КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Колонтитулы 5 страница
|
|
|
|
· каждый столбец имеет уникальное, то есть неповторяющееся в других столбцах, имя;
· последовательность столбцов в таблице не существенна;
· все строки таблицы организованы по одинаковой структуре, то есть имеют одно и то же количество реквизитов и имеют одинаковую длину;
· количество строк в таблице практически не ограничено;
· последовательность строк в таблице несущественна;
Ключевые поля
Для идентификации записи таблицыиспользуются специальные поля. Это может быть одно или несколько полей, набор значений которых позволяют однозначно отличать одну запись таблицы от другой (один экземпляр объекта от другого). Этот набор специальных полей называется первичным ключом. Таким образом, первичный ключ однозначно идентифицирует каждую запись таблицы. Идеальный ключ должен быть коротким и редко меняться. Иногда чтобы не объявлять первичным ключом длинную текстовую строку, вводят дополнительное поле (например, код объекта), назначение которого – иметь уникальное значение и быть уникальным идентификатором экземпляра объекта.
В реляционной базе данных между таблицами устанавливаются связи. Связь между двумя таблицами устанавливается по ключевым полям, содержащим одинаковую информацию для обеих таблиц. Связывается первичный ключ главной таблицы с соответствующим полем подчиненной таблицы, которое называется полем внешнего ключа.
В реляционной базе должны соблюдаться условия целостности данных:
· значение первичного ключа должно быть уникальным и непустым:
· каждое значение внешнего ключа должно совпадать с одним из значений первичного ключа.
Итак, реляционная база данных представляет собой совокупность взаимосвязанных таблиц. При проектировании такой базы данных необходимо соблюдение следующих принципов (принципов реляционного подхода):
· Количество таблиц должно быть минимальным.
· Таблицы должны быть нормализованными.
Нормализация представляет собой процесс повышения эффективности организации базы данных, в результате которого одно множество таблиц заменяется по определенным правилам другим множеством.
После нормализации база данных учебного примера может состоять из таблиц 2.2 ‑ 2.6.
Таблица 11.2
Таблица Группы
| ÑКодГруппы | НаименГруппы | ФормаОбучения | Коэффициент |
| 73эи | Дневная | 1,2 | |
| 68им | Дневная | 1,2 | |
| 72эи | Дневная | 1,4 | |
| 5тк | Заочная | 0,3 | |
| 64м | Вечерняя |
Таблица 11.3
Таблица Преподаватели
| ÑТабНомПреп | Фамилия | ПедСтаж | Должность |
| Иванов | |||
| Петров | |||
| Астрахан | |||
| Квачук | |||
| Чиж |
Таблица 11.4
Таблица Должности БД ВУЗ
| КодДолжности | НаименДолжности |
| Профессор | |
| Доцент | |
| Старший преподаватель | |
| Ассистент |
Таблица 11.5
Таблица Дисциплины БД ВУЗ
| КодДисциплины | НаименДисциплины | КоличествоЧасов |
| КИТ | ||
| ИТ | ||
| Высшая математика | ||
| ЭММ | ||
| Макроэкономика | ||
| История Беларуси | ||
| Всемирная история |
Таблица 11.6
Таблица Экзамены БД ВУЗ
| Группа | Дисциплина | Преподаватель | Дата | ВремяНач | ВремяКон | Аудитория |
| 05.06.2010 | 8:15 | 12:30 | ||||
| 10.06.2010 | 10:00 | 14:00 | ||||
| 14.06.2010 | 8:15 | 12:30 | 315а | |||
| 26.06.2010 | 8:15 | 14:00 | ||||
| 30.06.2010 | 10:00 | 14:30 | ||||
| 04.06.2010 | 8:30 | 15:00 | ||||
| 09.06.2010 | 10:00 | 14:30 | ||||
| 18.06.2010 | 8:30 | 12:20 | ||||
| 24.07.2010 | 10:00 | 15:30 | 315а | |||
| 29.06.2010 | 12:00 | 16:30 |
3. Операции реляционной алгебры
В реляционной БД таблицу называют отношением, строку таблиц – кортежем, а столбец – атрибутом.
Операции над отношениями:
23. Выборка
Рис. 11.5. Операция «Выборка»
Результатом выборки отношения по некоторому условию являются отношение, которое включает только те картежи первоначального отношения, которое удовлетворяют этому условию.
