КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Законы распределения случайных величин
|
|
|
|
При характеристике случайных величин недостаточно указать их возможные значения. Необходимо еще знать насколько часто возникают различные значения этой величины. Это характеризуется вероятностью p отдельных ее значений.
Соотношение, устанавливающее связь между значениями случайной величины и вероятностями этих значений, называют законом распределения случайной величины. Различают интегральный и дифференциальный законы распределения.
2.1. Виды случайных величин и законы их распределения
Под случайной величиной понимается величина, принимающая в результате опыта какое либо числовое или качественное значение.
Случайная величина, принимающая конечное число или последовательность различных значений, называется дискретной случайной величиной. Случайная величина, принимающая все значения из некоторого интервала, называется непрерывной случайной величиной.
Под интегральным законом распределения (или функцией распределения) F (х) случайной величины Х понимают вероятность p того, что случайная величина Х не превысит некоторого ее значения х
F (х) = p (Х < х).
Основным свойством интегрального распределения является монотонное не убывание в ограниченном диапазоне [ 0; 1 ].
Действительно, если х1 и х2 некоторые значения случайной величины Х. Причем х2 > х1, то очевидно, что событие p (Х < х2) ³ p (Х <х1), т.к. между значениями х1 и х2 могут быть и промежуточные. Из определения интегрального закона следует, что F (х2) ³ F (х1), что говорит о монотонном не убывании функции. Очевидно также, что
F (- ¥) = p (Х < - ¥) = 0;
Þ F (¥) - F (- ¥) = 1,
F (+ ¥) = p (Х < ¥) = 1;
т.е. F (х) изменяется в диапазоне от 0 до 1.
Для дискретной случайной величины
F (x) = P (X < x) = P (- ¥ < X < x) = 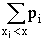 ,
,
 где суммирование распространяется на хi < х. В промежутке между двумя последовательными значениями Х функция F (х) постоянна. При переходе аргумента х через значение хi F (х) скачком возрастает на величину p (Х = хi).
где суммирование распространяется на хi < х. В промежутке между двумя последовательными значениями Х функция F (х) постоянна. При переходе аргумента х через значение хi F (х) скачком возрастает на величину p (Х = хi).
Рассмотрим p (х1 £ Х < х2). Если х2 > х1, то очевидно, что
p (Х < х2) = p (Х < х1) + p (х1 £ Х < х2).
Тогда
p (х1 £ Х < х2) = p (Х < х2) - p (Х < х1) = F (х2) - F (х1),
т.е. вероятность попадания случайной величины в интервал [ х1; х2) равен разности значений интегральной функции граничных точек.
Последнее условие можно использовать для нахождения вероятности p (Х = х1) для непрерывной случайной величины. Для этого рассмотрим предел
p (X = x1) = 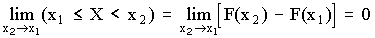 ,
,
т.е. если закон распределения случайной величины есть функция непрерывная, то вероятность того, что случайная величина примет заранее заданное значение, равна нулю.
Здесь видно различие между дискретными и непрерывными случайными величинами. Для дискретных случайных величин, для каждого значения случайной величины существует своя вероятность. И для него справедливо утверждение: событие, вероятность которого равна нулю, невозможно. Для непрерывной случайной величины это утверждение неверно. Как показано, вероятность того, что Х = х1 (где х1- заранее выбранное число) равна нулю, это событие не является невозможным.
Рассмотрим непрерывную случайную величину Х, интегральный закон которой предполагается непрерывным и дифференцируемым. Функцию
¦ (х) = F¢ (х)
называют дифференциальным законом распределения или плотностью вероятности случайной величины Х. Из определения производной можно записать
¦ (x) = F¢ (x) = 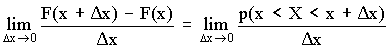 ,
,
т.е. плотность вероятности случайной величины Х в точке х равна пределу отношения вероятности попадания величины Х в интервал (х; х + Dх) к D х, когда D х стремится к нулю.
