КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Паралелізм розподілених застосувань
|
|
|
|
Паралелізм взаємодії з користувачем
Паралелізм операцій введення-виведення
Види паралелізму
Можна виділити такі основні види паралелізму:
§ паралелізм багатопроцесорних систем;
§ паралелізм операцій введення-виведення;
§ паралелізм взаємодії з користувачем;
§ паралелізм розподілених систем.
Перший з них є справжнім паралелізмом, тому що у багатопроцесорних системах інструкції виконують декілька процесорів одночасно. Інші види паралелізму можуть виникати і в однопроцесорних системах тоді, коли для продовження виконання програмного коду необхідні певні зовнішні дії.
Під час виконання операції введення-виведення (наприклад, обміну даними із диском) низькорівневий код доступу до диска і код застосування не можуть виконуватись одночасно. У цьому разі застосуванню треба почекати завершення операції введення-виведення, звільнивши на цей час процесор. Природним вважається зайняти на цей час процесор інструкціями іншої задачі.
Багатопотокове застосування може реалізувати цей вид паралелізму через створення нових потоків, які виконуватимуться, коли поточний потік очікує операції введення-виведення. Так реалізується асинхронне введення-виведення, коли застосування продовжує своє виконання, не чекаючи на завершення операцій введення-виведення.
Під час інтерактивного сеансу роботи користувач може виконувати різні дії із застосуванням (і очікувати негайної реакції на них) до завершення обробки попередніх дій. Наприклад, після запуску команди «друкування документа» він може негайно продовжити введення тексту, не чекаючи завершення друкування.
Щоб розв'язати це завдання, можна виділити окремі потоки для безпосередньої взаємодії із користувачем (наприклад, один потік може очікувати введення з клавіатури, інший — від миші, додаткові потоки — відображати інтерфейс користувача). Основні задачі застосування (розрахунки, взаємодія з базою даних тощо) у цей час виконуватимуть інші потоки.
Розглянемо серверне застосування, яке очікує запити від клієнтів і виконує дії у відповідь на запит. Якщо клієнтів багато, запити можуть надходити часто, майже водночас. Якщо тривалість обробки запиту перевищує інтервал між запитами, сервер буде змушений поміщати запити в чергу, внаслідок чого знижується продуктивність. При цьому використання потоків дає можливість організувати паралельне обслуговування запитів, коли основний потік приймає запити, відразу передає їх для виконання іншим потокам і очікує нових.
5.
За допомогою потоків вирішуються такі проблеми:
§ потоки дають змогу реалізувати різні види паралелізму і дозволяють застосуванню масштабуватися із ростом кількості процесорів.
§ для підтримки потоків потрібно менше ресурсів, ніж для підтримки процесів (наприклад, немає необхідності виділяти для потоків адресний простір).
§ для обміну даними між потоками може бути використана спільна пам'ять (адресний простір їхнього процесу). Це ефективніше, ніж застосовувати засоби міжпроцесової взаємодії.
Незважаючи на перелічені переваги, використання потоків не є універсальним засобом розв'язання проблем паралелізму, і пов'язане з деякими труднощами:
§ розробляти і налагоджувати багатопотокові програми складніше, ніж звичайні послідовні програми; досить часто впровадження багатопотоковості призводить до зниження надійності застосувань. Організація спільного використання адресного простору декількома потоками вимагає, щоб програміст мав високу кваліфікацію.
§ використання потоків може спричинити зниження продуктивності застосувань. Переважно це трапляється в однопроцесорних системах (наприклад, у таких системах спроба виконати складний розрахунок паралельно декількома потоками призводить лише до зайвих витрат на перемикання між потоками, кількість виконаних корисних інструкцій залишиться тією ж самою).
