КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Процессы понимания и кодирования
|
|
|
|
Ло
Процессы понимания и кодирования
Взаимосвязь абстрактного категориального знания и процессов восприя-
тия стала активно обсуждаться начиная с 1970-х годов. В центре внимания
оказались два вопроса: «Почему мы знаем, что роза — это роза?», «Когда
мы знаем, что роза — это роза?». Гипотетическая роза до сих пор является
излюбленным примером в данной области исследований. Первый из этих
вопросов касается выделения значимых признаков для принятия семанти-
ческого решения, второй — характера и временных этапов процесса семан-
тической обработки. В результате многочисленных исследований был вы-
делен ряд феноменов и предложены несколько объяснительных конструк-
тов. В частности, было показано, что быстрота понимания слова зависит
от его частотности, а также от привычности формы и условий предъявле-
ния (см.[Величковский, 1982]).
Исследование процессов понимания традиционно связывалось с фено-
меном контекста: буква быстрее воспринимается в слове, значение слова
легче вычленяется в предложении, смысл которого заключен в тексте. Если
появляется стимул, противоречащий контексту, возникает ситуация семан-
тического рассогласования. Феномен контекста — один из наиболее устой-
чивых феноменов в области исследований семантических процессов [Кап-
теленин, 1983]. Это свидетельствует о том, что в данном случае затрагива-
ются фундаментальные характеристики психических процессов, таких как
информационное предвосхищение и цикличность когнитивной обработ-
ки. Собственно процесс категоризации можно рассматривать как включе-
ние стимула во внутренний контекст.
Для изучения феномена контекста используется несколько эксперимен-
тальных схем. Основным методическим приемом является сравнивание
выполнения задачи при изолированном предъявлении стимульного мате-
риала и при предъявлении его в том или ином контексте. В эксперимен-
тах с семантической преднастройкой перед стимулом предъявляется неко-
торое слово, которое связано или, наоборот, не связано по смыслу с тес-
товым. Если два слова ассоциативно связаны друг с другом, то время ре-
акции в задачах «лексического решения»* уменьшается.
На основании многочисленных экспериментальных данных можно
сформулировать несколько эффектов семантической преднастройки.
• Слово, предъявленное в смысловом контексте, воспринимается быстрее.
• Семантическая преднастройка не только облегчает смысловой анализ
слова, но и затрудняет анализ других его характеристик (например,
цвет букв).
• Ложная смысловая преднастройка увеличивает время реакции в зада-
чах называния слов и лексического решения.
В работах Дж. Нили показу тестовой последовательности предшество-
вало предъявление с различной асинхронностью слова, которое в 80% слу-
чаев было названием соответствующей стимулу категории (например «пти-
ца» предваряла появление слова «дятел»), а в 20% могло обозначать дру-
гую категорию (например, «мебель»). Результаты показали, что адекватная
преднастройка уменьшала время реакции [Neely, 1991].
В экспериментах К.Конрад [Conrad, 1978] испытуемым предъявляли
предложения, которые оканчивались многозначным словом. Контекст
предложения строго предписывал восприятие лишь одного значения (на-
пример, слово «ключ» в предложении «на столе лежал ключ»). Вслед за этим
предъявлялось напечатанное в цвете слово и требовалось назвать цвет букв.
Если слово было ассоциативно связано с предшествующим многозначным
словом, то цвет букв назывался медленнее. Это происходило при предъяв-
лении слов, ассоциативно связанных с каждым из значений многозначного
слова (например, медленнее назывались цвета слов «замок» и «ручей», если
речь шла о «ключе»). В ходе других экспериментов требовалось просто на-
звать второе слово или решить, что было предъявлено: слово или бессмыс-
сленное словосочетание. При этом если тестовое слово было связано по
смыслу с любым из значений многозначного слова, то время узнавания и
называния слова уменьшалось. Приведенные данные свидетельствуют о
том, что при перцептивном узнавании слова активизируются все его смыс-
ловые поля (см. дополн. [Каптеленин, 1983]).
' В таких задачах надо решить, явялется ли предъявленный стимул словом.
Глава 7. Семантика и процессы порождения речи
Модели ранней семантической обработки
Ранняя перцептивная и семантическая обработка обозначается в англий-
ском языке термином «priming». В русском нет эквивалента этому слову,
поскольку, с одной стороны, оно означает подготовительный этап полу-
чения информации о чем-нибудь, а с другой — придает оттенок типично-
сти выбираемого материала и, одновременно, активности и успешности
процесса. Одни феномены, обозначаемые этим понятием, можно назвать
преднастройкой, другие — ранней когнитивной обработкой, которая в за-
висимости от теоретической интерпретации представляется как раннее за-
печатление или микрогенез зрительного образа.
