КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Метод последовательного декодирования
|
|
|
|
Если простота алгоритмов порогового декодирования и, следовательно, простота их реализации стимулировали исследования сравнительно коротких кодов и повышение их корректирующих способностей, то проводившиеся параллельно исследования методов последовательного декодирования имели одной из своих главных целей практическую реализацию теоремы Шеннона для канала с шумами.
При последовательном декодировании число операций, которое должен выполнить декодер, для того чтобы декодировать один символ, изменяется в зависимости от уровня шумов в канале. Число операций при последовательном декодировании является функцией скорости передачи и шумов в канале. При всех скоростях передачи, меньших определенной скорости, число операций при декодировании оказывается небольшим. Последовательный декодер строится по логической схеме, позволяющей проводить вычисления со средней скоростью, в несколько раз большей скорости передачи символов, и включает в свой состав буферное запоминающее устройство, предназначенное для хранения поступающих данных при повышении уровня шумов в канале. В случае, если число возникших в канале ошибок превысит корректирующую способность кода, при последовательном декодировании и других методах декодирования могут возникать ошибки. Однако при последовательном декодировании ошибки могут возникать также и из-за того, что оказываются заполненными все ячейки памяти буферного запоминающего устройства, т. е. из-за переполнения буфера. Если вероятность ошибки из-за переполнения буфера оказывается значительно больше, чем вероятность возникновения ошибки из-за невозможности исправить или обнаружить ошибку, то именно она и будет определять характеристики алгоритма последовательного декодирования.
При рассмотрении алгоритмов последовательного декодирования удобно представлять сверточный код в виде кодового дерева, которое для кодера (рис. 2, б) приведено на рис. 9.
Кодовое дерево строится следующим образом. Исходному нулевому состоянию сдвигающего регистра кодера соответствует начальный узел дерева. Если входной информационный символ, поступающий в регистр, равен 1, то ему приписывается линия (ребро дерева), идущая, как принято на этом рисунке, вниз, а если информационный символ равен 0, – то вверх. Тем самым получаем два новых узла, соответствующие следующему такту работы кодера, для каждого из которых дерево строится далее аналогичным образом, и т.д. Над каждым ребром дерева записываются n кодовых символов, получаемых при этом на выходе кодера. Совокупность нескольких последовательных ребер, соединяющих какие-либо два узла, составляет ветвь дерева. Узлы, соединенные одним ребром, называются соседними. Для двоичных кодов в общем случае из каждого узла дерева будет исходить 2k ребер, каждому из которых сопоставлено n двоичных символов.
Коды, допускающие подобное представление с помощью кодового дерева, называются древовидными. Таким образом, сверточные коды относятся к древовидным.
Можно заметить, что рассмотренную ранее решеточную диаграмму кода можно получить из кодового дерева, если объединить те узлы дерева, после которых над cоответствующими ребрами оказываются одинаковые кодовые символы. Эти узлы помечены на рис. 9 одинаковыми буквами a, b, c, d и соответствуют состояниям кодера на диаграмме состояний (рис. 4.1).
Каждая последовательность кодируемых информационных символов порождает определенный путь по кодовому дереву. Например, информационная последовательность 1001…. порождает путь по кодовому дереву, показанный штриховой линией на рис. 2.2, которому соответствует последовательность кодовых символов 11101111… Очевидно, задача декодера заключается в отыскании истинного (правильного) пути, т. е. того пути, который в действительности был порожден кодером.
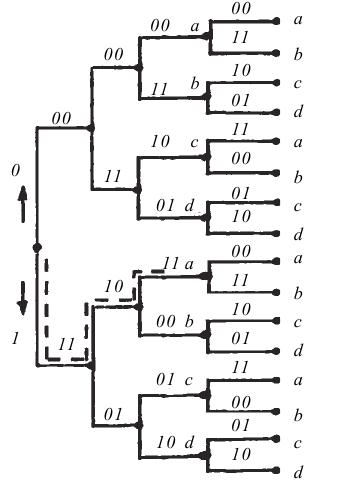
Рис.9. Кодовое дерево кодера (рис. 1.2, б)
Таким образом, при алгоритмах последовательного декодирования декодер определяет наиболее правдоподобный путь по дереву, что позволяет исключить из анализа большую часть остальных путей, имеющих меньшее правдоподобие.
