КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Статистический подход к измерению информации
|
|
|
|
Тема: «Расчет количества информации по мерам Хартли и Шеннона».
Расчетно-графическая работа №1
1 Теоретическая часть
В информатике, как правило, измерению подвергается информация, представленная дискретным сигналом. При этом различают следующие подходы:
1) структурный подход. Измеряет количество информации простым подсчетом информационных элементов, составляющих сообщение. Применяется для оценки возможностей запоминающих устройств, объемов передаваемых сообщений, инструментов кодирования без учета статистических характеристик их эксплуатации.
2) статистический подход. Учитывает вероятность появления сообщений: более информативным считается то сообщение, которое менее вероятно, т.е. менее всего ожидалось. Применяется при оценке значимости получаемой информации.
3) семантический подход. Учитывает целесообразность и полезность информации. Применяется при оценке получаемой информации.
1.1 Аддитивная (логарифмическая) мера (структурный подход)
Эта мера предложена в 1928 году американским ученым Хартли, поэтому имеет второе название – мера Хартли. Хартли впервые ввел специальное обозначение для количества информации – I и предложил следующую логарифмическую зависимость между количеством информации и мощностью исходного алфавита:
I = l log2 h, (1.1)
где I – количество информации, содержащейся в сообщении;
l – длина сообщения;
h – мощность исходного алфавита;
Для k источников информации:
I = I1 +…+Ik. (1.2)
При исходном алфавите {0,1}; l = 1; h = 2 и, имеем
I = 1*log22 = 1. (1.3)
Формула (1.3) даёт аналитическое определение бита (BIT - BI nary digi T) по Хартли: это количество информации, которое содержится в двоичной цифре.
Единицей измерения информации в аддитивной мере является бит.
В 30-х годах ХХ века американский ученый Клод Шеннон предложил связать количество информации, которое несет в себе некоторое сообщение, с вероятностью получения этого сообщения.
Вероятность p – количественная априорная (т.е. известная до проведения опыта) характеристика одного из исходов (событий) некоторого опыта. Измеряется в пределах от 0 до 1. Если заранее известны все исходы опыта, сумма их вероятностей равна 1, а сами исходы составляют полную группу событий. Если все исходы могут свершиться с одинаковой долей вероятности, они называются равновероятными.
Например, пусть опыт состоит в сдаче студентом экзамена по ТОИ. Очевидно, у этого опыта всего 4 исхода (по количеству возможных оценок, которые студент может получить на экзамене). Тогда эти исходы составляют полную группу событий, т.е. сумма их вероятностей равна 1. Если студент учился хорошо в течение семестра, значения вероятностей всех исходов могут быть такими:
p (5) = 0,5; p (4) = 0,3; p (3) = 0,1; p (2) = 0,1. (1.4)
Здесь запись p (j) означает вероятность исхода, когда получена оценка j (j = {2, 3, 4, 5}).
Если студент учился плохо, можно заранее оценить возможные исходы сдачи экзамена, т.е. задать вероятности исходов, например, следующим образом:
p (5) = 0,1; p (4) = 0,2; p (3) = 0,4; p (2) = 0,3. (1.5)
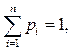 |
В обоих случаях выполняется условие:
где n – число исходов опыта,
i – номер одного из исходов.
Пусть можно получить n сообщений по результатам некоторого опыта (т.е. у опыта есть n исходов), причем известны вероятности получения каждого сообщения (исхода) - pi. Тогда в соответствии с идеей Шеннона, количество информации I в сообщении i определяется по формуле (1.6):
I = -log2 p i, (1.6)
где p i – вероятность i -го сообщения (исхода).
Соотношение (1.6) позволяет определять также размер двоичного эффективного кода, требуемого для представления того или иного сообщения, имеющего определенную вероятность появления.
|
 |
Помимо информационной оценки одного сообщения, Шеннон предложил количественную информационную оценку всех сообщений, которые можно получить по результатам проведения некоторого опыта. Так, среднее количество информации I ср, получаемой со всеми n сообщениями, определяется по формуле.
где pi – вероятность i-го сообщения.
На практике часто вместо вероятностей используются частоты исходов. Это возможно, если опыты проводились ранее и существует определенная статистика их исходов.
Усложним задачу.
