КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование аудио потока с потерей качества
|
|
|
|
Существование порога слышимости дает основу для построения методов сжатия звука с потерями. Можно удалять все сэмплы, величина которых лежит ниже этого порога. Поскольку порог слышимости зависит от частоты, кодер должен знать спектр сжимаемого звука в каждый момент времени. Для этого нужно хранить несколько предыдущих входных сэмплов. При вводе следующего сэмпла необходимо на первом шаге сделать преобразование 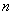 сэмплов в частотную область. Результатом служит вектор, состоящий из
сэмплов в частотную область. Результатом служит вектор, состоящий из 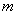 числовых компонент, которые называются сигналами. Он определяет частотное разложение сигнала. Если сигнал для частоты
числовых компонент, которые называются сигналами. Он определяет частотное разложение сигнала. Если сигнал для частоты 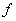 меньше порога слышимости этой частоты, то его следует отбросить.
меньше порога слышимости этой частоты, то его следует отбросить.
Кроме того, для эффективного сжатия звука применяются еще два свойства органов слуха человека. Эти свойства называются частотное маскирование и временное маскирование.
Частотное маскирование (его еще называют слуховое маскирование) происходит тогда, когда нормально слышимый звук накрывается другим громким звуком с близкой частотой. Стрелка на рисунке обозначает громкий источник звука с частотой 800 Гц. Этот звук приподнимает порог слышимости в своей окрестности (пунктирная линия). В результате звук, обозначенный тоненькой стрелкой в точке «х» и имеющий нормальную громкость выше своего порога чувствительности, становится неслышимым; он маскируется более громким звуком. Хороший метод сжатия звука должен использовать это свойство слуха и удалять сигналы, соответствующие звуку «х», поскольку они все равно не будут услышаны человеком. Это один возможный путь сжатия с потерями.
Частотное маскирование зависит от частоты сигнала. Оно варьируется от 100 Гц для низких слышимых частот до более, чем 4 кГц высоких частот. Следовательно, область слышимых частот можно разделить на несколько критических полос, которые обозначают падение чувствительности уха (не путать со снижением мощности разрешения) для более высоких частот.
Можно считать критические полосы еще одной характеристикой звука, подобной его частоте. Однако, в отличие от частоты, которая абсолютна и не зависит от органов слуха, критические полосы определяются в соответствии со слуховым восприятием. В итоге они образуют некоторые меры восприятия частот. Ниже перечислены 27 приближенных критических полос.
| полоса | область | полоса | область | полоса | область |
| 0-50 | 800-940 | 3280-3840 | |||
| 50-95 | 940-1125 | 3840-4690 | |||
| 95-140 | 1125-1265 | 4690-5440 | |||
| 140-235 | 1265-1500 | 5440-6375 | |||
| 235-330 | 1500-1735 | 6375-7690 | |||
| 330-420 | 1735-1970 | 7690-9375 | |||
| 420-560 | 1970-2340 | 9375-11625 | |||
| 560-660 | 2340-2720 | 11625-15375 | |||
| 660-800 | 2720-3280 | 15375-20250 |
Критические полосы можно описать следующим образом: из-за ограниченности слухового восприятия звуковых частот порог слышимости частоты приподнимается соседним звуком, если звук находится в критической полосе . Это свойство открывает путь для разработки практического алгоритма сжатия аудиоданных с потерями. Звук необходимо преобразовать в частотную область, а получившиеся величины (частотный спектр) следует разделить на подполосы, которые максимально приближают критические полосы. Если это сделано, то сигналы каждой из подполос нужно квантовать так, что шум квантования был неслышимым.
Еще один возможный взгляд на концепцию критической полосы состоит в том, что органы слуха человека можно представить себе как своего рода фильтр, который пропускает только частоты из некоторой области (полосы пропускания) от 20 до 20000 Гц. В качестве модели ухо- мозг мы рассматриваем некоторое семейство фильтров, каждый из которых имеет свою полосу пропускания. Эти полосы называются критическими. Они пересекаются и имеют разную ширину. Они достаточно узки (около 100 Гц) в низкочастотной области и расширяются (до 4 - 5 кГц) в области высоких частот.
Ширина критической полосы называется ее размером. Для измерения этой величины вводится новая единица «барк» («Bark» от H.G.Barkhausen). Один барк равен ширине (в герцах) одной критической полосы. Эта единица определяется по формуле
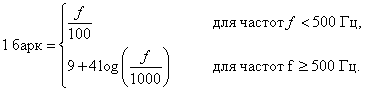
Несколько критических полос с величиной барк от 14 до 25 единиц, которые помещены над кривой порогов слышимости.
