КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Списки и их разновидности
|
|
|
|
End.
End.
Рассмотрим пример описания записей:
type Date = record day:1…31;
month:1…12;
year:1…2000
Множество. Третья фундаментальная структура данных - множество (set). Значениями переменной x типа Т множества является совокупность элементов базового типа, Т0.
Его тип определяется таким образом: type T = set of T0.
Рассмотрим способы распределения (размещения) данных в оперативной памяти ЭВМ.
Оперативная память машины однородна и может быть представлена как линейка, состоящая из большого числа ячеек, в каждой из которых размещается одно данное. Доступ к некоторой ячейке для записи либо считывания данного осуществляется благодаря тому, что каждая ячейка имеет свой адрес (номер), явный или неявный; адресация ячеек, по умолчанию, сквозная. Для того, чтобы обеспечить эффективное использование памяти при наличии большого разнообразия математических моделей данных, надо так организовать данные (распределить их в памяти), чтобы был удобным доступ к нужной ячейке и чтобы основные операции над содержимым ячеек памяти: добавление (включение) или удаление (исключение) данного - не нарушали (не затрудняли) порядок следования данных.
Существуют два способа распределения данных в памяти ЭВМ: последовательное и связанное. В первом случае данные расположены в ячейках подряд (номера ячеек идут подряд), т. е. порядок следования элементов задаётся неявно требованием, чтобы смежные элементы последовательности находились в смежных ячейках памяти. Кроме того, имеет место фиксированное соотношение между номером i ячейки и элементом последовательности Si. Во втором случае данные связаны между собой специальными указателями, на которые отводится дополнительное место в ячейке; при этом каждому элементу S i последовательности данных поставлен в соответствие указатель Pi, отмечающий ячейку, в которой записаны элемент Si+1 и указатель на следующий за ним элемент.
Неудобство включения и исключения элементов при последовательном распределении происходит из-за того, что многие элементы последовательности во время включения или исключения должны передвигаться.
С помощью связанных распределений удалось добиться большей гибкости, потеряв некоторую информацию. Последовательное распределение позволяет иметь быстрый и прямой доступ к любому элементу последовательности. В связанном распределении доступ ко всем элементам последовательности, кроме первого, не является прямым и эффективным. Например, при последовательном представлении, если длина последовательности задана, то легко можно найти её срединный элемент. Это же самое труднее сделать, если последовательность задаётся связанным распределением; кроме того, приходится тратить память на указатели Pi.
Последовательное распределение наиболее естественно для статических структур данных, а связанное – для динамических.
При выборе последовательного или связанного представления разумно сначала проанализировать типы операций, которые будут выполняться над последовательностью. Если операции проводятся преимуще-ственно над случайными элементами, осуществляют поиск специфических элементов или проводят упорядочивание элементов, то обычно лучше последовательное распределение. Связанное распределение предпочтительнее, если в основном используются операции включения и/или исключения, а также сцепления и/или разбиения последовательности.
В языках программирования высокого уровня обязательно используются структуры данных, существенно более сложные, чем массивы. Ознакомимся с такими структурами данных, как списки, с помощью которых можно представлять множества, графы и деревья.
С математической точки зрения список - конечная последовательность элементов, взятых из некоторого подходящего множества. Описание алгоритма часто включает в себя некоторый список, к которому добавляются и из которого удаляются элементы, причём эти элементы в основном находятся где-то в середине списка (в частности, элемент может находиться и на краю списка).
Рассмотрим список
EL1, EL2, EL3, EL4. (3.1)
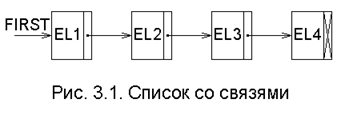 Простейшей его реализацией будет структура последовательно связанных компонент, изображенная на рис. 3.1. Каждая компонента в этой структуре состоит из двух ячеек памяти. Первая ячейка содержит сам эле-мент, вторая - указатель следующего элемента, причём последняя компонента не имеет указателя (точ-нее: его значение равно 0), а указатель на первую компонен-ту (FIRST) является внешним.
Простейшей его реализацией будет структура последовательно связанных компонент, изображенная на рис. 3.1. Каждая компонента в этой структуре состоит из двух ячеек памяти. Первая ячейка содержит сам эле-мент, вторая - указатель следующего элемента, причём последняя компонента не имеет указателя (точ-нее: его значение равно 0), а указатель на первую компонен-ту (FIRST) является внешним.
Такую структуру можно реализовать в виде двух массивов, которые на рис. 3.2 названы NAME и NEXT. Если COMP - компонента в рассматриваемом массиве, то NAME[COMP] - сам элемент, хранящийся там, а NEXT[COMP] - индекс следующего элемента в списке (если такой элемент существует). Если COMP - индекс последнего элемента в этом списке, то NEXT[COMP]=0.
На рис. 3.2 NEXT[0] означает постоянный указатель на первую компоненту в списке. Заметим, что порядок элементов в массиве NAME не совпадает с их порядком в списке. Однако рис. 3.2 даёт верное представ-
| Index | NAME | NEXT |
| __ | ||
| EL1 | ||
| EL4 | ||
| POS®3 | EL2 | |
| EL3 | ||
| FREE®5 | __ | __ |
| Рис. 3.2. Представление списка (3.1) из четырех элементов |

ление списка, изображенного на рис. 3.1, так как массив NEXT располагает
Процедура INS c формальными параметрами X, FREE, POS имеет вид
procedure INS (X, FREE, POS);
|
|
|
|
Дата добавления: 2014-01-14; Просмотров: 429; Нарушение авторских прав?; Мы поможем в написании вашей работы!