А. Модель ранней семантической памяти. Э. Тульвинг и С. Шехтер опреде-
лили «priming», или ранние когнитивные процессы, как «неосознаваемую
форму человеческой памяти, которая имеет отношение к перцептивной
идентификации слов и объектов» [Tulving, Schacter, 1990, с. 301]. Однако
констатация этого факта еще не вскрывает механизмов, стояших за этим фе-
номеном. В эксперименте Уолтса [Wolts, 1996] была предпринята попытка
разделить перцептивную и семантическую преднастройку. Эффекты перцеп-
тивной обработки (или физических характеристик стимулов) были миними-
зированы (на этапе тестирования менялась модальность предъявления ма-
териала). В качестве преднастройки предъявлялась задача семантического
сравнения: испытуемые должны были решить, являются ли два слова сино-
нимами или они не связаны друг с другом. Затем давался тест на узнавание.
Если бы эффекты преднастройки были связаны только с фиксацией в се-
мантической памяти, то синонимы должны были узнаваться лучше, по-
скольку при их обработке приходилось бы обращаться дважды к одному и
тому же значению. Результаты показали, что эффект синонимов оказался
незначимым. Они узнавались столь же успешно, как и несвязные по смыс-
лу слова. Был сделан вывод о том, что для последующего кодирования ва-
жен был сам процесс сравнения стимулов, а не обращения к семантической
памяти. Концептуальная преднастройка скорее включает в действие проце-
дурные формы памяти, кодирующие процессы сравнения стимулов, чем от-
крывает доступ к ее устойчивым формам на стимульные слова.
Б. Модель последовательной переработки. В когнитивной психологии до сих
пор превалируют представления о последовательной, поэтапной, побло-
ковой обработке информации. В данных моделях собственно семантиче-
ская обработка является лишь этапом когнитивной обработки. Предпола-
гается, что он следует за этапом перцептивной обработки, под которым
понимается анализ таких характеристик, как цвет, общая форма, располо-
жение деталей и т.д. В настоящее время эта точка зрения находит подтвер-
ждение в нейрофизиологических исследованиях. В частности, при анали-
зе компонентов вызванных событиями потенциалов выделяются компо-
ненты ранние (латентный период 80—120 мс), которые меняются при из-
менении перцептивных характеристик стимулов, и поздние (латентный
Процессы понимания и кодирования
период 300—400 мс), которые меняются при изменении частоты употреб-
ления (частности) слов или рассогласовании семантических контекстов.
Например, в одной из работ [Young, 1989] регистрировались вызванные
потенциалы (ВП) на слова предъявляемые в случайном порядке. Стиму-
лами служили названия цветов, которые различались по трем параметрам:
длина слов (например, «белый» короче «фиолетового»), частота употреб-
ления (например, «зеленый» употребляется чаще «салатового») и семанти-
ческое сходство (например, «красный» близок к «оранжевому» и оба они
далеки от «голубого»). Семантическая близость предъявляемых стимулов
оценивалась в дополнительном исследовании с помощью методики мно-
гомерного шкалирования. Были получены следующие результаты: измене-
ния параметров ВП в течении 250 мс после предъявления стимулов связа-
но с изменением длины слова. Напротив, параметры ВП в диапазоне 400—
800 мс связаны с частотными и семантическими параметрами стимулов. На
этом основании делается вывод, что существуют два этапа обработки зри-
тельного вербального материала: на первом анализируется физические па-
раметры стимулов, а на втором — их семантические характеристики.
Сделанный вывод вызывает большие сомнения, поскольку существует
множество фактов, подтверждающих, что семантическая обработка проис-
ходит уже на самых ранних этапах восприятия. Д.Виккенс [Wickens, 1972] в
своем исследовании предъявлял слова на очень короткий временной интер-
вал (80—100 мс), недостаточный для их идентификации. Однако испытуе-
мые были способны устойчиво оценивать возможное значение слова с по-
мощью метода семантического дифференциала. Б.М. Величковский, В.В.
Похилько, и А.Г. Шмелев предъявляли слова с последующей маскировкой.
Она достигалась движением слова в горизонтальном направлении с угловой
скоростью 80 оборотов в секунду, что приводило к полному «смазыванию»
образа слова. Несмотря на это, испытуемые не только классифицировали
различные по значению слова, но и устойчиво соотносили в варианте ассо-
циативного эксперимента предъявляемое (но невоспринимаемое) слово «ве-
тер» со словом «буран», а не «вечер» (см. [Величковский, 1982]). В недавних
работах эти данные также неоднократно подтверждались. Было показано что
частотность слов [Polich, Donchin, 1989] и смысловой контекст [Neely, 1991;
Wolts, 1996] влияют на их восприятие на очень ранних этапах (до 250 мс).