24. Проекция
Рис. 11.5. Операция «Проекция»
При осуществлении проекции отношения на заданный набор его атрибутов будет получено отношение, картежи, которого взяты из картежей первоначального отношения и имеют только заданные атрибуты.
25. Объединение


Рис. 11.5. Операция «Объединение»
При объединении будет получено отношение, включающее все картежи, входящие хотя бы в одно из участвующих в операции отношений.
26. Пересечение

 
|
Рис. 11.5. Операция «Пересечение»
Результатом пересечения 2-ух отношений получается отношение, включающее все картежи, входящие в оба первоначальные отношения.
27. Разность (вычитание)
 |
Рис. 11.5. Операция «Разность»
Разность двух отношений включает все картежи, входящие в 1-ое отношение, но не входящие во 2-ое.
4. Постреляционная, объектно-ориентированная, объектно-реляционная, многомерная модели данных
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. По сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из нескольких таблиц. Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеет большую гибкость. Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. К числу СУБД, основанных на постреляционной модели данных, относятся системы Bubba и Dasdb. Adabas, Pick, Univers.
Объектно-ориентированные модели данных. Объектно-ориентированная модель представляет собой структуру, которую можно изобразить в виде дерева, узлами которого являются объекты. Каждый объект характеризуется уникальным идентификатором, состоянием и поведением. Состояние объекта определяется множеством значений его атрибутов. Поведение объекта описывают методы, называемые процедурами, способные производить действия над атрибутами объекта в случае наступления тех или иных событий.
Объекты могут объединяться в классы. Экземпляры одного класса отличаются лишь значением своих свойств, но не своими методами. Методы устанавливаются при определении класса.
Для выполнения действий над объектами применяются объектно-ориентированные механизмы – наследование, инкапсуляция, полиморфизм.
· инкапсуляция предполагает, что доступ к данным, определяющим внутреннее состояние объекта осуществляется только в соответствии с правилами поведения объекта, описываемыми соответствующими методами. Объекты рассматриваются как самостоятельные сущности, отделенные от внешнего мира;
· наследование подразумевает возможность создавать из классов объектов новые классы, объекты которых наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность; наследование может быть простым (один предок) и множественным (несколько предков);
· полиморфизм – способность объектов по-разному реагировать на одно и то же событие в окружающем мире в зависимости от того, как реализованы их методы. Полиморфизм используется для унификации обработки разнородных объектов.
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
· автоматическое поддержание отношений наследования;
· –возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов, такие поля и методы используются только методами самого объекта;
· создание процедур контроля целостности внутри объекта.
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Достоинством объектно-ориентированной модели является способность отображать информацию о сложных объектах с исчерпывающим описанием взаимосвязей между ними и их динамического поведения.
Недостатком объектно-ориентированной модели является сложность понятийного аппарата, что затрудняет ее применение и отрицательно сказывается на накоплении опыта создания и эксплуатации объектно-ориентированных баз данных.
Объектно-реляционная модель данных является гибридной моделью, сочетающей возможности реляционной модели с объектными свойствами данных. Отличительная особенность объектно-реляционной модели состоит в том, что она основана на стратегии реляционной модели. Так, последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются «чисто» реляционными.
Многомерный подход к представлению данных в базе появился одновременно с реляционным. Толчком послужила статья одного из основоположников реляционного подхода Э. Кодда. В ней сформулированы 12 основных требований к системам OLAP (OnLine Analytical Processing —оперативная аналитическая обработка), важнейшие из которых связанны с возможностями концептуального преставления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения.
В развитии концепции ИС можно выделить следующие два направления:
· Системы оперативной (транзакционной) обработки;
· Системы аналитической обработки (системы поддержки принятий решений).
Реляционные СУБД предназначены для информационных систем оперативной обработки информации и в это области они весьма эффективны. В системах аналитической обработки более эффективными оказываются многомерные СУБД (МСУБД). Многомерные СУБД являются узкоспециализированными.
В МСУБД реализованы следующие принципы организации данных: агрегируемость, историчность, прогнозируемость данных.
Агрегируемость данных означает возможность рассмотрения информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь оператор, управляющий, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности (неизменности)собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализаций цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью.
Основные понятия многомерных моделей данных: измерение, ячейка.
Измерение (Dimension) – это множество однотипных данных, образующих одну из граней многомерного гиперкуба.