Предположим, что задан некоторый сверточный код, и попытаемся по принятой последовательности определить передававшуюся последовательность. Для этого сначала необходимо передвигаться поочередно вдоль каждого пути кодового дерева, сравнивая принятую последовательность с последовательностью, соответствующей пути, по которому происходит движение. Если при этом удается обнаружить некоторый путь, которому соответствует последовательность, почти совпадающая с принятой последовательностью, то естественно считать, что эта последовательность и передавалась. Метод последовательного декодирования, предложенный Возенкрафтом, предусматривает вначале поиск на кодовом дереве пути из m-го ребра (m – число разрядов регистра сдвига кодера), соответствующая которому кодовая последовательность находится на каком-то определенном расстоянии от переданной последовательности, и далее декодирование первого информационного символа. Первым переданным информационным символом считается первый информационный символ первого ребра найденного пути. Поскольку далее декодирование второго и последующих информационных символов осуществляется точно так же, как и первого информационного символа, то этот алгоритм и был назван алгоритмом последовательного декодирования.
Одним из критериев близости пути на кодовом дереве к принятой последовательности является расстояние Хемминга между ними. Если расстояние Хемминга между последовательностями с длиной n0, равной числу обработанных двоичных символов, не превышает определенный порог D0, то последовательности можно считать совпадающими. В случае двоичного симметричного канала порог D0 выбирается таким образом, чтобы вероятность того, что расстояние Хэмминга между передававшейся и принятой последовательностями было больше чем D0, не превышало величины 2–L, где L – некоторая заданная постоянная. При этом вероятность того, что расстояние Хемминга между правильным путем дерева и принятой последовательностью больше чем D0, при больших L оказывается чрезвычайно малой.
Предположим, что этот метод декодирования используется в двоичном симметричном канале с вероятностью перехода p. Напомним, что в двоичном симметричном канале без памяти каждый переданный кодовый символ может быть принят ошибочно с вероятностью р и правильно с вероятностью q = 1–p, причем в случае ошибки вместо переданного символа 0 на приемной стороне воспроизводится символ 1, или –наоборот. Для канала без памяти вероятность ошибочного приема символа не зависит от того, какие символы переданы до него и как они были приняты. На рис. 2.3 показаны вероятности перехода для двоичного симметричного канала.
Поскольку в канале ошибки возникают независимо с вероятностью перехода р, то расстояние Хемминга d, вычисляемое вдоль правильного пути, как показано на рис. 2.4, почти всегда будет возрастать со скоростью p с ростом числа обработанных символов n0. В то же время расстояние Хемминга, вычисляемое вдоль любого другого пути кодового дерева, будет возрастать со скоростью 1/2, поскольку различные пути кодового дерева отличаются друг от друга приблизительно в половине символов. Таким образом, расстояния Хемминга, вычисленные вдоль правильного и ошибочного пути кодового дерева, оказываются различными. При этом, даже если на начальном этапе декодирования путь кодового дерева был выбран неправильно, то через некоторое время ошибка будет обнаружена, поиск правильного пути будет продолжен и в конце концов правильный путь будет найден.
Этот алгоритм последовательного декодирования был обобщен Рейффеном на случай произвольного дискретного канала без памяти.
Обобщение было сделано путем замены расстояния Хемминга на другую функцию (“перекошенное” расстояние), являющуюся обобщением расстояния Хемминга, которая была названа ценой пути.
