КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Б. Процедура декодирования
|
|
|
|
А. Процедура кодирования
Процедуры кодирования и декодирование группового кода
1.Процедура кодирования на основе порождающей матрицы
Пусть требуется получить кодовую комбинацию (n,k)-кода Vi, соответствующую некоторому сообщению источника информации, представленному в виде безызбыточной k -элементной последовательности ki . Как было показано выше, эта задача решается составлением линейной комбинации строк порождающей матрицы:
Vi=ki1V1+ki2V2+…+ kikVk, где Vj, j=1 … k,-кодовые комбинации (n,k)-кода, являющиеся строками канонической формы порождающей матрицы этого кода, ki,j - элементы кодируемой k - элементной последовательности.
Указанная линейная комбинация соответствует умножению последовательности ki на порождающую матрицу кода, представленную в канонической форме:
ki ×G(n,k)=ki × [RIk]=(kiR,ki)
В результате умножения получим n- элементную кодовую комбинацию Vi, у которой на местах избыточных элементов (v1,v2,…vn-k) находятся последовательность ri=kiR, а на местах информационных элементов- (vn-k+1,…,vn)- исходная кодируемая последовательность ki.
2. Процедура кодирования на основе проверочной матрицы.
В этом случае процедура кодирования основана на известном уравнении.
Vi×HT(n,r)=0.
Представим Vi в виде (ri,ki), где ri - последовательность избыточных элементов кодовой комбинации, а ki - последовательность информационных элементов. Представляя HT(n,k) в канонической форме, получаем: (ri,ki)×[In-kRT ]T=ri+kiR=0, откуда ri=kiR..
Из полученного решения видно, что избыточные элементы в точности совпадают с избыточными элементами при кодировании на основе G(n,k)
В тех случаях, когда (n-k)<k или k ∕ n > 1∕2, кодирование на основе проверочной матрицы H(n,k) требует меньшего количества вычислений.
Пусть 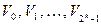 - кодовые комбинации некоторого группового кода, где
- кодовые комбинации некоторого группового кода, где 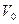 - нулевая комбинация, то есть единичный элемент группы. Процедура декодирования для этого кода может быть выработана на основе следующих построений. Строится таблица декодирования как таблица разложения группы всевозможных n – элементных двоичных комбинаций на смежные классы по подгруппе, составляющей данный код. Образующие смежных классов выбираются таким образом, чтобы в их состав вошли все наиболее вероятные для используемого канала связи образцы ошибок в кодовой комбинации. Для большей части реальных каналов связи в качестве образующих смежных классов следует выбирать комбинации с минимальным весом в данном смежном классе.
- нулевая комбинация, то есть единичный элемент группы. Процедура декодирования для этого кода может быть выработана на основе следующих построений. Строится таблица декодирования как таблица разложения группы всевозможных n – элементных двоичных комбинаций на смежные классы по подгруппе, составляющей данный код. Образующие смежных классов выбираются таким образом, чтобы в их состав вошли все наиболее вероятные для используемого канала связи образцы ошибок в кодовой комбинации. Для большей части реальных каналов связи в качестве образующих смежных классов следует выбирать комбинации с минимальным весом в данном смежном классе.
Выпишем в качестве первой строки таблицы все кодовые комбинации, начиная с нулевой. В качестве образующих смежных классов возьмем 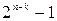 наиболее вероятных образцов ошибок для используемого канала (ei).
наиболее вероятных образцов ошибок для используемого канала (ei).
|
|
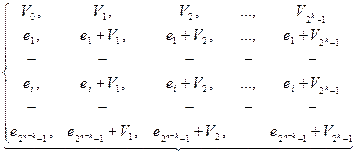
Каждый из столбцов таблицы декодирования является защитной зоной для кодовой комбинации, стоящей во главе столбца.
Решение о наличии ошибок в кодовой комбинации и их структуре производится по виду синдрома
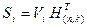 .
.
Покажем, что каждому образцу исправляемой ошибки соответствует вполне определенный синдром.
Если синдром чисто нулевой, то считается, что ошибки в кодовой комбинации отсутствуют, хотя это и не всегда верно, так как комбинациям с необнаруженными ошибками также соответствует нулевой синдром.
Предположим, что кодовая комбинация принята с исправляемой ошибкой, то есть
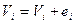 ,
,
где 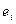 - образец ошибки, являющейся образующим смежного класса.
- образец ошибки, являющейся образующим смежного класса.
В этом случае синдром принимает вид:
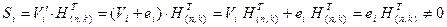 ,
,
то есть для каждого образца исправляемых ошибок или, что тоже самое,
для каждого смежного класса существует свой синдром.