Используя понятия интегральной функции распределения и определенного интеграла можно записать
¦ (x) = F¢ (x) или F (x) = p (x1 < X < x2) = 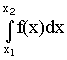 .
.
Это соотношение имеет простое геометрическое толкование (рис. 5).
Если определяет заштрихованную область в соответствующих пределах, то
p (х < Х < х + Dх)» ¦ (х) D х.
Из свойств интегрального распределения следует
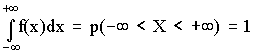 .
.
Зная дифференциальный закон распределения можно определить интегральный закон распределения
F (x) = 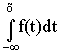 .
.
2.2. Числовые характеристики случайных величин, заданных своими распределениями
Основными характеристиками случайной величины, заданной своими распределениями, является математическое ожидание (или среднее значение) и дисперсия.
Математическое ожидание случайной величины является центром ее распределения. Дисперсия характеризует отклонение случайной величины от ее среднего значения.
Если Х дискретная случайная величина, значения хi которой принимают с вероятностью pi, так, что 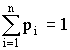 , то математическое ожидание М (Х) случайной величины Х определяется равенством
, то математическое ожидание М (Х) случайной величины Х определяется равенством
M (X) = 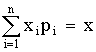 ,
,
т.е. суммой произведений всех ее возможных значений на соответствующие вероятности.
Математическим ожиданием непрерывной случайной величины является аналог его дискретного выражения
M (X) = 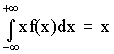 .
.
Действительно, все значения в интервале (х; х + Dх) можно считать примерно равными х, а вероятность таких значений равна ¦ (х) dx (см. ранее). Поэтому значения хi дискретного распределения заменяются х, а вероятности pi - на ¦ (х) dx, а сумма заменяется интегралом.
Дисперсией или рассеянием случайной величины Х называется математическое ожидание квадрата разности случайной величины и ее математического ожидания.
D (Х) = М [ Х - М (Х)] 2 = М (Х - х)2 = s 2 (х)
Если случайная величина Х дискретна и принимает значения хi с вероятностями pi, то случайная величина (Х - х)2 принимает значения (хi - х)2 с вероятностями Рi. Поэтому для дискретной случайной величины имеем
D (X) = 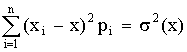
Аналогично для непрерывной случайной величины получаем
D (X) = 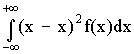 .
.
Чем меньше величина дисперсии, тем лучше значения случайной величины характеризуются ее математическим ожиданием.
2.3. Основные дискретные и непрерывные законы распределения
Как отмечалось ранее, очень часто случайная величина распределена по нормальному закону. Но существуют и другие распределения, имеющие практическое значение. Рассмотрим некоторые из них по условиям возникновения и основным параметрам их характеризующим.
1. Равномерное распределение вероятностей.
Пусть плотность вероятности А равна нулю всюду, кроме интервала (a; b), на котором она постоянна (рис. 6). Тогда можно записать
p (a < X < b) = 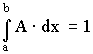
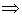 A =
A = 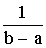 .
.
Тогда дифференциальный закон равномерного распределения определяется
¦ (x) = 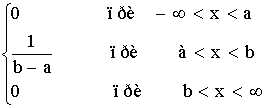
Интегральный закон распределения
F (x) = 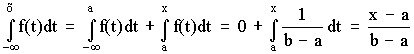 .
.
При х ³ b имеем
F (x) = 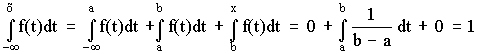
Таким образом интегральный закон равномерного распределения задается (рис. 6)
F (x) = 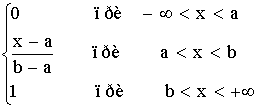
Основные характеристики распределения
М (X) = 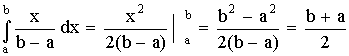 ;
;
D(X) = 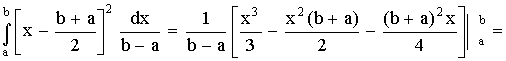
= 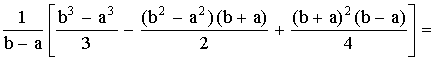
= 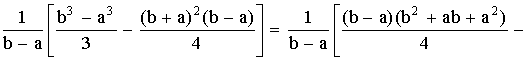
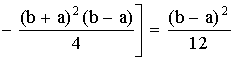 .