Ячейка (Cell) или показатель – это поле, значение которого однозначно определяется фиксированным набором измерений.
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающих многомерные модели данных, являются Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle) и Cache (InterSystems). Некоторые программные продукты, например Media/MR (Speedware), позволяют одновременно работать с многомерными и с реляционными БД. В СУБД Cache, в которой внутренней моделью данных является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
Контрольные вопросы
28. Назовите модели данных, используемые при создании баз данных.
29. Изложите суть сетевой и иерархической моделей данных.
30. Каковы особенности реляционной модели данных.
31. Охарактеризуйте операции реляционной алгебры?
32. Опишите постреляционную модель данных.
33. В чем заключаются достоинства и недостатки постреляционной модели данных?
34. Каковы отличительные черты объектно-ориентированной модели данных.
35. Изложите достоинства и недостатки объектно-ориентированной модели данных.
36. Чем характерна многомерная модель данных?
37. Какие принципы организации данных реализованы в многомерных СУБД?
Лекция 12
Системы управления базами данных (СУБД).
38. Понятие СУБД. Архитектура СУБД.
39. Функциональные возможности СУБД.
40. Языковые и программные средства СУБД.
41. Классификация СУБД.
42. Базы знаний.
1. Понятие СУБД. Архитектура СУБД
База данных – это совокупность данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования данными, независимо от прикладных программ.
База данных отражает состояние объектов и их отношений в рассматриваемой предметной области.
Система управления базами данных – СУБД (Data Base Management System – DBMS) – совокупность языковых, программных и предметных средств, предназначенных для создания, ведения и совместного использования базы данных многими пользователями.
Архитектура СУБД
Независимость прикладных программ от данных обеспечивается наличием трех уровней представления данных в СУБД.
В 1978 году учеными была принята трехуровневая система организации данных, предложенная Национальным Институтом стандартизации – ANSI (American National Standards Institute) и Комитетом по планированию выпуска стандартов и технических условий – SPARC Соединенных штатов Америки.
Предлагается выделять три уровня представления данных: внешний, концептуальный и внутренний (Рис. 3.1).
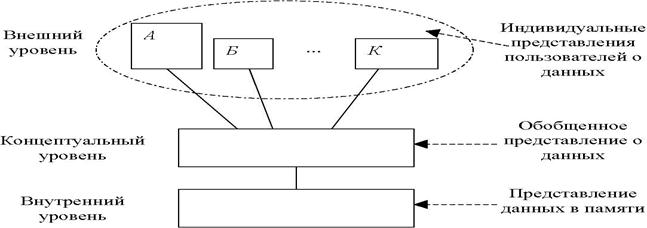
Рис. 12.1. Три уровня представления данных в СУБД.
43. Внутренний уровень – уровень, наиболее близкий к физическому, связанный со способами представления информации на физических устройствах;
44. Внешний уровень – наиболее близок к пользователям; связан со способами представления данных для отдельных пользователей.
45. Концептуальный уровень – промежуточный уровень между двумя первыми.
Внешний уровень – это уровень пользователя. У каждого пользователя есть свой язык общения. Например, для прикладного программиста - это язык программирования(C, Delphi) или специальный язык рассматриваемой системы. Для конечного пользователя – это специальный язык запросов или язык специального назначения. Большинство СУБД поддерживают язык SQL, который может использоваться как отдельный язык запросов и, как язык, встроенный в другие языки.
Отдельного пользователя интересует только небольшая часть БД и пользовательское представление, может быть чем – то абстрактным по сравнению с физическим представлением данных. Представление одного пользователя называется внешним представлением. Каждое внешнее представление определяется средствами внешней схемы.
Концептуальное представление – это представление общего содержания БД с учетом всех внешних представлений.
Концептуальное представление определяется средствами концептуальной схемы.
Внутреннее представление – это совокупность экземпляров различных типов внутренних записей. Внутреннее представление описывается с помощью внутренней схемы (рис. 3.2).
СУБД обеспечивает отображение (преобразование) данных одного уровня в данные другого уровня. Это определяет свойство независимости данных. Так при изменении структуры хранения (внутренний уровень) отображение концептуальный - внутренний должно измениться так, чтобы концептуальная схема не изменилась.
