КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Формирование речевого сигнала и вокодерное преобразование
На рис. 16 показан принцип распределения энергии в частотных диапазонах. Эта картина может изменяться в широких рамках в зависимости от тембра голоса и особенностей произношения. На рисунке видно, что буквы отличаются не только частотным диапазоном, но и структурой. Для каждого звука характерны пики (резонансы) энергии в определенных частотных диапазонах и провалы в других. Частоты, на которых возникают пики, называются «частотами формант» или просто «формантами». Гласные и звонкие согласные звуки речи содержат обычно от трех до четырех формант. Эти свойства и иллюстрируются рис. 1.67. Изображенная «спектрограмма» представляет собой распределение энергии речи в виде функции времени и частоты.
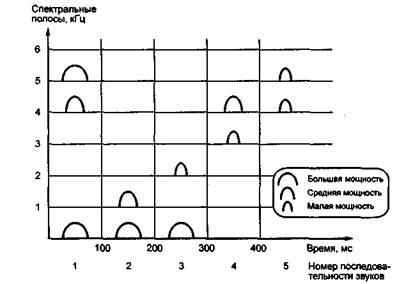
Рис. 16. Пример распределения энергии в частотных спектрах: 1 — гласная; 2 — гласная; 3 — гласная; 4 — звонкая согласная; 5 — глухая согласная
Число фонем в русском языке составляет 32, это 6 гласных звуков и остальные согласные. Чтобы закодировать их номера, достаточно 6 битов. Человек в среднем произносит в секунду 10 звуков. От центральной нервной системы к речевому аппарату сигналы передаются со скоростью 60 бит/с.
Эти простые оценки порождают иллюзию, что речь содержит небольшой объем информации и может быть передана с небольшой скоростью. Однако более детальное рассмотрение процесса образования звука позволяет заключить, что для передачи речи необходимы большие объемы информации.
При разговоре грудная клетка сжимается и расширяется, поток воздуха проходит через трахею и гортань в полости глотки, рта и носа. Голосовой тракт простирается от голосовой щели (отверстие между голосовыми складками гортани) до губ, и в процессе речи его форма меняется. Если произносятся звонкие звуки (гласные, носовые, звонкие согласные), называемые также вокализированными (voiced), голосовые складки в гортани смыкаются и размыкаются с той частотой, которая называется частотой основного тона (pitch). Получается последовательность импульсов воздушного потока, которые возбуждают полости голосового тракта. Говоря, человек меняет геометрические размеры этих полостей, соответственно меняются и резонаторные частоты — «форманты».
При произнесении глухих (невокализированных, unvoiced) звуков голосовые складки расслаблены. Проходя по суженному голосовому тракту, воздух создает турбулентный поток, т.е. в полости рта и носа возбуждаются шумоподобные сигналы.
Взрывные (смычные, stop) звуки получаются путем кратковременного выхлопа — полного перекрытия речевого тракта, нагнетания давления и внезапного открытия тракта. Взрывные звуки бывают звонкие (б, д, г) и глухие (п, т, к), т.е. могут образовываться с участием голосовых складок и без них. Таким образом, в терминах спектра сигналов, когда человек говорит, он производит спектрально-временную модуляцию широкополосного сигнала, генерируемого голосовыми складками и представляющего своего рода несущую. Полезная информация содержится в интонации (изменении частоты основного тона) и в смене спектра с тонального на шумовой и наоборот.
Линейная модель речеобразования представляет речь как систему, состоящую из генератора возбуждения (генераторная функция) и линейной системы с медленно изменяющимися параметрами (фильтровая функция), которая им возбуждается. В такой модели не учитывается взаимное влияние голосовой щели и голосового тракта, что сильно упрощает анализ. Для экономичной передачи и хранения речи необходимо определить параметры генераторной и фильтровой функции. В генераторной функции изменяется частота и амплитуда основного тона (высота и громкость голоса) и происходит смена вида функции (основной тон или шум), а у фильтровой функции происходит постоянное изменение коэффициента передачи, проявляющееся в изменении огибающей спектра.
Такая модель представляет собой речь человека, который «гудит» на одной частоте, периодически изменяя ее на другую и меняя громкость, а основная информация «добавляется» в «подтонах».
Для передачи этих параметров достаточно скорости передачи около 1200 бит/с.
Рассмотренные ранее принципы и реализующая их аппаратура предназначены в первую очередь для максимально точного воспроизведения формы входного сигнала на выходе приемной стороны. Ниже рассмотрены принципы построения устройств, которые моделируют человеческую речь, используя при этом методы цифрового кодирования. Они называются вокодерами (это слово получено от словосочетания voice coder — кодер речевого сигнала) [42, 66].
По принципу определения параметров фильтровой функции различают следующие типы вокодеров:
канальные (полосные, channel);
формантные;
ортогональные;
вокодеры с линейным предсказанием (липредеры — с Линейным Предсказанием Речи);
гомоморфные.
|
Дата добавления: 2014-01-13; Просмотров: 775; Нарушение авторских прав?; Мы поможем в написании вашей работы!