.
2. Биноминальное распределение
Пусть при некотором испытании событие А может наступить или не произойти (А). Обозначим вероятность А через р, а А через q= 1 -р (других итогов испытания нет). Тогда исходами двух последовательных независимых испытаний и их вероятностью будут:
АА - р2; АА - рq; АА - qр; АА - q2.
Отсюда видно, что двукратное появление события А равно р2, вероятность однократного появления - 2 рq, а вероятность того, что А не наступит ни разу - q2. Эти результаты единственно возможные и поэтому
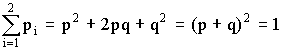 .
.
Это рассуждение можно перенести на любое число испытаний.
Например, при трех испытаниях получим
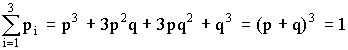 .
.
Подсчитаем вероятность того, что при n испытаниях событие А появится m раз. Это может произойти, например, в последовательности
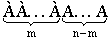
Ясно, что вероятность равна рmqn- m. Но m событий А может быть и в другом сочетании. Число всех возможных сочетаний из n элементов по m (количество событий А) равно числу сочетаний 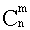 . Используя теорему сложения вероятностей получаем общую вероятность Рm,n наступления m событий А из n испытаний
. Используя теорему сложения вероятностей получаем общую вероятность Рm,n наступления m событий А из n испытаний
Pm,n = 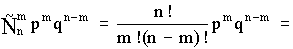
= 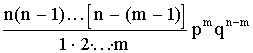 .
.
Из этой формулы видно, что вероятности Рm,n для различного исхода испытаний (появление или не появление определенного результата А) определяется
pn + npn-1q + 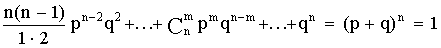 .
.
Коэффициенты перед вероятностями р, q являются биноминальными коэффициентами, а общая вероятность представляет слагаемые в разложении бинома (р + q)n. Поэтому закон распределения случайной величины Х, в котором вероятность наступления событий А определяется коэффициентами бинома, называется биноминальным распределением дискретной случайной величины. Этот закон может быть задан в виде таблицы 1.
Таблица 1
Биноминальный закон распределения
| хi | ... | m | ... | n | |||
| pi | qn | npqn-1 | 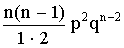
| ... | 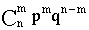
| ... | pn |
Биномиальные коэффициенты удобно получать с помощью треугольника Паскаля.
1 n = 0
1 1 n = 1
1 2 1 n = 2
1 3 3 1 n = 3
1 4 6 4 1 n = 4
1 5 10 10 5 1 n = 5
Все строки треугольника (начинающегося с единицы) начинаются и заканчиваются единицей. Промежуточные числа получаются сложением соседних чисел вышестоящей строки. Числа, стоящие в одной строке, являются биноминальными коэффициентами соответствующей степени.
Из описания биномиального распределения становится ясно, что область его действия там, где возможно многократное проведение испытаний с известной вероятностью.
Определим основные характеристики этого распределения.
Математическое ожидание
М (Х) = 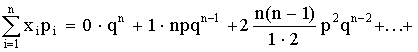
+ 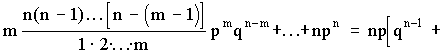
+ 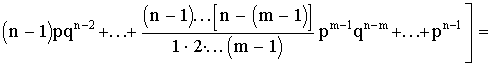
= np (q + p)n-1 = np.
Дисперсия распределения может быть определена из общего выражения
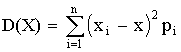 ,
,
но это приводит к громоздким вычислениям. В то же время случайная величина Х принимает в каждом опыте только два значения: 1, если событие А произошло и 0, если оно не произошло с вероятностями, соответственно, р или q. Тогда математическое ожидание одного опыта определится
М (Х1) = 0× q + 1×р = р = х
и соответственно дисперсия одного опыта
D (Х1) = (0 - р)2× q + (1 - р)2× р = р2q + q2р = рq (р + q) = рq.