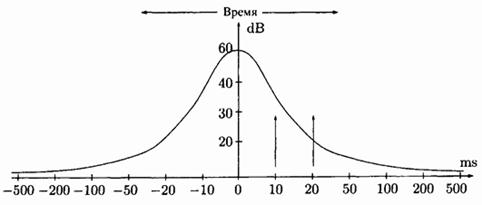
Временное маскирование происходит, когда громкому звуку 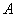 частоты по времени предшествует или за ним следует более слабый звук
частоты по времени предшествует или за ним следует более слабый звук  близкой частоты. Если интервал времени между этими звуками не велик, то звук будет не слышен. Порог временного маскирования от громкого звука в момент времени 0 идет вверх сначала круто, а потом полого. Более слабый звук в 30 дБ не будет слышен, если он раздастся за 10 мсек до или после громкого звука, но будет различим, если временной интервал между ними будет больше 20 мсек.
близкой частоты. Если интервал времени между этими звуками не велик, то звук будет не слышен. Порог временного маскирования от громкого звука в момент времени 0 идет вверх сначала круто, а потом полого. Более слабый звук в 30 дБ не будет слышен, если он раздастся за 10 мсек до или после громкого звука, но будет различим, если временной интервал между ними будет больше 20 мсек.
Стандарт MPEG-1 сжатия видеофильмов состоит из двух основных частей: сжатия видео и сжатия звука. В этом параграфе обсуждается принципы компрессии звука в MPEG-1, а именно, его третий слой, который широко известен по аббревиатуре МР3. Мы советуем читателям обязательно прочитать первую часть этой главы перед тем, как пытаться освоить этот материал.
Формальное имя стандарта MPEG-1 - international standard for moving picture video compression IS 11172 (международный стандарт для сжатия движущихся изображений). Он состоит из 5 частей, среди которых часть 3 определяет алгоритм сжатия звука. Как любой стандарт, выработанный ITU или ISO, документ, описывающий MPEG-1, имеет нормативный и описательный разделы. Нормативный раздел содержит спецификации стандарта. Он написан строгим языком для тех, кто будем создавать программные реализации метода для конкретных машинных платформ. Описательный раздел иллюстрирует выбранные концепции, объясняет причины выбора того или иного подхода, содержит необходимые базовые сведения.
Примером нормативного раздела являются таблицы с различными параметрами и с кодами Хаффмана, которые используются в стандарте MPEG. А примером описательного раздела служит алгоритм, задающий психоаккустическую модель. MPEG не дает конкретного алгоритма, и кодер MPEG свободен в выборе метода реализации модели. В этом параграфе просто рассматриваются некоторые возможные альтернативы.
Аудиостандарт MPEG-1 описывает три метода сжатия, называемые слоями (layer), которые обозначаются римскими числами I, II и III. Все три слоя входят в стандарт MPEG-1, но здесь будет описан только слой III. При сжатии видеофильмов используется только один слой, который обозначается в заголовке сжатого файла. Любой из этих слоев можно независимо использовать для сжатия звука без видео. Функциональные модули младших слоев могут быть использованы старшими слоями, но более высокие слои используют дополнительные возможности для лучшего сжатия. Интересной особенностью слоев является их иерархическая структура, то есть, декодер слоя III может декодировать файлы сжатые слоями I и II.
Результатом разработки трех слоев было возрастание популярности слоя III. Кодер этого метода очень сложен, но он производит замечательную компрессию, это обстоятельство в сочетании с тем, что декодер существенно проще кодера, породило небывалый взрыв популярности звуковых файлов, которые называются МР3-файлами. Очень легко добыть декодер слоя III, с помощью которого можно прослушивать записи формата МР3, которые в огромном количестве находятся во всемирной паутине. Это был настоящий триумф аудиочасти проекта MPEG.
Аудиостандарт MPEG начинается нормативным описанием формата сжатого файла для каждого из трех слоев. Затем следует нормативное описание декодера. Описание кодера (оно разное для всех слоев), а также двух психоакустических моделей содержится в описательном разделе; любой кодер, способный сгенерировать корректно сжатый файл, может считаться допустимым кодером MPEG. Имеется также несколько приложений, в которых обсуждаются смежные вопросы, например, защита от ошибок.
При оцифровывании видеофильмов звуковая часть может состоять из двух звуковых дорожек (стереозвук), каждая из которых сэмплирована при 44.1 кГц с 16-битными звуковыми фрагментами. Это приводит к битовой скорости аудиоданных 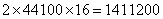 бит/сек, близкой к 1.5 Мбит/сек. Кроме скорости сэмплирования в 44.1 кГц предусмотрены скорости 32 кГц и 48 кГц. Важным свойством MPEG аудио является возможность задания пользователем коэффициента сжатия. Стандарт позволяет получить битовую скорость сжатого звукового файла в диапазоне от 32 до 224 Кбит/сек на один аудиоканал (их обычно два для стереозвука). В зависимости от исходной частоты сэмплирования, эти битовые скорости означают фактор сжатия от 2.7 (низкий) до 24 (впечатляющий)! Причина жесткой заданности битовой скорости сжатого файла связана с необходимостью синхронизации звука и сжатого видеоряда.