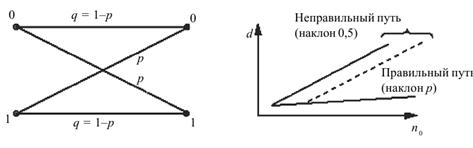
Рис. 10. Вероятности Рис. 11. Зависимость расстояния
переходов для двоичного Хемминга d от числа
симметричного канала декодированных символов – n0
Другим алгоритмом последовательного декодирования является алгоритм, предложенный Фано, который предусматривает вычисление и использование при декодировании наряду с ценой пути также некоторых порогов. Этот алгоритм является алгоритмом того же типа, что и алгоритм Возенкрафта, но для него среднее число операций, необходимых для декодирования одного символа, не зависит от длины кодового ограничения. Это упрощает анализ алгоритма Фано. Кроме того, достоинством алгоритма Фано является также то, что он допускает более простую техническую реализацию. Поскольку сложность декодера Фано не зависит от длины кодового ограничения, то это позволяет использовать его при больших ДКО, т. е. при малых вероятностях ошибки на декодированный символ.
Еще одним известным алгоритмом последовательного декодирования является алгоритм Зигангирова, предложенный в 1966 г., являющийся алгоритмом декодирования по максимуму правдоподобия.
Этот алгоритм иногда называют стэк-алгоритмом (от английского stack – кипа, стопа), так как для его реализации требуется память большой емкости, содержимое которой постоянно упорядочивается определенным образом, т. е. требуется “кипа памяти”.
В качестве метрики (расстояний Хемминга) путей по кодовому дереву при этом алгоритме также используется функция правдоподобия пути (цена пути), но с добавлением элемента смещения, величина которого определяется исходя из скорости используемого кода и пропускной способности канала, путем оптимизации вероятности ошибки декодирования и среднего числа операций при декодировании одного информационного символа.
Количество вычислений на один декодированный информационный символ, которые производит декодер при данном алгоритме декодирования, является случайной величиной, что характерно для всех алгоритмов последовательного декодирования, так как все они являются вероятностными. Количество производимых декодером вычислений тем меньше, чем ниже уровень шума в канале, т. е. чем меньше вероятность ошибок при приеме кодовых символов в первой решающей схеме приемника. Для компенсации этой неравномерности вычислений при всех алгоритмах последовательного декодирования требуется включение буферного запоминающего устройства (ЗУ) между собственно последовательным декодером и первой решающей схемой приемника. Однако в том случае, когда объем производимых вычислений оказывается очень большим (“всплеск вычислений”, соответствующий “плохому” состоянию канала связи), возможно переполнение буферного ЗУ, что приводит к отказу в декодировании. Это является недостатком всех методов последовательного декодирования. Однако сложность этих методов либо слабо, либо совсем не зависит от длины кодовых ограничений, что позволяет использовать большую длину кодовых ограничений, а следовательно, достигнуть большой эффективности корректирующего сверточного кода.
Для борьбы с отказами в декодировании при методах последовательного декодирования, кроме очевидных способов увеличения объема буферного ЗУ и быстродействия декодера, можно через определенное заранее число информационных символов, соответствующее с заданной вероятностью времени наступления отказа в декодировании, передавать последовательность заранее известных символов, например последовательность нулей. Тем самым декодер устанавливается на заведомо правильный путь по дереву. В случае наличия обратного канала возможна организация переспроса при наступлении отказа в декодировании.
Из-за присущей сверточным кодам непрерывности в обработке информации их синхронизация при декодировании осуществляется гораздо проще, чем при блочном кодировании. В частности, не требуется синхронизации по кодовым словам, без которой правильное декодирование блоковых кодов, как правило, невозможно. Однако для всех методов декодирования сверточных кодов необходима надежная синхронизация по узлам кодового дерева (узловая синхронизация), т. е. синхронизация по группам символов, соответствующих одному циклу опроса коммутатора кодера.
Структурная схема декодера Зигангирова будет выглядеть аналогично схеме декодера Витерби (рис. 2.9) с той разницей, что на входе декодера включено буферное ЗУ, куда поступают символы с первой решающей схемы приемника.
|
|
|
|
|
Дата добавления: 2014-11-08; Просмотров: 1729; Нарушение авторских прав?; Мы поможем в написании вашей работы!