Переваги і недоліки використання потоків потрібно враховувати під час виконання будь-якого програмного проекту. Насамперед доцільно розглядати можливість розв'язати задачу в рамках моделі процесів. При цьому, однак, варто брати до уваги не лише поточні вимоги замовника, але й необхідність розвитку застосування, його масштабування тощо. Можливо, з урахуванням цих факторів використання потоків буде виправдане.
Лекція №2.
Тема: Способи реалізації моделі процесів і потоків та їх опис.
План:
1.Способи реалізації моделі потоків (Л1. ст.50-51).
2.Стани процесів і потоків (Л1. ст.51-52).
3.Опис процесів і потоків (Л1. ст.52).
4.Керуючі блоки процесів і потоків (Л1. ст.53).
5.Образи процесів і потоків (Л1. ст53-54).
1.
В ОС використовують два типи потоків – потоки користувача і потоки ядра
Потік користувача — це послідовність виконання команд в адресному просторі процесу. Ядро ОС не має інформації про такі потоки, вся робота з ними виконується в режимі користувача. Засоби підтримки потоків користувача надають спеціальні системні бібліотеки; вони доступні для прикладних програмістів у вигляді бібліотечних функцій. Бібліотеки підтримки потоків у сучасних ОС реалізують набір функцій, визначений стандартом РОSІХ (відповідний розділ стандарту називають POSIX.1b); тут прийнято говорити про підтримку потоків РОSІХ.
Потік ядра - це послідовність виконання команд в адресному просторі ядра. Потоками ядра управляє ОС, перемикання ними можливе тільки у привілейованому режимі. Є потоки ядра, які відповідають потокам користувача, і потоки, що не мають такої відповідності.
| ♦ Процес |
Співвідношення між двома видами потоків визначає реалізацію моделі потоків. Є кілька варіантів такої реалізації (схем багатопотоковості); розглянемо найважливіші з них (рис. 3.1).
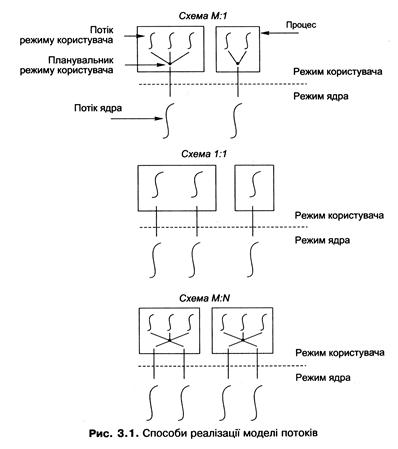
Схема багатопотоковості М:1 (є найранішою) реалізує багатопотоковість винятково в режимі користувача. При цьому кожен процес може містити багато потоків користувача, однак про наявність цих потоків ОС не відомо, вона працює тільки із процесами. За планування потоків і перемикання контексту відповідає бібліотека підтримки потоків. Схема вирізняється ефективністю керування потоками (для цього немає потреби переходити в режим ядра) і не потребує для реалізації зміни ядра ОС. Проте нині її практично не використовують через два суттєвих недоліки, що не відповідають ідеології багатопотоковості.
§ Схема М:1 не дає змоги скористатися багатопроцесорними архітектурами, оскільки визначити, який саме код виконуватиметься на кожному із процесорів, може тільки ядро ОС. У результаті всі потоки одного процесу завжди виконуватимуться на одному процесорі.
§ Оскільки системні виклики обробляються на рівні ядра ОС, блокувальний системний виклик (наприклад, виклик, який очікує введення даних користувачем) зупинятиме всі потоки процесу, а не лише той, що зробив цей виклик.
Схема багатопотоковості 1:1 ставить у відповідність кожному потоку користувача один потік ядра. Планування і перемикання контексту виконується на рівні потоків ядра. у режимі користувача ці функції не реалізовані. Оскільки ядро ОС має інформацію про потоки, ця схема вільна від недоліків попередньої (різні потоки можуть виконуватися на різних процесорах, а при зупиненні одного потоку інші продовжують роботу). Вона проста і надійна в реалізації і сьогодні є найпоширенішою. Хоча схема передбачає, що під час керування потоками треба постійно перемикатися між режимами процесора, на практиці втрата продуктивності внаслідок цього виявляється незначною.