бит/сек, близкой к 1.5 Мбит/сек. Кроме скорости сэмплирования в 44.1 кГц предусмотрены скорости 32 кГц и 48 кГц. Важным свойством MPEG аудио является возможность задания пользователем коэффициента сжатия. Стандарт позволяет получить битовую скорость сжатого звукового файла в диапазоне от 32 до 224 Кбит/сек на один аудиоканал (их обычно два для стереозвука). В зависимости от исходной частоты сэмплирования, эти битовые скорости означают фактор сжатия от 2.7 (низкий) до 24 (впечатляющий)! Причина жесткой заданности битовой скорости сжатого файла связана с необходимостью синхронизации звука и сжатого видеоряда.
В основе сжатия звука в MPEG лежит принцип квантования. Однако, квантуемые величины берутся не из звуковых сэмплов, а из чисел (называемых сигналами) которые выделяются из частотной области звука (это обсуждается в следующем абзаце). Тот факт, что коэффициент сжатия (или битовая скорость) известен кодеру означает, что кодер в каждый момент времени знает, сколько бит можно назначить квантуемому сигналу. Следовательно важной частью кодера является (адаптивный) алгоритм назначения битов. Этот алгоритм использует известную битовую скорость и частотный спектр самых последних аудиосэмплов для определения размера квантованного сигнала так, чтобы шум квантования (разность между исходным сигналом и его квантованным образом) была неслышимой.
Психоакустические модели используют частоту сжимаемого звука, но входной файл содержит звуковые сэмплы, а не звуковые частоты. Эти частоты необходимо вычислить с помощью сэмплов. По этой причине первым шагом аудиокодера MPEG является дискретное преобразование Фурье, при котором 512 последовательных звуковых сэмплов преобразуется в частотную область. Поскольку количество частот может быть большим, их группируют в 32 подполосы одинаковой ширины. Для каждой подполосы вычисляется число, которое указывает на интенсивность звука в данной подполосе. Эти числа, называемые сигналами, затем квантуются. Грубость квантования на каждой подполосе определяется с помощью порога маскирования этой подполосы, а также с помощью числа оставшихся для кодирования битов. Порог маскирования для каждой подполосы вычисляется с помощью психоакустической модели.
MPEG использует две психоакустические модели для частотного и временного маскирования. Каждая модель описывает, как громкий звук маскирует другие звуки, которые близки к этому звуку по частоте или по времени. Модель разделяет область частот на 24 критические полосы и определяет, как эффекты маскирования проявляются в каждой из полос. Эффект маскирования, конечно, зависит от частот и амплитуд тонов. Когда звук разжимается и воспроизводится, пользователь (слушатель) может выбрать любую амплитуду звучания, поэтому психоакустическая модель должна быть разработана для наихудшего случая. Эффекты маскирования также зависят от природы источника сжимаемого звука. Источник может быть музыкальноподобным или шумоподобным. Две психоакустические модели основаны на результатах экспериментальной работе исследователей за многие годы.
Декодер должен быть быстрым, поскольку ему, возможно, предстоит декодировать видео и аудио в режиме реального времени. Поэтому он должен быть простым. Значит, у него нет времени использовать психоакустическую модель или алгоритм назначения битов. То есть, сжатый файл должен содержать исчерпывающую информацию, которую декодер будет использовать при деквантовании сигналов. Эта информация (размер квантованных сигналов) должна быть записана кодером в сжатый файл и она требует некоторое дополнительные расходы, которые будут удовлетворены за счет оставшихся битов.
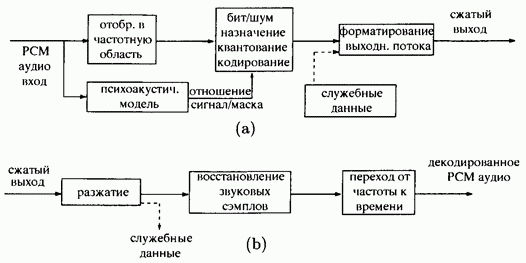
Ниже приведена блок-схема основных компонентов кодера и декодера звука в MPEG. Вспомогательные данные определяются пользователем; обычно они связаны с конкретными приложениями. Эти данные не являются обязательными.
|
|
|
|
|
Дата добавления: 2014-12-16; Просмотров: 632; Нарушение авторских прав?; Мы поможем в написании вашей работы!