Тогда дисперсия всех n опытов составит
D (X) = n× p× q.
3. Закон Пуассона
В случае малых р (или, наоборот, близких к 1) биноминальный закон распределения можно преобразовать следующим образом
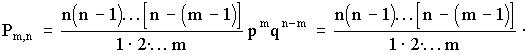
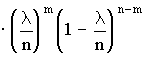 ,
,
где 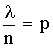 .
.
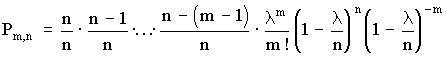
Определим предел Рm,n при n ® ¥ и постоянном m. Тогда пределы
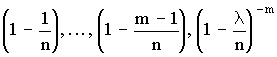 равны единице, а
равны единице, а 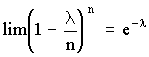 .
.
Окончательно имеем
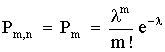 .
.
Это распределение называется законом Пуассона, где l - интенсивность распределения. Используется в задачах с редкими событиями.
Определим его основные характеристики и смысл величины l.
Запишем закон распределения в виде таблицы.
| хi | ... | m | ... | |||
| pi | e-l | 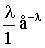
| 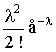
| ... | 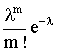
| ... |
M (X) = 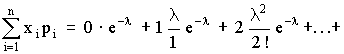
+ 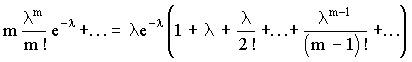 .
.
Выражение в скобках есть разложение функции еl в ряд Маклорена.
Поэтому
М (Х) = lе- l еl = l.
Не рассматривая вывод отметим, что
D (Х) = l,
т.е. дисперсия равна математическому ожиданию.
Рассмотренные виды распределений случайной величины, конечно, не исчерпывают всех существующих распределений. Можно назвать еще несколько: распределение Бернулли, экспоненциальное распределение, гамма - распределение, распределение Вейбула, гипергеометрические распределения и др. При определенных условиях и параметрах один вид распределения может переходить в другой. Поэтому при решении практических задач по законам распределения случайных величин следует обращаться к специальной литературе.
2.4. Понятие статистической гипотезы и статистического критерия
Статистической гипотезой называют любое утверждение о виде или свойствах распределения наблюдаемых в эксперименте случайных величин. Такие утверждения можно делать на основе теоретических соображений или статистических исследований других наблюдений. Например, при многократном измерении некоторой физической величины, точное значение Х которой не известно, но в процессе измерений оно меняется. На результат измерений влияют многие случайные факторы, поэтому результат i - го измерения можно записать в виде аi = Х + e i, где e i - случайная погрешность измерения. Если e i складывается из большого числа ошибок, каждая из которых не велика, то на основании центральной предельной теоремы можно предположить, что случайные величины аiимеют нормальное распределение. Такое предположение является статистической гипотезой о виде распределения наблюдаемой случайной величины.
Если для исследуемого явления сформулирована та или иная гипотеза (обычно ее называют основной или нулевой гипотезой и обозначают символом Но), то задача состоит в том, чтобы сформулировать правило, которое позволяло бы по результатам наблюдений принять или отклонить эту гипотезу. Правило, согласно которому проверяемая гипотеза Но принимается или отвергается, называется статистическим критерием проверки гипотезы Но.
Наиболее распространены такие статистические гипотезы, как:
а) вида распределения;
б) однородности нескольких серий независимых результатов;
в) случайности результатов эксперимента и т.п.
Статистический критерий проверки гипотезы Но служит для определения возможного отклонения от основной гипотезы. Характер отклонений может быть различным. Если критерий ² улавливает² любые отклонения от Но, то такой критерий называют универсальным или критерием согласия. Существуют критерии, которые выявляют отклонения от заданного вида, это узко направленные критерии.