2. Функциональные возможности СУБД
Основным назначением БД в первую очередь является надежное хранение и быстрый доступ к информации. К функциям СУБД относятся следующие:
46. управление данными, непосредственно в БД – функция, обеспечивающая хранение данных, непосредственно входящих в БД и служебной информации, определяющей работу СУБД;
47. управление данными в памяти компьютера – функция, связанная с буферизацией данных в операционной памяти ПК с целью ускорения работы СУБД;
48. управление транзакциями (транзакция- манипуляция над данными) – функция СУБД, которая производит операции над БД, как над единым целым.
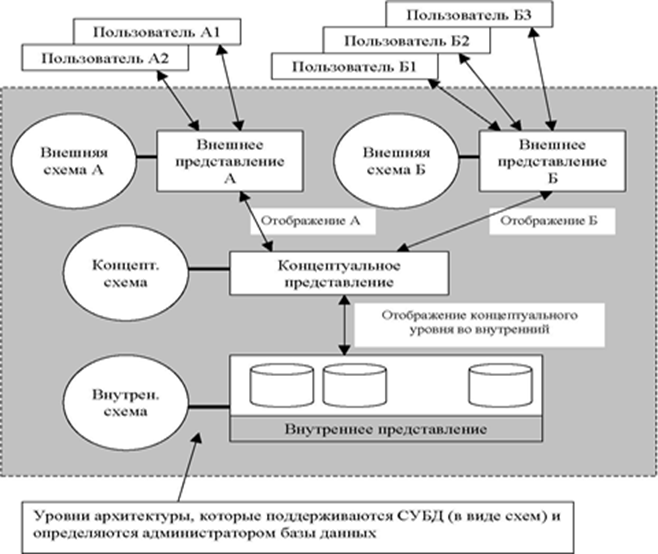 Рис. 12.2. Архитектура СУБД
Рис. 12.2. Архитектура СУБД
Транзакции – это группа операций над данными, которые либо выполняются все вместе, либо все вместе отменяются.
Завершение транзакции означает, что все операции, входящие в состав транзакции, успешно завершены, и результат их работы сохранен в базе данных.
Откат транзакции означает, что все уже выполненные операции, входящие в состав транзакций, отменяются, и все объекты базы данных, затронутые этими операциями, возвращаются в исходное состояние. Для реализации возможного отката транзакций многие СУБД поддерживают запись в журналы транзакций, позволяющие восстановить исходные данные при откате. Транзакция может состоять из нескольких вложенных транзакций;
49. управление изменениями в БД и протоколирование - функция, связанная с надежностью хранения информации, которая обеспечивает возможность СУБД восстановить состояние БД в аварийных ситуациях (пример: при случайном выключении питания). Для восстановления БД после сбоя СУБД использует протокол и архивную копию БД;
50. поддержка языков БД.
3. Языковые и программные средства СУБД
Функциональные возможности СУБД доступны пользователям благодаря ее реализации в виде комплекса языковых и программных средств.
С помощью языковых средств обеспечивается доступ пользователей к базе данных в абстрактных терминах, не связанных со способами хранения данных в компьютере. На языковые средства возлагаются две основные функции – описание базы данных и выполнения операций манипулирования данными.
Описание базы данных осуществляется с помощью языка определения данных – ЯОД (Data Definition Language – DDL). ЯОД предоставляет пользователя средства указания структуры данных и их типа, а также средство задания ограничений для данных, хранимых в базе.
Язык манипулирования данными – ЯМД (Data Manipulation language – DML) позволяет вставлять, обновлять, удалять и извлекать данные из базы.
ЯОД и ЯМД в большинстве современных СУБД не оформляются синтаксически в виде самостоятельных языков, а являются частью единого языка данных, сочетающего возможности определения данных и манипулирования ими.
Во многих СУБД используется еще один класс языков – язык запросов. Первоначально этот язык обеспечивал только выборку данных из базы, в настоящее время его функции расширились и включают возможности выполнения всех операций над данными в базе. Примером такого языка может служить язык SQL.
Языковые средства могут быть реализованными различными способами: синтаксическими конструкциями (командами), меню, диалоговыми сценариями, таблицами.
Некоторые СУБД располагают встроенными языками программирования, которые могут использоваться как для обращения к данным базы, так и для создания прикладных программ. Примерам такого рода языка может служить язык Visual Basic for Application (VBA) – язык программирования, встроенный в приложения пакета MS Office, в том числе в СУБД MS Access.