В. Модель параллельной переработки. Многие современные авторы придер-
живаются представлений о параллельной переработке перцептивных (фи-
зических) и семантических признаков стимула. С. Косслин в одной из пос-
ледних работ [Kosslyn et al., 1995] выдвинул предположение о существова-
нии двух типов кодирования, которые практически не пересекаются друг
с другом. Это — кодирование категориальных пространственных отноше-
ний, которые связаны с относительными позициями в эквивалентном клас-
се и используются в процессе узнавания и идентификации, и кодирование
координатных пространственных отношений, которые определяют точные
метрические дистанции и используются для регуляции движений.
Согласно более традиционному подходу, определенный этап в анализе
Глава 7. Семантика и процессы порождения речи
физических характеристик связан с конкретным этапом в анализе семан-
тических характеристик. Кроме того, некоторые физические характерис-
тики стимула ограничивают область поиска в семантической памяти.
Д. Бродбент и М. Бродбент [Broadbent, Broadbent, 1980] предложили
оригинальную методику, позволившую «разделить» общие и детальные ха-
рактеристики слов. В одной ситуации с помощью оптической фильтрации
нарушались детальные характеристики слов (как при дефокусировке), но
сохранялись глобальные характеристики. В другой ситуации, наоборот,
нарушался обший вид слова, поскольку из него вырезались фрагменты
букв, и сохранялось большинство деталей. В качестве материала исполь-
зовали слова разной частотности и разного эмоционального значения; кро-
ме того, слова либо включались в контекст предложения, либо предъявля-
лись изолированно. Было продемонстрировано, что на узнавание слов с
сохранными глобальными очертаниями влияет только частотность слова
(частота встречаемости и опыт восприятия). При нарушении глобальных
очертаний, но сохранении деталей значимыми оказались включенность в
контекст и коннотативное значение. Был сделан вывод, что глобальные
очертания слова, которые анализируются на более ранних этапах микро-
генеза зрительного образа, связаны с частотой употребления, а детальные
характеристики, которые анализируются на более поздних этапах, связа-
ны с коннотативным и ассоциативным значениями слова.
Однако более поздние данные показывают, что такое разделение слиш-
ком упрощенно. Действительно, существует два этапа анализа семантиче-
ской информации.
Первый — продолжительностью 250—350 мс; в этот промежуток време-
ни слово-стимул активирует широкий спектр ассоциативных связей. Если
адекватный контекст помогает выявлению значимых семантических при-
знаков, то неадекватная преднастройка не препятствует семантическому
поиску. Осуществлению семантической обработки в этот период способ-
ствует сохранение привычных условий предъявления (например, привыч-
ный шрифт) и частота повторения комбинации признаков.
Второй этап начинается после 300—400 мс. Слово-стимул жестко связы-
вается с локальным значением, которое диктует контекст. Адекватный кон-
текст (преднастройка) приводит к положительному эффекту в семантичес-
кой переработке информации, а ложная преднастройка оказывает отрица-
тельное влияние. При этом и называние слов, и принятие лексического ре-
шения происходят медленнее [Swinney, 1979]. Осуществлению семантичес-
кого анализа помогает сохранение детальных характеристик образа слова,
меньшее значение имеет частотность. Субъект создает гипотезы, которые
проверяет на ограниченном объеме данных [Величковский, 1982].
Г, Модель встречной переработки. Начиная с середины 1970-х годов в ког-
нитивной психологии четко оформляется идея существования двух встреч-
ных процессов обработки информации. Процессы первого рода иницииру-
ются входной стимуляцией и продолжаются, как бы поднимаясь снизу вверх
по уровням все более тонкого анализа вплоть до полной идентификации сти-
| Процессы понимания и кодирования |
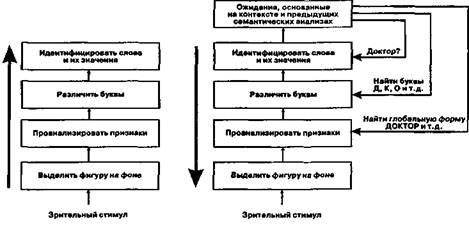
Рис. 7. /. Два возможных способа переработки слова «доктор» в контексте предложения «па-
циента обследовал доктор», описанные М. Уэссслсом |Wessels, 1982].
мулов. Процессы второго рода управляются знаниями и ожиданиями чело-
века, которые уточняются благодаря анализу контекста поступающей ин-
формации. Этот вид переработки получил название «сверху вниз» или «кон-
цептуально-ведомый». Переработкой сверху вниз объясняют предметность,
значение перцептивного образа и эффекты установки испытуемого. Обыч-
но оба вида процессов происходят одновременно и согласованно, но в за-
висимости от типа задачи и индивидуальных особенностей субъекта их вклад
может быть различен. М. Уэсселс [Wessells, 1982] приводит пример такой
встречной переработки на основе идентификации слова «доктор» (рис. 7.1).
|
|
|
|
|
Дата добавления: 2014-11-29; Просмотров: 694; Нарушение авторских прав?; Мы поможем в написании вашей работы!