Выбор правила проверки гипотезы Но эквивалентен заданию критической области х1, при попадании в которую переменной х гипотеза Но отвергается. Критерий, определяемый критической областью х1 называют критерием х1.
В процессе проверки гипотезы Но можно прийти к правильному решению или совершить ошибку первого рода - отклонить Нокогда она верна, или ошибку второго рода - принять Но, когда она ложна. Иными словами, ошибка первого рода имеет место, если точка х попадает в критическую область х1, в то время как верна нулевая гипотеза Но, а ошибка второго рода - когда х Î хо, но гипотеза Но ложна.
Желательно провести проверку гипотезы так, чтобы свести к минимуму вероятности обоих ошибок. Однако при данном числе испытаний n в общем случае невозможно одновременно обе эти вероятности сделать как угодно малыми. Поэтому наиболее рационально выбирать критическую область следующим образом: при заданном числе испытаний n устанавливается граница для вероятности ошибки первого рода и при этом выбирается та критическая область х1, для которой вероятность ошибки второго рода минимальна.
2.5. Вероятности ошибок первого и второго рода
Рассмотрим станок, который может работать только в одном из двух состояний. Если он работает в налаженном режиме, то для интересующего нас признака качества, например, длины или диаметра заготовки, имеет место нормальное распределение при работе как в налаженном так и в разлаженном режиме. Оба режима отличаются только уровнем настройки процесса по математическому ожиданию (М(х) = 10 и 11, соответственно в налаженном и разлаженном режиме), в то время как дисперсии в обоих случаях составляют s 2 = 4.
Проверить нужно нулевую гипотезу, в соответствии с которой М(х) = 10, против альтернативы (в данном случае единственной) М(х) = 11. Конкурирующую гипотезу обозначим Н1. Тогда Но: М(х) = 10; Н1: М(х) = 11.
Необходимо по результатам выборки определить в каком из состояний работает станок. Примем объем выборки n из потенциально бесконечной генеральной совокупности. В качестве контрольной величины возьмем выборочное среднее Хn. На рис. 9 изображены плотности распределения Хn для n = 25 и n = 4.
Для формулировки критерия необходимо разделить область изменения контрольной величины (х) на критическую область отклонения гипотезы Но (принятия Н1) и область принятия гипотезы Но. Для этого необходимо выбрать число К, такое, что 10 < К < 11, и интервал (- ¥; К ] рассматривать как область принятия гипотезы Но, а интервал [ К; ¥) - как область отклонения гипотезы Но. По рис. 9 видно, что каждая реализация Х25 или Х4 возможна при верности любой из двух гипотез, но с различной вероятностью.
рода a (отклонения верной гипотезы Но) и второго рода b (принятие гипотезы Но, когда она не верна). Также видно, что увеличение n ведет к уменьшению дисперсии распределения х и тем самым - к одновременному уменьшению вероятностей a и b. В соответствии с рис. 9 можно записать:
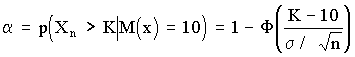 ;
;
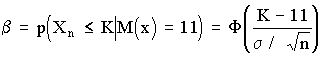 .
.
Эти два уравнения содержат четыре величины a, b, К, n. Задав две из четырех величин, можно определить две другие.
Например, при n = 25 и К = 10,4 определим:
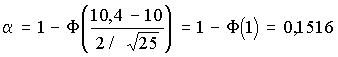 ;
;
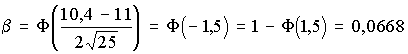 .
.
Если задаться величинами a и b, то можно определить величины К, n.
2.6. Проверка гипотезы вида закона распределения вероятностей
При проверке эксперимента закон распределения вероятностей случайных величин неизвестен и можно лишь предположительно судить о его виде. Выборочные оценки параметров распределения несут в себе случайные ошибки, искажающие истинный характер распределения. Поэтому после получения эмпирического распределения производится подбор теоретического закона распределения, пригодного для описания вероятностных свойств изучаемой случайной величины. Критерии подбора (проверки гипотезы соответствия) называют в статистике критериями согласия. Все они основаны на выборе допустимой меры расхождения между теоретическим распределением и выборочными данными.