В случае необходимости сложной аналитической обработки данных базы, не достигаемой с помощью языков баз данных, можно разрабатывать прикладные программы на традиционных языках программирования.
Программные средства СУБД реализуют функции хранения, изменения, обработки информации. Любая СУБД состоит из нескольких программных компонентов, каждый из которых выполняет специфические операции. В реляционных СУБД можно выделить, например, менеджер данных, менеджер буферов, менеджер транзакций и др.
4. Классификация СУБД
По функциональным возможностям СУБД подразделяются на
· персональные (настольные);
· многопользовательские (серверные).
Персональные СУБД предназначены для создания и обработки недорогих однопользовательских баз данных. Правда, в настоящее время появились сетевые конфигурации однопользовательских СУБД, позволяющие работать нескольким пользователям с одной базой данных. В данной ситуации реализована компьютерная архитектура Файл / Сервер (рис. 3.3).
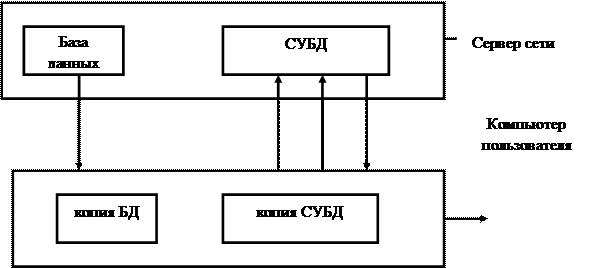 |
Рис.12.3. Компьютерная архитектура Файл / Сервер
Кроме того, персональные СУБД и разрабатываемые для них приложения могут выступать в роли клиентской части многопользовательских СУБД. К персональным СУБД относятся: FoxPro, Paradox, Clipper, Microsoft Access и др.
Microsoft Access может быть использована, с одной стороны, в качестве настольной СУБД и составной части офисного пакета, а с другой стороны, в качестве клиента сетевой СУБД Microsoft SQL Server, позволяющего манипулировать его данными, его администрирование и создание приложений для этого сервера.
Серверные же СУБД изначально ориентированы на многопользовательскую обработку базы данных. Они базируются на компьютерной архитектуре Клиент / Сервер (рис.2.4), которая обеспечивает наиболее эффективную работу с централизованной БД. Централизация хранения и обработки данных является базовым принципом этой компьютерной архитектуры.
Многопользовательские (серверные) СУБД включают сервер СУБД и клиентскую часть. Такие СУБД, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и ОС) к многопользовательским относятся: Microsoft SQL Server, Informix, Oracle и др.
На сервере сети размещается БД и устанавливается мощная серверная СУБД – сервер БД. На компьютере – клиенте устанавливается клиентское приложение (приложение – клиент), которое при необходимости формирует запрос к БД. Серверная СУБД обеспечивает интерпретацию запроса, его выполнение, формирование результата запроса и пересылку его (результата) по сети на клиентский компьютер. Клиентский компьютер интерпретирует его необходимым образом и представляет пользователю. Клиентское приложение может также посылать запрос на обновление БД и серверная СУБД внесет необходимые изменения в БД. В этом случае реализована компьютерная архитектура Клиент / Сервер (рис. 3.4).
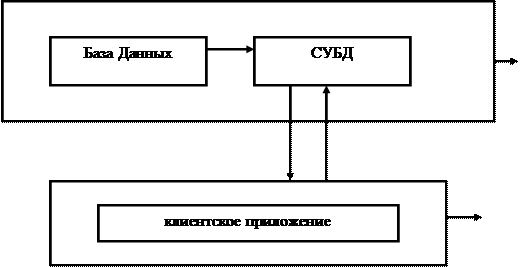
|

|
Рис. 12.4. Компьютерная архитектура клиент/сервер:
В архитектуре клиент/сервер функции клиентского приложения и серверной СУБД разделены. При использовании этой архитектуры уменьшается сетевой трафик, т.к. по сети передаются только запросы и результаты запросов. Файловые операции выполняются в основном на сервере, который мощнее клиентов и поэтому способен быстрее обслуживать запросы, в результате чего уменьшается потребность клиентских приложений в ОП.
Существенно повышается степень безопасности БД, т.к. правила целостности данных определяются в серверной СУБД и являются едиными для всех приложений, использующих эту БД.
|
|
|
|
|
Дата добавления: 2014-10-31; Просмотров: 450; Нарушение авторских прав?; Мы поможем в написании вашей работы!