Переданная комбинация  будет декодирована, верно по принятой комбинации
будет декодирована, верно по принятой комбинации 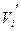 тогда и только тогда, когда вектор ошибки
тогда и только тогда, когда вектор ошибки 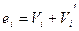 является образующим смежного класса, которому принадлежит .
является образующим смежного класса, которому принадлежит .
Процесс декодирования при использовании таблицы декодирования для исправления ошибок заключается в следующем:
1. Для принятой комбинации вычисляется синдром и определяется смежный класс, которому принадлежит принятая комбинация.
2. Определяется образующий смежного класса, которому принадлежит принятая комбинация, являющийся предполагаемой ошибкой.
3. Суммируя по модулю 2 предполагаемый образец ошибки с принятой комбинацией, получаем переданную комбинацию.
Таким образом, при исправлении ошибок в кодовой комбинации указанным методом количество исправляемых ошибок не может превышать числа смежных классов, то есть числа 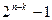 , и в точности равно этому числу в тех случаях, когда в каждом смежном классе имеется единственная комбинация, соответствующая наиболее вероятной структуре ошибок
, и в точности равно этому числу в тех случаях, когда в каждом смежном классе имеется единственная комбинация, соответствующая наиболее вероятной структуре ошибок
Коды, которые исправляют все ошибки кратности до t включительно и не исправляют никаких ошибок большей кратности, называются совершенными.
При обнаружении ошибок процедура декодирования упрощается. Если вычисленный синдром 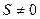 , то выдается сигнал “ошибка” или ”стирание”.
, то выдается сигнал “ошибка” или ”стирание”.
При этом сам вид синдрома не имеет значения, т.е. все смежные классы объединяются в общую защитную зону. При частичном исправлении и обнаружении ошибок задается кратность ошибок 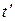 , до которой осуществляется исправление, а ошибки высших кратностей только обнаруживаются, поэтому в таблице декодирования выделяется
, до которой осуществляется исправление, а ошибки высших кратностей только обнаруживаются, поэтому в таблице декодирования выделяется 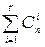 образцов ошибок, подлежащих исправлению. Все же остальные
образцов ошибок, подлежащих исправлению. Все же остальные 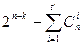 смежных классов объединяются в общую защитную зону. Если синдром, соответствующий принятой комбинации принадлежит общей защитной зоне, то фиксируется обнаружение ошибки – “стирание”.
смежных классов объединяются в общую защитную зону. Если синдром, соответствующий принятой комбинации принадлежит общей защитной зоне, то фиксируется обнаружение ошибки – “стирание”.
Если синдром принадлежит смежному классу с исправляемым образом ошибки, то происходит исправление ошибки, как это было описано выше.
Пример 5.10. Рассмотрим таблицу декодирования для (5, 3) – кода, используемого в предыдущих примерах.
| (5, 3) код (подгруппа) 10100 11010 01001 01110 11101 10011 00111 | |
| 10101 11011 01000 01111 11100 10010 00110 | |
| 10110 11000 01011 01100 11111 10001 00101 | |
| 10000 11110 01101 01010 11001 10111 00011 |

Из анализа таблицы декодирования можно сделать следующие выводы:
1. Синдромы имеют значения
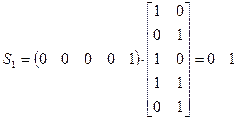 ,
,
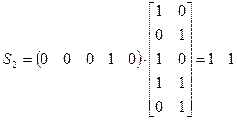 ,
,
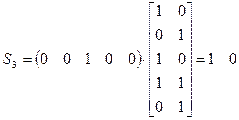 ,
,
т.е. все синдромы разные и вид синдрома однозначно указывает смежный класс.
2. Код исправляет не все образцы одиночных ошибок. Например, комбинации 0 0 0 0 1 и 0 1 0 0 0, также как и 0 0 1 0 0 и 1 0 0 0 0 принадлежат одному смежному классу, следовательно, обе пары этих образцов ошибок не могут быть исправлены. Это понятно, так как dmin этого кода равно 2, а для исправления всех вариантов одиночных ошибок необходимо иметь dmin =3.
Действительно, мы находим в смежном классе с образующим 0 0 0 0 1 еще одну комбинацию веса 1 – 0 1 0 0 0, т.е. синдрому S1 = 0 1 соответствует два равновероятных образца однократных ошибок; синдрому S2 = 1 0 также соответствуют два образца равновероятных однократных ошибок. Только лишь синдрому S3 = 1 1 соответствует единственный образец однократной ошибки 0 0 0 1 0.
Таким образом, однозначно исправляются только лишь комбинации, принадлежащие одному смежному классу, т.е. ошибка вида 0 0 0 1 0 данным кодом исправляется.
|
|
|
|
Дата добавления: 2014-01-14; Просмотров: 841; Нарушение авторских прав?; Мы поможем в написании вашей работы!