Общую процедуру проверки гипотезы закона распределения можно представить в следующей последовательности:
1. По опытным данным строится эмпирическая кривая распределения вероятностей;
2. Определяются параметры эмпирического распределения (в соответствии с его видом);
3. Выдвигается одна или несколько гипотез о функции плотности исследуемой случайной величины, исходя из внешнего вида эмпирической кривой, значений ее параметров, технических факторов, влияющих на ее вид;
4. Эмпирическая кривая выравнивается по одной или нескольким теоретическим кривым;
5. Проводится сравнение по одному или нескольким критериям согласия;
6. Выбирается теоретическая функция, дающая наилучшее согласование.
Поясним п. 4; 5. Определив по эмпирическим данным параметры распределения, подставляют их в теоретическую кривую закона распределения и рассчитывают вероятность середин интервалов эмпирического распределения. Умножив значение полученной вероятности на общее число опытов, получают теоретическое значение частот случайной величины, которые и определяют² выровненную² кривую. Теперь можно найти вероятность того, что эмпирическая кривая соответствует выбранной теоретической, выбрав вероятность согласия (уровень значимости). Если результат расхождения не выйдет за принятый уровень значимости, то считают, что эмпирическое распределение согласуется с теоретическим. Если сравнение осуществляется с несколькими теоретическими законами, то окончательно принимать тот, который дает лучшее соответствие.
Чаще всего в качестве критериев согласия принимают критерий Пирсона (c 2) и критерий Колмогорова - Смирнова (К - С -критерий).
Критерий c 2 является наиболее состоятельным при большом числе наблюдений. Он почти всегда опровергает неверную гипотезу, обеспечивает минимальную ошибку в принятии неверной гипотезы по сравнению
с другими критериями.
c 2 = 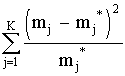 ,
,
где mj - наблюдаемая частота случайного события;
m* j - ожидаемая по принятому теоретическому закону распределения;
К - число интервалов случайной величины.
Затем определяется число степеней свободы l:
l = К - r - 1;
где К - число интервалов случайной величины;
r - число параметров теоретической функции распределения.
К - С - критерий лучше всего использовать в случае, если теоретические значения параметров распределения известны. При неизвестных параметрах его можно использовать, но он дает несколько завышенные результаты. При использовании этого критерия определяется величина
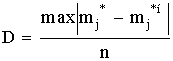 ,
,
где
mнj, m*нj - соответственно, накопленные наблюдаемые и ожидаемые
(теоретические) частоты;
n - число проведенных опытов.
То есть, в данном случае оценивается только максимальное отклонение накопленной частоты случайного события, возникающее в одном из диапазонов изменения случайной величины. Полученное значение коэффициента сравнивается с табличным для числа степеней свободы опыта и принятого уровня значимости результата. Если табличное значение коэффициента больше, то гипотеза о принятом законе распределения не отвергается.
Контрольные вопросы
1. Сущность непрерывной и дискретной случайной величины;
2. Сущность интегрального закона распределения случайной величины;
3. Сущность дифференциального закона распределения случайной величины;
4. Связь интегрального и дифференциального законов распределения;
5. Основные характеристики случайной величины, заданной своим распределением;
6. Назовите примеры законов распределения непрерывной и дискретной случайной величины;
7. Понятие статистической гипотезы и статистического критерия;
8. Назовите примеры статистических гипотез;
9. Сущность ошибок первого и второго рода;
10. Сущность проверки гипотезы вида закона распределения;
11. Принципиальное различие в критериях Пирсона и Колмогорова - Смирнова.
|
|
|
|
|
Дата добавления: 2014-12-16; Просмотров: 2686; Нарушение авторских прав?; Мы поможем в написании вашей работы!