Схема багатопотоковості М:N. У цій схемі присутні як потоки ядра, так і потоки користувача, які відображаються на потоки ядра так, що один потік ядра може відповідати декільком потокам користувача. Число потоків ядра може бути змінене програмістом для досягнення максимальної продуктивності. Розподіл потоків користувача по потоках ядра виконується в режимі користувача, планування потоків ядра - у режимі ядра. Схема є складною в реалізації і сьогодні здає свої позиції схемі 1:1.
2.
Для потоку дозволені такі стани:
§ створення (new) — потік перебуває у процесі створення;
§ виконання (running) — інструкції потоку виконує процесор (у конкретний момент часу на одному процесорі тільки один потік може бути в такому стані);
§ очікування (waiting) — потік очікує деякої події (наприклад, завершення операції введення-виведення); такий стан називають також заблокованим, а потік - припиненим;
§ готовність (ready) — потік очікує, що планувальник перемкне процесор на нього, при цьому він має всі необхідні йому ресурси, крім процесорного часу;
§ завершення (terminated) — потік завершив виконання (якщо при цьому його ресурси не були вилучені з системи, він переходить у додатковий стан — стан зомбі).
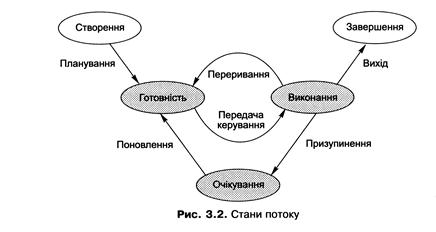
Перехід потоків між станами очікування і готовності реалізовано на основі планування задач, або планування потоків. Під час планування потоків визначають, який з потоків треба відновити після завершення операції введення-виведення, як організувати очікування подій у системі.
Для здійснення переходу потоків між станами готовності та виконання необхідне планування процесорного часу. На основі алгоритмів такого планування визначають, який з готових потоків потрібно виконувати в конкретний момент, коли потрібно перервати виконання потоку, щоб перемкнутися на інший готовий потік тощо.
Відносно систем, які реалізують модель процесів, прийнято говорити про стани процесів, а не потоків, і про планування процесів; фактично стани процесу в цьому разі однозначно відповідають станам його єдиного потоку.
У багатопотокових системах також можна виділяти стани процесів. Наприклад, у багатопотоковості, реалізованій за схемою М:1, потоки змінюють свої стани в режимі користувача, а процеси — у режимі ядра.
3.
Одним із основних завдань операційної системи є розподіл ресурсів між процесами і потоками. Такими ресурсами є насамперед процесорний час (його розподіляють між потоками під час планування), засоби введення-виведення й оперативна пам'ять (їх розподіляють між процесами).
Для керування розподілом ресурсів ОС повинна підтримувати структури даних, які містять інформацію, що описує процеси, потоки і ресурси. До таких структур даних належать:
§ таблиці розподілу ресурсів: таблиці пам'яті, таблиці введення-виведення, таблиці файлів тощо;
§ таблиці процесів і таблиці потоків, де міститься інформація про процеси і потоки, присутні у системі в конкретний момент.
4.
Інформацію про процеси і потоки в системі зберігають у спеціальних структурах даних, які називають керуючими блоками процесів і керуючими блоками потоків. Ці структури дуже важливі для роботи ОС, оскільки на підставі їхньої інформації система здійснює керування процесами і потоками.
Керуючий блок потоку (Thread Control Block, ТСВ) відповідає активному потоку, тобто тому, який перебуває у стані готовності, очікування або виконання. Цей блок може містити таку інформацію:
§ ідентифікаційні дані потоку (зазвичай його унікальний ідентифікатор);
§ стан процесора потоку: користувацькі регістри процесора, лічильник інструкцій, покажчик на стек;
§ інформацію для планування потоків.
