанному, но слова сформированного списка соотносятся со словарем, несовпадающие слова отбрасываются в ПОД не включаются.
3) При жестком индексировании слова берутся только из текста. В ПОД включаются только те слова, которые есть в словаре. Перед включением термина в словарь производится его морфологическая нормализация на базе основных лексических словарей.
4) При статическом автокодировании слова выбираются из текста по заданным статистическим процедурам, после чего производится их статистическое кодирование путем усечения слов по алгоритмам позиционной статистики.
Существует ряд и других систем индексации.
Поначалу индексирование осуществлялось специально подготовленными специалистами-экспертами в предметной области, которые могли осуществлять глубокий анализ смыслового содержания документа и относить его (индексировать) к тем или иным классам, рубрикам, ключевым терминам. В этом случае были высоки накладные расходы, поскольку требовалось наличие в штате высококвалифицированных специалистов-индексаторов. Кроме того, процесс индексирования в некоторой мере был субъективным. Поэтому возникла задача автоматизации индексирования документов.
Существуют два подхода к автоматическому индексированию. Первый основан на использовании словаря ключевых слов и применяется в системах на основе ИПТ. Индексирование в таких системах осуществляется путем последовательного автоматического поиска в тексте документа ключевых терминов. Строится индекс, представляющий поисковое пространство документов. Возможны два типа такого индекса - прямой и инвертированный.
Прямой тип индекса строится по схеме «документ-термины». Поисковое пространство в ЭТОМ случае представлено в виде матрицы размерностью nxm. Строки этой матрицы представляют поисковые образы документов.
Инвертированный тип индекса строится по обратной схеме — «термин-документы». Поисковое пространство соответственно представлено аналогичной матрицей, только в транспонированной форме. Поисковыми образами документов в этом случае являются столбцы матрицы.
Второй подход к автоматическому индексированию применяется в полнотекстовых системах. В процессе индексирования в индекс заносится информация обо всех словах текста документа (отсюда и название «полнотекстовые»).
Морфологический анализ и нормализация понятий. Основные этапы процесса индексирования состоят в выборе понятий текста, отражающих его основное смысловое содержание, а также в морфологическом анализе и лексографическом контроле отобранных понятий и их кодировании [2].
Процедура отбора информативных понятий текста аналогична процессам выбора понятий при построении словарей основных лексических единиц, рассмотренным в предшествующей теме.
Рассмотрим более подробно суть процедур морфологического анализа, лексикографического контроля и кодирования понятий при использовании различных видов словарей.
Процедура морфологического анализа по морфологическим словарям состоит:
1) в определении обобщенного грамматического класса слова и его членами на основу и окончание (по словарям основ и окончаний);
2) в идентификации рода существительных (по основам слов);
3) в выявлении номера флексивного класса слов (по обобщенному грамматическому классу, признаку рода, окончанию, конечным буквосочетаниям основы);
4) в определении номера набора грамматической информации к слову.
Результатом такого анализа является нормализованное слово и номер набора его грамматической информации.
Нормализованные слова кодируются путем их замены буквенными кодами или кодами слов. В первом случае каждая буква заменяется соответствующим ей кодом (по словарю кодов букв). Во втором случае слова отождествляются по словарю лексических единиц и заменяются их номерами или кодами словаря.
Декодирование слов, производимое при выдаче результатов поиска, состоит в формировании буквенного кода слова (а затем и самого слова) по номеру или коду его нормализованной части и по номеру соответствующей грамматической информации.
При использовании словосочетаний процедура морфологического анализа существенно усложняется, включая в себя [2]:
1. Отождествление слов словосочетания с элементами словаря слов. Замена их номерами по словарю, сопровождение грамматической информацией.
2. Выявление грамматической структуры словосочетания в целом – синтаксический анализ (по грамматической информации слов словосочетания).
3. Поиск по словарю номера словосочетания, соответствующего данному сочетанию номеров слов и грамматической структуре кодируемого словосочетания.
4. Выбор из словаря по номеру словосочетания соответствующего ему номера грамматической структуры и самой структуры. Сравнение выбранной грамматической структуры с грамматической структурой кодируемого словосочетания, полученной на втором этапе. Если структуры совпадают, то понятия тождественны. Анализируемое словосочетание заменяется соответствующим ему номером или кодом. Два последних этапа являются этапами семантического анализа.
Декодирование словосочетаний представляет собой [2]:
1) выбор из словаря по номеру словосочетания соответствующего ему набора номеров слов и номера грамматической структуры;
2) извлечение информации о формах слов и их связях, восстановление порядка слов в словосочетании (по грамматической структуре);
3) формирование буквенного кода словосочетания и самого сочетания.
Морфологический анализ по словарям основных лексических единиц включает 2 этапа: сравнение слова со словарем (идентификация и определение номера совпадающего понятия) и выявление номера набора понятий осуществляется буквенным кодом или кодами понятий (по словарю).
В ИПС широко применяется морфологический анализ путем усечения слов. При этом используются различные процедуры усечения [2]:
а) с использованием словарей (основ, окончаний и т.д.);
б) без использования словарей (по простейшим априорным правилам);
в) статистическое усечение слов с использованием аппарата позиционной статистики.
В случае а) процедуры морфологического анализа, кодирования и декодирования те же, что и при использовании морфологических словарей. В случае б) начало и/или окончание слов усекается по определенным правилам. Усеченные части слов кодируются буквенными кодами. Декодирование отсутствует. В случае в) при усечении слов используется аппарат и словари позиционной статистики. Слова кодируются буквенными кодами, а декодирование тоже отсутствует.
При усечении слов производятся только их нормализация и неморфологический анализ.
Контрольные вопросы
1. Каковы роль и место системы индексирования в составе логико-семантических средств, обеспечивающих создание и функционирование автоматизированной информационно-поисковой системы?
2. Приведите примеры систем индексирования.
3. По каким типологическим признакам можно разделять системы индексирования?
4. В чем суть процедуры морфологического анализа, лексикографического контроля и кодирования понятий при использовании различных видов словарей в процессе индексирования?
Дата добавления: 2014-01-13; Просмотров: 4100; Нарушение авторских прав?; Мы поможем в написании вашей работы!