Пусть сообщение – набор длиной N символов русского алфавита. Пусть опыт состоит в появлении той или иной буквы исходного алфавита в сообщении. Вероятности (или частоты) исходов известны: pi – вероятность появления символа i. Тогда полное количество информации, доставленное отрезком из N сигналов, где N =N1+..+Nm при Ni – число вхождений i -ого типа буквы в сообщение, будет рассчитываться по формуле (1.8):
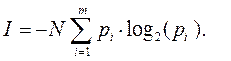 | |||
| |||
Пусть у опыта два равновероятных исхода, составляющих полную группу событий, т.е. p 1 = p 2 = 0,5. Тогда имеем в соответствии с (1.7):
I ср = -(0,5*log20,5 + 0,5*log20,5) = 1. (1.9)
Формула (9) есть аналитическое определение бита по Шеннону: это среднее количество информации, которое содержится в двух равновероятных исходах некоторого опыта, составляющих полную группу событий.
Формула, предложенная Хартли, представляет собой частный случай более общей формулы Шеннона. Если имеется N равновероятных исходов некоторого опыта, то от формулы (8) мы приходим к формуле (1.1)
Единица измерения информации при статистическом подходе – бит.
2 Примеры решения задач
Пример 1 (структурный подход). Рассчитать количество информации, которое содержится в шестнадцатеричном и двоичном представлении ASCII-кода для числа 1.

Пример 2 (структурный подход). Рассчитать количества информации для сообщений «Информатика» и «30-е годы 20-ого века» без учета кавычек.
Пример 3. Какое количество вопросов достаточно задать вашему собеседнику, чтобы наверняка определить месяц, в котором он родился?
Пример 4 (статистический подход). Определить количество информации, содержащейся в сообщении о результате сдачи экзамена для студента из (1.4) и (1.5).
Пример 5 (статистический подход). Определить среднее количество информации, получаемое студентом из (1.4) и (1.5), по всем результатам сдачи экзамена.
Пример 6 (статистический подход). Рассчитать количества информации для сообщений «Информатика» и «30-е годы 20-ого века» без учета кавычек.
| Буква | Частота | Буква | Частота | Буква | Частота |
| о | 0,090 | м | 0,026 | й | 0,010 |
| е (ё) | 0,072 | д | 0,025 | х | 0,009 |
| а | 0,062 | п | 0,023 | ж | 0,007 |
| и | 0,062 | у | 0,021 | ю | 0,006 |
| т | 0,053 | я | 0,018 | ш | 0,006 |
| н | 0,053 | ы | 0,016 | ц | 0,004 |
| с | 0,045 | з | 0,016 | щ | 0,003 |
| р | 0,040 | ь,ъ | 0,014 | э | 0,003 |
| в | 0,038 | б | 0,014 | ф | 0,001 |
| л | 0,035 | г | 0,013 | пробелы и знаки препинания | 0,175 |
| к | 0,028 | ч | 0,012 |
3 Задание
Для выбранной в соответствии с вариантом задания задачи:
1) Рассчитать количество информации в сообщении по формуле Хартли.
2) Рассчитать количество информации в сообщении по формуле Шеннона.
3) Выполнить сравнительный анализ результатов расчетов.
4) Сделать выводы.
4 Содержание отчета
1) Определение понятия «Количество информации».
2) Мера Р.Хартли.
3) Подробный расчет количества информации, содержащейся в сообщении по формуле Хартли.
4) Мера К.Шеннона.
5) Подробный расчет количества информации, содержащейся в сообщении по формуле Хартли (привести таблицу вероятностей появления букв русского алфавита в сообщениях)
6) Анализ результатов и выводы.
5 Варианты задания
Вариант задания формируется каждым студентом индивидуально следующим образом. От источника к приемнику передается следующее сообщение: «Фамилия Имя Отчество день. месяц. год город-рождения». Каждый студент использует в качестве варианта задания свои фамилию, имя и отчество, далее – день, месяц, год и город рождения. Все семь частей сообщения разделены одним пробелом. Например: «Иванов Семен Петрович 10 11 1992 Москва».
6 Список литературы
1. Информатика. Базовый курс. / Под ред. С.В.Симоновича. — Спб., 2000 г.
2. Информатика. Компьютерная техника. Компьютерные технологии. / Пособие под ред. О.И.Пушкаря.— Издательский центр "Академия", Киев, — 2001 г.
3. Казиев В.М. Введение в анализ, синтез и моделирование систем. М.: Бином, 2007.
4. Коцюбинский А.О., Грошев С.В. Современный самоучитель профессиональной работы на компьютере. — Г.: Триумф, 1999 г.
|
|
|
|
|
Дата добавления: 2014-10-31; Просмотров: 3250; Нарушение авторских прав?; Мы поможем в написании вашей работы!