Таблиця потоків — це зв'язний список або масив керуючих блоків потоку. Вона розташована в захищеній області пам'яті ОС.
Керуючий блок процесу (Process Control Block, РСВ) відповідає процесу, що присутній у системі. Такий блок може містити:
§ ідентифікаційні дані процесу (унікальний ідентифікатор, інформацію про інші процеси, пов'язані з даним);
§ інформацію про потоки, які виконуються в адресному просторі процесу (наприклад, покажчики на їхні керуючі блоки);
§ інформацію, на основі якої можна визначити права процесу на використання різних ресурсів (наприклад, ідентифікатор користувача, який створив процес);
§ інформацію з розподілу адресного простору процесу;
§ інформацію про ресурси введення-виведення та файли, які використовує процес.
Зазначимо, що для систем, у яких реалізована модель процесів, у керуючому блоці процесу зберігають не посилання на керуючі блоки його потоків, а інформацію, необхідну безпосередньо для його виконання (лічильник інструкцій, дані для планування тощо).
Таблицю процесів організовують аналогічно до таблиці потоків. Як елементи в ній зберігатимуться керуючі блоки процесів.
5.
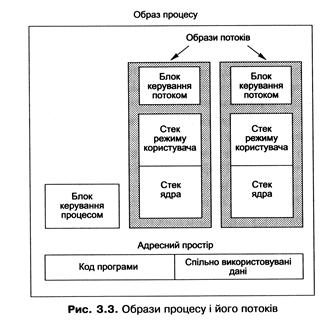
Сукупність інформації, що відображає процес у пам'яті, називають образом процесу (process image), а всю інформацію про потік - образом потоку (thread image). До образу процесу належать:
§ керуючий блок процесу;
§ програмний код користувача;
§ дані користувача (глобальні дані програми, загальні для всіх потоків);
§ інформація образів потоків процесу.
Програмний код користувача, дані користувача та інформація про потоки завантажуються в адресний простір процесу. Образ процесу звичайно не є безперервною ділянкою пам'яті, його частини можуть вивантажуватися на диск. Ці питання будуть розглянуті в розділі 9.
До образу потоку належать:
§ керуючий блок потоку;
§ стек ядра (стек потоку, який використовується під час виконання коду потоку в режимі ядра);
§ стек користувача (стек потоку, доступний у користувацькому режимі).
Схема розташування в пам'яті образів процесу і його потоків зображена нарис. 3.3. Усі потоки конкретного процесу можуть користуватися загальною інформацією його образу.
Лекція №3.
Тема: перемикання контексту й обробка переривань.
План:
1.Організація перемикання контексту (Л1. ст.54-55).
2.Обробка переривань (Л1. ст.55).
3.Створення процесів та їхня ієрархія (Л1. ст.56-57).
4.Особливості завершення процесів (Л1. ст.59).
5.Синхронне й асинхронне виконання процесів (Л1. ст.59).
6.Створення і завершення потоків (Л1. ст.60-61).
1.
Найважливішим завданням операційної системи під час керування процесами і потоками є організація перемикання контексту - передачі керування від одного потоку до іншого зі збереженням стану процесора.
Загальних принципів перемикання контексту дотримуються у більшості систем, але їхня реалізація обумовлена конкретною архітектурою. Для перемикання контексту потрібно виконати такі операції:
§ зберегти стан процесора потоку в деякій ділянці пам'яті (області зберігання стану процесора потоку);
§ визначити, який потік слід виконувати наступним;
§ завантажити стан процесора цього потоку із його області зберігання;
§ продовжити виконання коду нового потоку.
Перемикання контексту здійснюється із залученням засобів апаратної підтримки. Можуть бути використані спеціальні регістри та ділянки пам'яті, які дають можливість зберігати інформацію про поточну задачу (коли розглядають апаратне забезпечення, аналогом поняття «потік» є поняття «задача»), а також спеціальні інструкції процесора для роботи з цими регістрами та ділянками пам'яті.
В архітектурі ІА-32 для збереження стану процесора кожної задачі (вмісту пов'язаних із нею регістрів процесора) використовують спеціальну ділянку пам'яті - сегмент стану задачі ТSS. Адресу цієї області можна одержати з регістра задачі ТR (це системний адресний регістр).
Для перемикання задач досить завантажити нові дані в регістр ТR. У результаті значення регістрів процесора поточної задачі автоматично збережуться в її сегменті стану, після чого в регістри процесора буде завантажено стан процесора нової (або раніше перерваної) задачі й почнеться виконання її інструкцій.
Наступний потік для виконання вибирають відповідно до принципів планування потоків.
2.
У процесі виконання потік може бути перерваний не лише для перемикання контексту на інший потік, але й у зв'язку із програмним або апаратним перериванням (перемикання контексту теж пов'язане із перериваннями, власне, із перериванням від таймера). Із кожним перериванням надходить додаткова інформація (наприклад, його номер). На підставі цієї інформації система визначає, де буде розміщена адреса процедури оброблювача переривання (список таких адрес зберігають у спеціальній ділянці пам'яті і називають вектором переривань).
Наведемо приклад послідовності дій під час обробки переривання:
§ збереження стану процесора потоку;
§ встановлення стека оброблювача переривання;
§ початок виконання оброблювача переривання (коду операційної системи); для цього з вектора переривання завантажується нове значення лічильника команд;
§ відновлення стану процесора потоку після закінчення виконання оброблювача і продовження виконання потоку.
Передача керування оброблювачеві переривання, як і перемикання контексту, може відбутися практично у будь-який момент. Основна відмінність полягає в тому, що адресу, на яку передається керування, задають на основі номера переривання і зберігають у векторі переривань, а також у тому, що код оброблювача не продовжується з місця, де було перерване виконання, а починає виконуватися щораз заново.
3.
Засоби створення і завершення процесів дають змогу динамічно змінювати в операційній системі набір застосувань, що виконуються. Засоби створення і завершення потоків є основою для створення багатопотокових програм.
Процеси можуть створюватися ядром системи під час її ініціалізації. Наприклад, в UNIX-сумісних системах таким процесом може бути процес ініціалізації системи іnit, у Windows ХР - процеси підсистем середовища (Win32 або POSIX). Таке створення процесів, однак, є винятком, а не правилом.
Найчастіше процеси створюються під час виконання інших процесів. У цьому разі процес, який створює інший процес, називають предком, а створений ним процес - нащадком.
Нові процеси можуть бути створені під час роботи застосування відповідно до його логіки (компілятор може створювати процеси для кожного етапу компіляції, веб-сервер - для обробки прибулих запитів) або безпосередньо за запитом користувача (наприклад, з командного інтерпретатора, графічної оболонки або файлового менеджера).
Розрізняють два типи процесів з погляду їхньої взаємодії із користувачем - інтерактивні та фонові.
§ Інтерактивні процеси взаємодіють із користувачами безпосередньо, приймаючи від них дані, введені за допомогою клавіатури, миші тощо. Прикладом інтерактивного процесу може бути процес текстового редактора або інтегрованого середовища розробки.
§ Фонові процеси із користувачем не взаємодіють безпосередньо. Зазвичай вони запускаються під час старту системи і чекають на запити від інших застосувань. Деякі з них (системні процеси) підтримують функціонування системи (реалізують фонове друкування, мережні засоби тощо), інші виконують спеціалізовані задачі (реалізують веб-сервери, сервери баз даних тощо). Фонові процеси також називають службами (services, у системах лінії Windows ХР) або демонами (daemons, в UNIX).
Ієрархія процесів
Після того як процес-предок створив процес-нащадок, потрібно забезпечити їхній взаємозв'язок. Є різні варіанти розв'язання цього завдання.
Можна організувати на рівні ОС однозначний зв'язок «предок-нащадок» так, щоб для кожного процесу завжди можна було визначити його предка. Наприклад, якщо процеси визначені унікальними ідентифікаторами, то для реалізації цього підходу в керуючому блоці процесу-нащадка повинен завжди зберігатися ідентифікатор процесу-предка або посилання на його керуючий блок.
Таким чином формується ієрархія (дерево) процесів, оскільки нащадки можуть у свою чергу створювати нових нащадків і т. ін. У таких системах існує спеціальний вихідний процес (в UNIX-системах його називають іnit), з якого починається побудова дерева процесів (його запускає ядро системи). Якщо предок завершить виконання свого процесу перед своїм нащадком, функції предка бере на себе вихідний процес.
З іншого боку, зв'язок «предок-нащадок» можна не реалізовувати на рівні ОС. При цьому всі процеси виявляються рівноправними. Якщо зв'язок «предок-нащадок» для конкретної пари процесів все ж таки потрібен, за його підтримку відповідають самі процеси (процес-предок, наприклад, може сам зберегти свій ідентифікатор у структурі даних нащадка у разі його створення).
Взаємозв'язок між процесами не обмежується лише відношеннями «предок-нащадок». Наприклад, у деяких ОС є поняття сесії (session). Така сесія поєднує всі процеси, створені користувачем за час інтерактивного сеансу його роботи із системою.
4.
Існує три варіанти завершення процесів.
Процес коректно завершується самостійно після виконання своєї задачі (для інтерактивних процесів це нерідко відбувається з ініціативи користувача, який, приміром, скористався відповідним пунктом меню). Для цього код процесу має виконати системний виклик завершення процесу. Такий виклик у POSIX-систе-мах називають exit (). Він може повернути процесу, що його викликав, або ОС код повернення, який дає змогу оцінити результат виконання процесу.
Процес аварійно завершується через помилку. Такий вихід може бути передбачений програмістом (під час обробки помилки приймається рішення про те, що далі продовжувати виконання програми неможливо), а може бути наслідком генерування переривання (ділення на нуль, доступу до захищеної області пам'яті тощо).
Процес завершується іншим процесом або ядром системи. Наприклад, перед закінченням роботи ОС ядро припиняє виконання всіх процесів. Процес може припинити виконання іншого процесу за допомогою системного виклику, який у POSIX-системах називають kill ().
Після того як процес завершить свою роботу, пам'ять, відведена під його адресний простір, звільняється і може бути використана для інших потреб. Усі потоки цього процесу теж припиняють роботу. Якщо у даного процесу є нащадки, їхня робота переважно не припиняється слідом за роботою предка. Інтерактивні процеси завершуються у разі виходу користувача із системи.
5.
Коли у системі з'являється новий процес, для старого процесу є два основних варіанти дій:
§ продовжити виконання паралельно з новим процесом - такий режим роботи називають асинхронним виконанням;
§ призупинити виконання доти, поки новий процес не буде завершений, — такий режим роботи називають синхронним виконанням. (У цьому разі використовують спеціальний системний виклик, який у POSIX-системах називають wait().)
Вибір того чи іншого режиму залежить від конкретної задачі. Так, наприклад, веб-сервер може створювати процеси-нащадки для обробки запитів (якщо наявного набору нащадків недостатньо для такої обробки). У цьому разі обробка має бути асинхронною, бо відразу після створення нащадка предок має бути готовий до отримання наступного запиту. З іншого боку, компілятор С під час запуску процесів, що відповідають етапам компіляції, має чекати завершення кожного етапу, перш ніж перейти до наступного, - у такому разі використовують синхронну обробку.
6.
|
|
|
|
|
Дата добавления: 2014-10-23; Просмотров: 1943; Нарушение авторских прав?; Мы поможем в написании вашей работы!